Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
KI-Agents transformieren, wie Anwendungen mit Daten interagieren, indem sie große Sprachmodelle (LLMs) mit externen Tools und Datenbanken kombinieren. Agents ermöglichen die Automatisierung komplexer Workflows, verbessern die Genauigkeit des Abrufens von Informationen und erleichtern Die Verwendung natürlicher Sprachschnittstellen zu Datenbanken.
In diesem Artikel wird beschrieben, wie Intelligente KI-Agents erstellt werden, die Ihre Daten in der Azure-Datenbank für PostgreSQL durchsuchen und analysieren können. Die Einrichtung, die Implementierung und Tests werden mithilfe einer assistierenden Person für juristische Recherchen als Beispiel durchlaufen.
Was sind KI-Agents?
KI-Agents gehen über einfache Chatbots hinaus, indem SIE LLMs mit externen Tools und Datenbanken kombinieren. Im Gegensatz zu eigenständigen LLMs oder standardmäßigen Systemen zur informationsunterstützten Generierung (RAG) können KI-Agenten:
- Plan: Aufteilen komplexer Aufgaben in kleinere, sequenzielle Schritte.
- Verwenden Sie Tools: Verwenden Sie APIs, Codeausführung und Suchsysteme, um Informationen zu sammeln oder Aktionen auszuführen.
- Wahrnehmung: Verstehen und Verarbeiten von Eingaben aus verschiedenen Datenquellen.
- Denken Sie daran: Speichern und Zurückrufen vorheriger Interaktionen für eine bessere Entscheidungsfindung.
Durch die Verbindung von KI-Agents mit Datenbanken wie Azure Database for PostgreSQL können Agents präzisere, kontextbezogene Antworten basierend auf Ihren Daten bereitstellen. KI-Agenten gehen über einfache zwischenmenschliche Kommunikation hinaus und führen Aufgaben basierend auf natürlicher Sprache aus. Diese Aufgaben erfordern traditionell programmierte Logik. Agents können jedoch die für die Ausführung erforderlichen Aufgaben basierend auf dem vom Benutzer bereitgestellten Kontext planen.
Implementierung von KI-Agents
Die Implementierung von KI-Agents mit Azure Database for PostgreSQL umfasst die Integration erweiterter KI-Funktionen mit robusten Datenbankfunktionen, um intelligente, kontextabhängige Systeme zu erstellen. Mithilfe von Tools wie Vektorsuche, Einbettungen und Azure AI Foundry Agent Service können Entwickler Agents erstellen, die Abfragen natürlicher Sprachen verstehen, relevante Daten abrufen und umsetzbare Erkenntnisse bereitstellen.
In den folgenden Abschnitten wird der schrittweise Prozess zum Einrichten, Konfigurieren und Bereitstellen von KI-Agents beschrieben. Dieser Prozess ermöglicht eine nahtlose Interaktion zwischen KI-Modellen und Ihrer PostgreSQL-Datenbank.
Rahmenwerke
Verschiedene Frameworks und Tools können die Entwicklung und Bereitstellung von KI-Agents erleichtern. Alle diese Frameworks unterstützen die Verwendung von Azure Database for PostgreSQL als Tool:
- Azure AI Foundry Agent Service
- LangChain/LangGraph
- LlamaIndex
- Semantischer Kernel
- AutoGen
- OpenAI-Assistenten-API
Beispiel für die Implementierung
Im Beispiel dieses Artikels wird der Azure AI Foundry Agent Service für die Agentplanung, die Toolverwendung und die Wahrnehmung verwendet. Es verwendet Azure Database für PostgreSQL als Tool für Vektordatenbank und semantische Suchfunktionen.
In den folgenden Abschnitten werden Sie durch die Erstellung eines KI-Agents geführt, der juristischen Teams bei der Recherche relevanter Fälle hilft, um ihre Kunden in Washington State zu unterstützen. Der Agent:
- Akzeptiert Anfragen in natürlicher Sprache zu rechtlichen Situationen.
- Verwendet die Vektorsuche in der Azure-Datenbank für PostgreSQL, um relevante Fallvorfälle zu finden.
- Analysiert und fasst die Ergebnisse in einem hilfreichen Format für Rechtsexperten zusammen.
Voraussetzungen
Aktivieren und konfigurieren Sie die
azure_aiUndpg_vectorErweiterungen.Bereitstellen von Modellen
gpt-4o-miniundtext-embedding-small.Installieren Sie Visual Studio Code.
Installieren Sie die Python-Erweiterung .
Installieren Sie Python 3.11.x.
Installieren Sie die Azure CLI (neueste Version).
Hinweis
Sie benötigen den Schlüssel und endpunkt aus den bereitgestellten Modellen, die Sie für den Agent erstellt haben.
Erste Schritte
Alle Code- und Beispieldatensätze sind in diesem GitHub-Repository verfügbar.
Schritt 1: Einrichten der Vektorsuche in Azure-Datenbank für PostgreSQL
Bereiten Sie zunächst Ihre Datenbank vor, um Rechtsfalldaten mithilfe von Vektoreinbettungen zu speichern und zu durchsuchen.
Einrichten der Umgebung
Wenn Sie macOS und Bash verwenden, führen Sie die folgenden Befehle aus:
python -m venv .pg-azure-ai
source .pg-azure-ai/bin/activate
pip install -r requirements.txt
Wenn Sie Windows und PowerShell verwenden, führen Sie die folgenden Befehle aus:
python -m venv .pg-azure-ai
.pg-azure-ai \Scripts\Activate.ps1
pip install -r requirements.txt
Wenn Sie Windows verwenden und cmd.exe, führen Sie die folgenden Befehle aus:
python -m venv .pg-azure-ai
.pg-azure-ai \Scripts\activate.bat
pip install -r requirements.txt
Konfigurieren von Umgebungsvariablen
Erstellen Sie eine .env Datei mit Ihren Anmeldeinformationen:
AZURE_OPENAI_API_KEY=""
AZURE_OPENAI_ENDPOINT=""
EMBEDDING_MODEL_NAME=""
AZURE_PG_CONNECTION=""
Laden von Dokumenten und Vektoren
Die Python-Datei load_data/main.py dient als zentraler Einstiegspunkt zum Laden von Daten in Azure Database for PostgreSQL. Der Code verarbeitet die Daten für Beispielfälle, einschließlich Informationen zu Fällen in Washington.
Die datei main.py:
- Erstellt erforderliche Erweiterungen, richtet OpenAI-API-Einstellungen ein und verwaltet Datenbanktabellen, indem vorhandene gelöscht und neue zum Speichern von Falldaten erstellt werden.
- Liest Daten aus einer CSV-Datei und fügt sie in eine temporäre Tabelle ein, verarbeitet und überträgt sie dann in die Hauptfalltabelle.
- Fügt eine neue Spalte für Einbettungen in die Falltabelle hinzu und generiert Einbettungen für Fallmeinungen mithilfe der OpenAI-API. Sie speichert die Einbettungen in der neuen Spalte. Der Einbettungsprozess dauert etwa 3 bis 5 Minuten.
Führen Sie zum Starten des Datenladevorgangs den folgenden Befehl aus dem load_data Verzeichnis aus:
python main.py
Dies ist die Ausgabe von main.py:
Extensions created successfully
OpenAI connection established successfully
The case table was created successfully
Temp cases table created successfully
Data loaded into temp_cases_data table successfully
Data loaded into cases table successfully.
Adding Embeddings will take a while, around 3-5 mins.
Embeddings added successfully All Data loaded successfully!
Schritt 2: Erstellen eines Postgres-Tools für den Agent
Konfigurieren Sie als Nächstes KI-Agent-Tools, um Daten aus Postgres abzurufen. Verwenden Sie dann das Azure AI Foundry Agent Service SDK, um Ihren KI-Agent mit der Postgres-Datenbank zu verbinden.
Definieren einer Funktion, die Ihr Agent aufrufen soll
Beginnen Sie mit der Definition einer Funktion für den Agent, die aufgerufen werden soll, indem Sie die Struktur und alle erforderlichen Parameter in einer Docstring beschreiben. Schließen Sie alle Funktionsdefinitionen in eine einzelne Datei ein, legal_agent_tools.py. Anschließend können Sie die Datei in Ihr Hauptskript importieren.
def vector_search_cases(vector_search_query: str, start_date: datetime ="1911-01-01", end_date: datetime ="2025-12-31", limit: int = 10) -> str:
"""
Fetches the case information in Washington State for the specified query.
:param query(str): The query to fetch cases specifically in Washington.
:type query: str
:param start_date: The start date for the search defaults to "1911-01-01"
:type start_date: datetime, optional
:param end_date: The end date for the search, defaults to "2025-12-31"
:type end_date: datetime, optional
:param limit: The maximum number of cases to fetch, defaults to 10
:type limit: int, optional
:return: Cases information as a JSON string.
:rtype: str
"""
db = create_engine(CONN_STR)
query = """
SELECT id, name, opinion,
opinions_vector <=> azure_openai.create_embeddings(
'text-embedding-3-small', %s)::vector as similarity
FROM cases
WHERE decision_date BETWEEN %s AND %s
ORDER BY similarity
LIMIT %s;
"""
# Fetch case information from the database
df = pd.read_sql(query, db, params=(vector_search_query,datetime.strptime(start_date, "%Y-%m-%d"), datetime.strptime(end_date, "%Y-%m-%d"),limit))
cases_json = json.dumps(df.to_json(orient="records"))
return cases_json
Schritt 3: Erstellen und Konfigurieren des KI-Agents mit Postgres
Richten Sie nun den KI-Agent ein und integrieren Sie ihn in das Postgres-Tool. Die Python-Datei src/simple_postgres_and_ai_agent.py dient als zentraler Einstiegspunkt zum Erstellen und Verwenden Ihres Agents.
Die datei simple_postgres_and_ai_agent.py:
- Initialisiert den Agent in Ihrem Azure AI Foundry-Projekt mit einem bestimmten Modell.
- Fügt das Tool Postgres für die Vektorsuche in Ihrer Datenbank während der Agentinitialisierung hinzu.
- Richtet einen Kommunikationsthread ein. Dieser Thread wird verwendet, um Nachrichten zur Verarbeitung an den Agent zu senden.
- Verarbeitet die Abfrage des Benutzers mithilfe des Agenten und Tools. Der Agent kann mit Tools planen, um die richtige Antwort zu erhalten. In diesem Anwendungsfall ruft der Agent das Tool Postgres basierend auf der Funktionssignatur und Docstring auf, um eine Vektorsuche durchzuführen und die relevanten Daten abzurufen, um die Frage zu beantworten.
- Zeigt die Antwort des Agents auf die Abfrage des Benutzers an.
Projektverbindungszeichenfolge in Azure AI Foundry finden
In Ihrem Azure AI Foundry-Projekt finden Sie ihre Projektverbindungszeichenfolge auf der Übersichtsseite des Projekts. Sie verwenden diese Zeichenfolge, um das Projekt mit dem Azure AI Foundry Agent Service SDK zu verbinden. Fügen Sie diese Zeichenfolge zur .env Datei hinzu.

Einrichten der Verbindung
Fügen Sie ihrer .env Datei im Stammverzeichnis diese Variablen hinzu:
PROJECT_CONNECTION_STRING=" "
MODEL_DEPLOYMENT_NAME="gpt-4o-mini"
AZURE_TRACING_GEN_AI_CONTENT_RECORDING_ENABLED="true"
### Create the agent with tool access
We created the agent in the Azure AI Foundry project and added the Postgres tools needed to query the database. The code snippet below is an excerpt from the file [simple_postgres_and_ai_agent.py](https://github.com/Azure-Samples/postgres-agents/blob/main/azure-ai-agent-service/src/simple_postgres_and_ai_agent.py).
# Create an Azure AI Foundry client
project_client = AIProjectClient.from_connection_string(
credential=DefaultAzureCredential(),
conn_str=os.environ["PROJECT_CONNECTION_STRING"],
)
# Initialize the agent toolset with user functions
functions = FunctionTool(user_functions)
toolset = ToolSet()
toolset.add(functions)
agent = project_client.agents.create_agent(
model= os.environ["MODEL_DEPLOYMENT_NAME"],
name="legal-cases-agent",
instructions= "You are a helpful legal assistant who can retrieve information about legal cases.",
toolset=toolset
)
Erstellen eines Kommunikations-Threads
Dieser Codeausschnitt zeigt, wie Sie einen Agentthread und eine Nachricht erstellen, die der Agent in einer Ausführung verarbeitet:
# Create a thread for communication
thread = project_client.agents.create_thread()
# Create a message to thread
message = project_client.agents.create_message(
thread_id=thread.id,
role="user",
content="Water leaking into the apartment from the floor above. What are the prominent legal precedents in Washington regarding this problem in the last 10 years?"
)
Verarbeiten der Anforderung
Der folgende Codeausschnitt erstellt eine Ausführung für den Agent zum Verarbeiten der Nachricht und verwendet die entsprechenden Tools, um das beste Ergebnis zu erzielen.
Mit den Tools kann der Agent die Vektorsuche und Postgres auf die Abfrage "Wasser dringt von der oberen Etage in die Wohnung ein" aufrufen, um die Daten abzurufen, die er benötigt, um die Frage bestmöglich zu beantworten.
from pprint import pprint
# Create and process an agent run in the thread with tools
run = project_client.agents.create_and_process_run(
thread_id=thread.id,
agent_id=agent.id
)
# Fetch and log all messages
messages = project_client.agents.list_messages(thread_id=thread.id)
pprint(messages['data'][0]['content'][0]['text']['value'])
Ausführen des Agents
Führen Sie zum Ausführen des Agents den folgenden Befehl aus dem src Verzeichnis aus:
python simple_postgres_and_ai_agent.py
Der Agent erzeugt ein ähnliches Ergebnis, indem das Azure Database for PostgreSQL-Tool verwendet wird, um auf Falldaten zuzugreifen, die in der Postgres-Datenbank gespeichert sind.
Hier ist ein Inhaltsausschnitt der Ausgabe des Agents:
1. Pham v. Corbett
Citation: Pham v. Corbett, No. 4237124
Summary: This case involved tenants who counterclaimed against their landlord for relocation assistance and breached the implied warranty of habitability due to severe maintenance issues, including water and sewage leaks. The trial court held that the landlord had breached the implied warranty and awarded damages to the tenants.
2. Hoover v. Warner
Citation: Hoover v. Warner, No. 6779281
Summary: The Warners appealed a ruling finding them liable for negligence and nuisance after their road grading project caused water drainage issues affecting Hoover's property. The trial court found substantial evidence supporting the claim that the Warners' actions impeded the natural water flow and damaged Hoover's property.
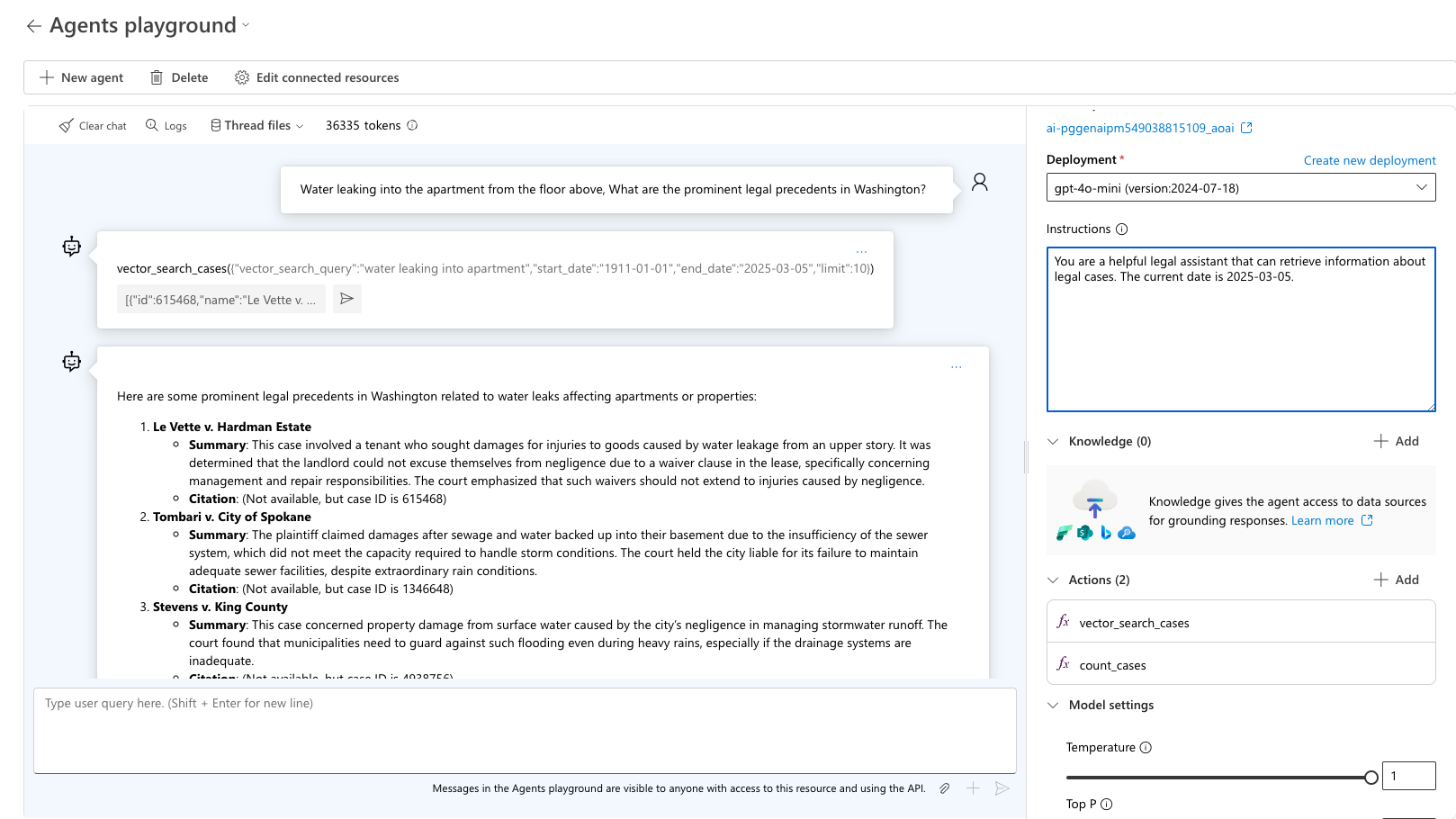
Schritt 4: Testen und Debuggen mit dem Agent-Playground
Nachdem Sie Ihren Agent mit dem Azure AI Foundry Agent Service SDK ausgeführt haben, wird der Agent in Ihrem Projekt gespeichert. Sie können mit dem Agent im Agent-Playground experimentieren:
Wechseln Sie in Azure AI Foundry zum Abschnitt "Agents ".
Suchen Sie Ihren Agent in der Liste, und wählen Sie ihn aus, um ihn zu öffnen.
Verwenden Sie die Playground-Schnittstelle, um verschiedene rechtliche Abfragen zu testen.

Überprüfen Sie die Anfrage: „Wasser tritt aus der darüber liegenden Wohnung in die Wohnung ein. Welche bedeutenden Präzedenzfälle gibt es in Washington?“ Der Mitarbeiter wählt das geeignete Tool aus und fragt nach dem erwarteten Ergebnis für diese Anfrage. Verwenden Sie sample_vector_search_cases_output.json als Beispielausgabe.
Schritt 5: Debuggen mit Azure AI Foundry-Ablaufverfolgung
Wenn Sie den Agent mithilfe des Azure AI Foundry Agent Service SDK entwickeln, können Sie den Agent mit ablaufverfolgung debuggen. Mit der Ablaufverfolgung können Sie die Aufrufe von Tools wie Postgres debuggen und sehen, wie der Agent jede Aufgabe koordiniert.
Wählen Sie im Azure AI Foundry Ablaufverfolgung aus.
Um eine neue Application Insights-Ressource zu erstellen, wählen Sie "Neu erstellen" aus. Um eine vorhandene Ressource zu verbinden, wählen Sie eine im Ressourcennamenfeld "Application Insights " aus, und wählen Sie dann "Verbinden" aus.

Zeigen Sie detaillierte Ablaufverfolgungen der Vorgänge Ihres Agenten an.

Erfahren Sie mehr darüber, wie Sie die Ablaufverfolgung mit dem KI-Agent und Postgres in der datei advanced_postgres_and_ai_agent_with_tracing.py auf GitHub einrichten.
Verwandte Inhalte
- Azure Database for PostgreSQL-Integrationen für KI-Anwendungen
- Verwenden von LangChain mit Azure-Datenbank für PostgreSQL
- Generieren von Vektoreinbettungen mit Azure OpenAI in Azure Database for PostgreSQL
- Azure AI-Erweiterung in Azure Database for PostgreSQL
- Erstellen einer semantischen Suche mit Azure Database für PostgreSQL und Azure OpenAI
- Aktivieren und Verwenden von pgvector in Azure-Datenbank für PostgreSQL