Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure KI-Suche ist eine skalierbare Suchinfrastruktur, die heterogene Inhalte indiziert und das Abrufen über APIs, Anwendungen und KI-Agents ermöglicht. Es eignet sich für Unternehmenssuchszenarien und KI-gestützte Kundenerfahrungen, die eine dynamische Inhaltsgenerierung über Chat-Abschlussmodelle erfordern.
In diesem Artikel wird die Zuverlässigkeitsunterstützung in Azure KI-Suche beschrieben, wobei sowohl intraregionale Resilienz mittels Verfügbarkeitszonen als auch Bereitstellungen in mehreren Regionen behandelt werden.
Zuverlässigkeit ist eine gemeinsame Verantwortung zwischen Ihnen und Microsoft. Mit diesem Leitfaden können Sie ermitteln, welche Zuverlässigkeitsoptionen Ihre spezifischen Geschäftsziele und Uptime-Ziele erfüllen.
Empfehlungen für die Produktionsimplementierung für Zuverlässigkeit
Für Produktionsworkloads wird empfohlen, eine, abrechenbaren Tarif mit mindestens zwei Replikaten zu verwenden. Diese Konfiguration macht Ihren Suchdienst stabiler gegenüber vorübergehenden Fehlern und Wartungsvorgängen. Sie erfüllt auch die Service-Level-Vereinbarung (SLA) für AI Search. Das SLA erfordert zwei Replikate für schreibgeschützte Workloads und drei oder mehr für Lese-/Schreibworkloads.
KI-Suche bietet kein SLA für den Free-Tarif, der auf ein Replikat beschränkt ist und dessen Verwendung für Produktionsumgebungen nicht empfohlen wird.
Übersicht über die Zuverlässigkeitsarchitektur
Wenn Sie AI Search verwenden, erstellen Sie einen Suchdienst. Jeder Suchdienst unterstützt viele Suchindizes, die Ihre durchsuchbaren Inhalte speichern.
DIE KI-Suche ist nicht als primärer Datenspeicher konzipiert. Stattdessen verwenden Sie Indexer, um Ihren Suchdienst mit externen Datenquellen zu verbinden. Ein Indexer durchforstet die Quelldaten, ruft Skills auf, die Verarbeitung und Anreicherung durchführen, und füllt Ihren Index mit den Ausgaben des der Skills auf.
Außerdem konfigurieren Sie die Anzahl der Replikate für Ihren Dienst. In der KI-Suche ist ein Replikat eine Kopie der Suchmaschine Ihres Diensts. Sie können sich ein Replikat als Darstellung eines einzelnen virtuellen Computers (Virtuelle Maschine, VM) vorstellen. Jeder Suchdienst kann zwischen einem und 12 Replikaten enthalten.
Das Hinzufügen mehrerer Replikate ermöglicht KI-Suche Folgendes:
Erhöhen der Verfügbarkeit Ihres Suchdiensts
Führen Sie Wartung für ein Replikat aus, während Abfragen weiterhin auf anderen Replikaten ausgeführt werden.
Verarbeiten höherer Indizierungs- und Abfrageworkloads
Verbessern Sie die Resilienz, indem Sie versuchen, Replikate in verschiedenen Verfügbarkeitszonen bereitzustellen, wenn Ihre Region sie unterstützt.
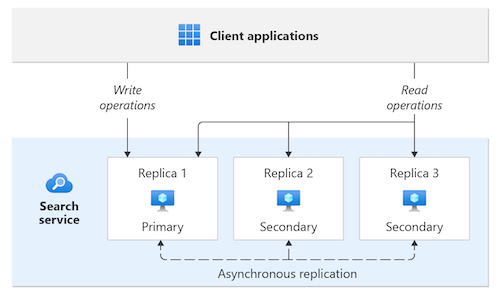
DIE KI-Suche weist automatisch ein Replikat als primäres Replikat zu. Alle Schreibvorgänge werden für dieses Replikat ausgeführt. Die anderen Replikate werden für Lesevorgänge verwendet.
Das folgende Diagramm veranschaulicht, wie ein Suchdienst mit drei Replikaten über drei Verfügbarkeitszonen verteilt werden könnte:
Sie können auch die Anzahl der Partitionen konfigurieren, die den von den Suchindizes verwendeten Speicher darstellen.
Es ist wichtig, die Auswirkungen des Hinzufügens von Replikaten und Partitionen zu verstehen, da sie sich jeweils auf die Lese- und Schreibleistung auf unterschiedliche Weise auswirken. Weitere Informationen zu Replikaten und Partitionen finden Sie unter Schätzen und Verwalten der Kapazität eines Suchdiensts.
Vorübergehende Fehler
Vorübergehende Fehler sind kurze, zeitweilige Fehler in Komponenten. Sie treten häufig in einer verteilten Umgebung wie der Cloud auf und sind ein normaler Bestandteil von Vorgängen. Vorübergehende Fehler korrigieren sich nach kurzer Zeit. Es ist wichtig, dass Ihre Anwendungen vorübergehende Fehler behandeln können. Dies geschieht in der Regel durch Wiederholen betroffener Anforderungen.
Alle in der Cloud gehosteten Anwendungen sollten die Anleitung zur vorübergehenden Fehlerbehandlung von Azure befolgen, wenn sie mit cloudgehosteten APIs, Datenbanken und anderen Komponenten kommunizieren. Weitere Informationen finden Sie unter Empfehlungen zur Behandlung vorübergehender Fehler.
KI-Suchindexer verfügen über integrierte vorübergehende Fehlerbehandlung. Wenn eine Datenquelle kurzzeitig nicht verfügbar ist, ist der Indexer so ausgelegt, dass er sich erholt und den Vorgang erneut versucht. Es verwendet die Änderungsnachverfolgung, um die Indizierung aus dem letzten erfolgreich indizierten Dokument fortzusetzen.
Bei Suchdiensten können vorübergehende Fehler während standardmäßiger ungeplanter Wartungsvorgänge auftreten. Azure KI-Suche bietet keine Vorabbenachrichtigungen und ermöglicht auch nicht die Planung der Wartung zu bestimmten Zeiten. Obwohl alles dafür getan wird, um die Downtime zu minimieren, können auch bei Einzelreplikatdiensten weiterhin kurze Unterbrechungen auftreten. Um die Resilienz gegenüber diesen vorübergehenden Fehlern zu verbessern, wird empfohlen, zwei oder mehr Replikate zu verwenden.
Wenn Sie Anwendungen erstellen, die mit der KI-Suche arbeiten, sollten sie vorübergehende Fehler behandeln. Verwenden Sie eine Wiederholungsstrategie mit exponentiellen Backoffs für Lese- und Schreibvorgänge.
Unterstützung für Verfügbarkeitszonen
Verfügbarkeitszonen sind physisch getrennte Gruppen von Rechenzentren innerhalb jeder Azure-Region. Wenn eine Zone ausfällt, erfolgt ein Failover der Dienste zu einer der verbleibenden Zonen.
KI-Suche ist zonenredundant, was bedeutet, dass Ihre Replikate innerhalb der Suchdienstregion auf mehrere Verfügbarkeitszonen verteilt werden.
Wenn Sie Ihrem Dienst zwei oder mehr Replikate hinzufügen, versucht AI Search, jedes Replikat in einer anderen Verfügbarkeitszone zu platzieren. Bei Diensten mit mehr Replikaten als verfügbaren Zonen werden Replikate gleichmäßig über Zonen verteilt.
Das folgende Diagramm veranschaulicht, wie ein beispielhafter Suchdienst mit vier Replikaten über drei Verfügbarkeitszonen hinweg bereitgestellt werden könnte:

Von Bedeutung
DIE KI-Suche garantiert nicht die genaue Platzierung von Replikaten. Die Platzierung unterliegt Kapazitätsbeschränkungen, Skalierungsvorgängen und anderen Faktoren.
Regionsunterstützung
Die Unterstützung für Verfügbarkeitszonen hängt von der Infrastruktur und dem Speicher ab. Eine Liste der unterstützten Regionen finden Sie unter Auswählen einer Region für die KI-Suche.
Anforderungen
Zonenredundanz wird automatisch aktiviert, wenn Ihr Suchdienst alle folgenden Kriterien erfüllt:
- Erfüllt die Regionsanforderungen.
- Befindet sich auf der Stufe "Einfach" oder höher
- Verfügt über mindestens zwei Replikate
Hinweis
DIE KI-Suche versucht, Replikate über mehrere Zonen zu verteilen, wenn Sie über zwei oder mehr Replikate verfügen. Für Lese-/Schreibworkloads sollten Sie jedoch drei oder mehr Replikate verwenden, damit Sie das höchstmögliche Verfügbarkeits-SLA erhalten.
Instanzverteilung über Zonen hinweg
DIE KI-Suche versucht, Replikate in verschiedenen Verfügbarkeitszonen zu platzieren. Es gibt jedoch gelegentlich Situationen, in denen alle Replikate eines Suchdiensts möglicherweise in derselben Verfügbarkeitszone platziert werden. Diese Situation kann auftreten, wenn Replikate aus Ihrem Dienst entfernt werden, z. B. wenn Sie abskalieren, indem Sie Ihren Dienst so konfigurieren, dass weniger Replikate verwendet werden. Das Entfernen von Replikaten führt nicht dazu, dass die verbleibenden Replikate sich über die Verfügbarkeitszonen neu verteilen.
Um die Wahrscheinlichkeit zu verringern, dass alle Ihre Replikate in einer einzelnen Verfügbarkeitszone platziert werden, können Sie direkt nach einem Abskalierungsvorgang manuell einen Aufskalierungsvorgang auslösen. Angenommen, Ihr Suchdienst verfügt über 10 Replikate, und Sie möchten in 7 Replikate skalieren. Anstatt einen einzelnen Skalierungsvorgang auszuführen, können Sie vorübergehend auf 6 Instanzen skalieren und dann sofort auf 7 Instanzen skalieren, um die Zonenrebalancing auszulösen.
Kosten
Jeder Suchdienst beginnt mit einem Replikat. Zonenredundanz erfordert zwei oder mehr Replikate, wodurch die Kosten für die Ausführung des Diensts erhöht werden. Verwenden Sie den Preisrechner, um die Auswirkungen auf Replikate zu verstehen.
Konfigurieren der Unterstützung von Verfügbarkeitszonen
Wenn Ihr Suchdienst die Anforderungen für Zonenredundanz erfüllt, ist keine zusätzliche Konfiguration erforderlich. Nach Möglichkeit versucht die KI-Suche, Ihre Replikate in verschiedenen Verfügbarkeitszonen zu platzieren.
Kapazitätsplanung und -verwaltung
Um sich auf einen Verfügbarkeitszonenfehler vorzubereiten, sollten Sie die Anzahl der Replikas überprovisionieren. Die Overprovisioning ermöglicht es dem Suchdienst, einige Kapazitätsverluste zu tolerieren und ohne beeinträchtigte Leistung weiter zu funktionieren. Das Hinzufügen von Replikaten während eines Ausfalls ist eine Herausforderung, sodass die Überteilung dazu beiträgt, dass Ihr Suchdienst normale Anforderungsvolumes auch mit geringerer Kapazität verarbeiten kann. Weitere Informationen finden Sie unter Kapazität durch Überprovisionierung verwalten.
Normalbetrieb
In diesem Abschnitt wird beschrieben, was Sie erwarten können, wenn der Suchdienst für Zonenredundanz konfiguriert und alle Verfügbarkeitszonen betriebsbereit sind.
Datenverkehrsrouting zwischen Zonen: KI-Suche führt automatischen Lastenausgleich aller Abfragen und Schreiboperationen für alle verfügbaren Replikate durch. KI-Suche kann Lesevorgänge an jedes Replikat in einer beliebigen Verfügbarkeitszone senden. Es sendet Schreibvorgänge an ein einzelnes primäres Replikat, das der AI-Suchdienst auswählt.
Datenreplikation zwischen Zonen: Änderungen an Daten werden automatisch zwischen Replikaten in allen Verfügbarkeitszonen repliziert. Die Replikation erfolgt asynchron, was bedeutet, dass Schreibvorgänge auf ein primäres Replikat angewendet werden, bevor sie in andere Replikate repliziert werden.
Zonenausfall
In diesem Abschnitt wird beschrieben, was Sie erwarten müssen, wenn Suchdienste für Zonenredundanz konfiguriert sind und ein Ausfall der Verfügbarkeitszone auftritt.
Erkennung und Reaktion: DIE KI-Suche ist dafür verantwortlich, einen Fehler in einer Verfügbarkeitszone zu erkennen. Sie müssen keine Maßnahmen ergreifen, um ein Zonenfailover zu initiieren.
Benachrichtigung: KI-Suche benachrichtigt Sie nicht, wenn eine Zone abfällt. Sie können jedoch Azure Resource Health verwenden, um die Integrität von Replikaten zu überwachen. Wenn eine Zone ausgefallen ist, werden die Replikas in dieser Zone als nicht verfügbar angezeigt. Sie können auch Azure Service Health verwenden, um einen Einblick in den Gesamtstatus des KI-Suchdiensts zu erhalten, einschließlich Zonenausfällen.
Richten Sie Benachrichtigungen für diese Dienste ein, um Benachrichtigungen über Probleme auf Zonenebene zu erhalten. Weitere Informationen finden Sie unter Erstellen von Dienststatuswarnungen im Azure-Portal und Erstellen und Konfigurieren von Warnungen zum Ressourcenstatus.
Aktive Anforderungen: Anforderungen, die Replikate in der ausgefallenen Zone verarbeiten, werden beendet. Clients sollten die Anforderungen wiederholen, indem sie die Anleitung zur Behandlung vorübergehender Fehler folgen.
Erwarteter Datenverlust: Wenn die betroffene Verfügbarkeitszone nur Lesereplikate enthält, wird kein Datenverlust erwartet.
Wenn das primäre Replikat verloren geht, da es sich in der betroffenen Zone befand, gehen alle Schreibvorgänge, die noch nicht repliziert wurden, möglicherweise verloren.
Erwartete Downtime: In den meisten Fällen ist nicht zu erwarten, dass ein Zonenausfall zu Downtime für den Suchdienst bei Lesevorgängen führt, da Lesereplikate in anderen Verfügbarkeitszonen Anforderungen weiterhin bearbeiten.
Wenn das primäre Replikat verloren geht, da es sich in der betroffenen Zone befand, stuft AI Search automatisch ein weiteres Replikat höher, um zur neuen primären Replikat zu werden, sodass Schreibvorgänge fortgesetzt werden können. Es dauert in der Regel ein paar Sekunden, bis die Höherstufung des Replikats erfolgt. Während dieser Zeit können Schreibvorgänge nicht erfolgreich ausgeführt werden. Stellen Sie sicher, dass Ihre Anwendungen vorbereitet sind, indem Sie den Leitfaden zur Behandlung vorübergehender Fehler befolgen.
Es gibt jedoch einige unwahrscheinliche Situationen, in denen sich alle Replikate Ihres Suchdiensts möglicherweise in einer einzigen Verfügbarkeitszone befinden. In diesem Szenario können Ausfallzeiten auftreten, bis die Zone wiederhergestellt wird. Weitere Informationen und eine Erläuterung, wie eine Problemumgehung funktioniert, finden Sie unter Instanzverteilung.
Datenverkehrsumleitung: Wenn eine Zone fehlschlägt, erkennt die KI-Suche den Fehler und leitet Anforderungen an aktive Replikate in den überlebenden Zonen weiter. Wenn das primäre Replikat verloren geht, wird ein weiteres Replikat als neue primäre Replikat heraufgestuft.
Zonenwiederherstellung
Wenn die Verfügbarkeitszone wiederhergestellt wird, stellt AI Search automatisch normale Vorgänge wieder her und beginnt mit dem Routing des Datenverkehrs an verfügbare Replikate in allen Zonen, einschließlich der wiederhergestellten Zone.
Testen auf Zonenfehler
AI Search verwaltet das Datenverkehrsrouting für zonenredundante Dienste. Sie müssen keine Zonenausfallprozesse initiieren oder überprüfen.
Unterstützung für mehrere Regionen
Die KI-Suche ist ein Dienst für eine einzelne Region. Wenn die Region nicht verfügbar ist, verliert auch ihr Suchdienst seine Verfügbarkeit.
Alternative Ansätze für mehrere Regionen
Sie können optional mehrere KI-Suchdienste in verschiedenen Regionen bereitstellen. Sie sind für das Bereitstellen und Konfigurieren separater Dienste in den einzelnen Regionen verantwortlich. Wenn Sie eine identische Bereitstellung in einer sekundären Azure-Region erstellen, die eine Multi-Region-Architektur verwendet, wird Ihre Anwendung weniger anfällig für einen Ausfall einer einzelnen Region.
Wenn Sie diesem Ansatz folgen, müssen Sie Indizes in allen Regionen synchronisieren, um den letzten Anwendungszustand wiederherzustellen. Sie müssen außerdem Lastenausgleichs- und Failoverrichtlinien konfigurieren.
Um die Leistung Ihrer Gesamtlösung zu optimieren, sollten Sie nach Gelegenheiten suchen, um die Indizierung für schreibgeschützte Replikate Ihrer Datenquellen durchzuführen. So unterstützen beispielsweise einige Indexer das Lesen aus den Lesereplikaten einer geografisch verteilten Datenquelle.
Weitere Informationen finden Sie unter Bereitstellungen in mehreren Regionen in Azure KI-Suche.
Datensicherungen
Da KI-Suche keine primäre Datenspeicherlösung ist, stellt sie keine Self-Service-Sicherungs- und Wiederherstellungsoptionen zur Verfügung. Sie können jedoch das index-backup-restore-Beispiel für .NET oder Python verwenden, um Ihre Indexdefinition und ihre Dokumente in einer Reihe von JSON-Dateien zu sichern, die dann zum Wiederherstellen des Indexes verwendet werden können.
Wenn Sie den Index jedoch versehentlich löschen und nicht über eine Sicherung verfügen, können Sie den Index neu erstellen. Bei der Neuerstellung wird der Index in Ihrem Suchdienst neu erstellt und anschließend neu geladen, indem Daten aus dem primären Datenspeicher abgerufen werden.
Service-Level-Vereinbarung
Der Service level agreement (SLA) für Azure-Dienste beschreibt die erwartete Verfügbarkeit jedes Diensts und die Bedingungen, die Ihre Lösung erfüllen muss, um diese Verfügbarkeitserwartungen zu erreichen. Weitere Informationen finden Sie unter SLAs für Onlinedienste.
In der KI-Suche gilt die Verfügbarkeits-SLA für Suchdienste, die:
- Für die Verwendung eines abrechnungsfähigen Tarifs konfiguriert.
- Verfügen über mindestens zwei Replikate für schreibgeschützte Workloads (Abfragen).
- verfügen über mindestens drei Replikate für Lese-/Schreibworkloads (Abfragen und Indizierung).