Azure AI Foundry ポータルで評価結果を表示する方法について説明します。 AI モデルの評価データ、パフォーマンス メトリック、品質評価を表示して解釈します。 フロー、プレイグラウンド セッション、SDK から結果にアクセスして、データドリブンの意思決定を行います。
評価結果を視覚化したら、詳細な調査を行うことができます。 個々の結果を表示し、複数の評価実行でこれらの結果を比較できます。 傾向、パターン、不一致を特定できます。これにより、さまざまな条件下での AI システムのパフォーマンスに関する貴重な分析情報を得ることができます。
この記事では、次の方法について説明します。
- 評価ランを見つけて開いてください。
- 集計とサンプル レベルのメトリックを表示します。
- 実行間で結果を比較します。
- メトリックのカテゴリと計算を解釈します。
- メトリックの不足または部分的なトラブルシューティングを行います。
評価結果を表示する
評価を送信したら、[評価] ページで実行を見つけます。 列をフィルター処理または調整して、関心のある実行に焦点を合わせます。 詳しく調査する前に、概要メトリックを一目で確認します。
ヒント
評価の実行は、任意のバージョンの promptflow-evals SDK または azure-ai-evaluation バージョン 1.0.0b1、1.0.0b2、1.0.0b3 で表示できます。
すべての実行を表示のトグルをオンにして、実行を特定します。
[定義と数式の メトリックの詳細を確認 する] を選択します。

実行を選択して、詳細 (データセット、タスクの種類、プロンプト、パラメーター) とサンプルごとのメトリックを開きます。 メトリック ダッシュボードでは、メトリックごとの合格率または集計スコアが視覚化されます。
注意事項
以前にモデルのデプロイを管理し、 oai.azure.comを使用して評価を実行した後、Azure AI Foundry 開発者プラットフォームにオンボードしたユーザーは、 ai.azure.comを使用する場合、次の制限があります。
- これらのユーザーは、Azure OpenAI API を使用して作成された評価を表示できません。 これらの評価を表示するには、
oai.azure.comに戻る必要があります。 - これらのユーザーは、Azure OpenAI API を使用して Azure AI Foundry 内で評価を実行することはできません。 代わりに、このタスクには引き続き
oai.azure.comを使用する必要があります。 ただし、データセット評価の作成オプションでは、Azure AI Foundry (ai.azure.com) で直接使用できる Azure OpenAI エバリュエーターを使用できます。 デプロイが Azure OpenAI から Azure AI Foundry への移行である場合、微調整されたモデル評価のオプションはサポートされません。
データセットのアップロードと独自のストレージの持ち込みのシナリオには、いくつかの構成要件があります。
- アカウント認証は Microsoft Entra ID である必要があります。
- ストレージをアカウントに追加する必要があります。 プロジェクトに追加すると、サービス エラーが発生します。
- ユーザーは、Azure portal でアクセス制御を使用して、自分のプロジェクトをストレージ アカウントに追加する必要があります。
Azure OpenAI ハブで OpenAI 評価グレードを使用して評価を作成する方法の詳細については、「Azure AI Foundry モデルの評価で Azure OpenAI を使用する方法」を参照してください。
指標ダッシュボード
メトリック ダッシュボード セクションでは、集計ビューは、AI 品質 (AI アシスト)、リスクと安全性 (プレビュー)、AI 品質 (NLP)、カスタム (該当する場合) を含むメトリックによって分類されます。 結果は、評価の作成時に選択された条件に基づいて、合格/不合格の割合として測定されます。 メトリック定義とその計算方法の詳細については、「 エバリュエーターとは」を参照してください。
-
AI 品質 (AI 支援) メトリックの場合、メトリックごとにすべてのスコアを平均することで結果が集計されます。
Groundedness Pro を使用する場合、出力はバイナリであり、集計スコアは合格率です:
(#trues / #instances) × 100。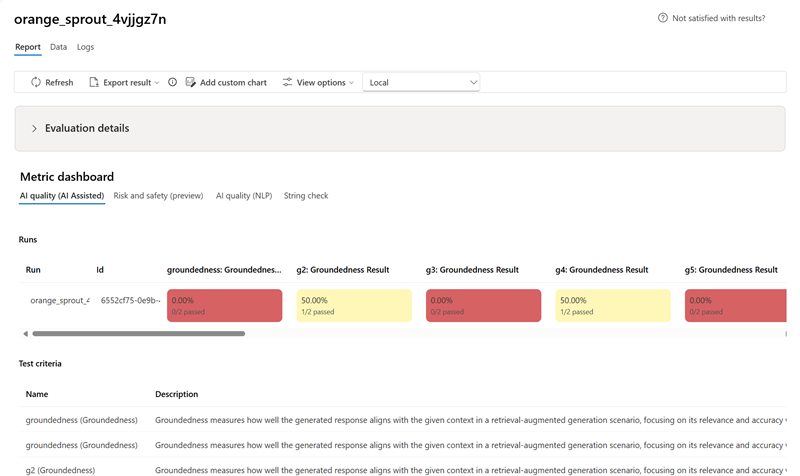
-
リスクと安全性 (プレビュー) メトリックの場合、結果は欠陥率によって集計されます。
- コンテンツの損害: 重大度しきい値を超えるインスタンスの割合 (既定の
Medium)。 - 保護されたマテリアルと間接攻撃の場合、欠陥率は、数式
trueを使用して出力が(Defect Rate = (#trues / #instances) × 100)されるインスタンスの割合として計算されます。![[リスクと安全性の指標] ダッシュボード タブを示すスクリーンショット。](../media/evaluations/view-results/risk-and-safety-chart.png)
- コンテンツの損害: 重大度しきい値を超えるインスタンスの割合 (既定の
-
AI 品質 (NLP) メトリックの場合、結果はメトリックごとの平均スコアによって集計されます。


![[リスクと安全性の指標] ダッシュボード タブを示すスクリーンショット。](../media/evaluations/view-results/risk-and-safety-chart.png#lightbox)

詳細メトリックの結果テーブル
ダッシュボードの下のテーブルを使用して、各データ サンプルを調べます。 メトリックで並べ替えて、最もパフォーマンスの低いサンプルを表示し、体系的なギャップ (不適切な結果、安全性の失敗、待機時間) を特定します。 クラスター関連の障害に関するトピックを検索して使用します。 列のカスタマイズを適用して、主要なメトリックに焦点を当てます。
一般的なアクション:
- 定期的なパターンを検出するために低いスコアをフィルター処理します。
- システム的なギャップが発生した場合は、プロンプトを調整したり、微調整を行います。
- オフライン分析用にエクスポートします。
質問に回答するシナリオのメトリック結果の例を次に示します。

一部の評価にはサブエバリュエーターがあり、サブ評価の結果の JSON を表示できます。 結果を表示するには、[ JSON で表示] を選択します。

JSON プレビューで JSON を表示します。

会話シナリオのメトリック結果の例を次に示します。 複数ターンの会話全体で結果を確認するには、[会話] 列の [ターンごとの評価結果の表示] を選択します。

[1 ターンあたりの評価結果の表示] を選択すると、次の画面が表示されます。

マルチモーダル シナリオ (テキストと画像) での安全性評価の場合は、詳細メトリック結果テーブルの入力と出力の両方の画像を確認することで、評価結果をよりよく理解できます。 マルチモーダル評価は現在、会話シナリオでのみサポートされているため、[ 1 ターンあたりの評価結果の表示 ] を選択して、各ターンの入力と出力を確認できます。

画像を選択して展開し、表示します。 既定では、すべての画像はぼかして表示され、有害なコンテンツから保護されます。 画像を明確に表示するには、[ ぼかし画像のチェック ]トグルをオンにします。
![ぼやけた画像と[ぼかし画像のチェック]トグルを示すスクリーンショット。](../media/evaluations/view-results/image-check-blur-image.png#lightbox)
評価結果は、異なる対象ユーザーに対して異なる意味を持つ場合があります。 たとえば、安全性評価では、特定の暴力コンテンツがどの程度厳しいかについての人間のレビュー担当者の定義に合わない可能性がある、暴力コンテンツの重大度が 低 いラベルが生成される場合があります。 評価の作成時に設定された合格基準により、合格または不合格が割り当てられるかどうかが決まります。 評価結果を確認するときに、「サムズアップ」または「サムズダウン」のアイコンを選択できる 人間のフィードバック 列があります。 この列を使用すると、人間のレビュー担当者によって承認または正しくないとしてフラグが設定されたインスタンスをログに記録できます。

各コンテンツ リスク メトリックを理解するには、[ レポート ] セクションに戻ってメトリック定義を表示するか、[ メトリック ダッシュボード ] セクションでテストを確認します。
実行に問題がある場合は、ログを使用して評価実行をデバッグすることもできます。 評価実行のデバッグに使用できるログの例を次に示します。

プロンプト フローを評価する場合は、[ フローで表示 ] ボタンを選択して、評価されたフロー ページに移動し、フローを更新できます。 たとえば、追加のメタ プロンプト命令を追加したり、いくつかのパラメーターを変更して再評価したりできます。
評価結果を比較する
2 つ以上の実行間の包括的な比較を容易にするために、目的の実行を選択してプロセスを開始できます。 [ 比較 ] ボタンを選択するか、一般的な詳細なダッシュボード ビューの [ ダッシュボード ビューに切り替える ] ボタンを選択します。 複数の実行のパフォーマンスと結果を分析して比較し、より多くの情報に基づいた意思決定とターゲットを絞った改善が可能になります。

ダッシュボード ビューでは、メトリック分布比較 グラフ と比較テーブルという 2 つの重要なコンポーネントにアクセス できます。 これらのツールを使用して、選択した評価実行のサイド バイ サイド分析を実行できます。 各データ サンプルのさまざまな側面を簡単かつ正確に比較できます。
注
既定では、古い評価実行では列間の行が一致します。 ただし、新しく実行する評価は、評価の作成時に一致する列を持つよう意図的に構成する必要があります。 比較するすべての評価で、抽出 条件名 の値と同じ名前が使用されていることを確認します。
次のスクリーンショットは、フィールドが同じ場合のエクスペリエンスを示しています。

ユーザーが評価の作成に同じ 抽出条件名 を使用しない場合、フィールドが一致しないため、プラットフォームで結果を直接比較できなくなります。

比較テーブル内で、参照ポイントとして使用して基準計画として設定する特定の実行にカーソルを合わせると、比較の基準計画を確立できます。 また、[ 差分の表示 ] トグルを有効にして、数値の基準実行と他の実行の違いを簡単に視覚化することもできます。 さらに、[ 違いのみを表示 ] トグルを選択すると、選択した実行間で異なる行のみがテーブルに表示され、個別のバリエーションの識別に役立ちます。
これらの比較機能を使用すると、情報に基づいて最適なバージョンを選択することができます。
- ベースライン比較: ベースライン実行を設定することで、他の実行を比較する基準点を特定できます。 各実行が選択した標準からどのように逸脱しているかを確認できます。
- 数値評価: [ 差分の表示 ] オプションを有効にすると、ベースラインと他の実行の違いの程度を理解するのに役立ちます。 この情報は、特定の評価メトリックに関して、さまざまな実行のパフォーマンスを評価するのに役立ちます。
- 差の分離: [違いのみを表示] 機能を使用すると、実行間に不一致がある領域のみが強調表示され、分析が効率化されます。 この情報は、改善や調整が必要な場所を特定するのに有用です。
比較ツールを使用して、安全性や接地の回帰を回避しながら、最適なパフォーマンスの構成を選択します。

脱獄の脆弱性を測定する
脱獄の脆弱性の評価は、AI 支援メトリックではなく、比較測定です。 2 つの異なるレッドチーミングされたデータセットに対して評価を実行します。つまり、ベースラインの敵対的テスト データセットと、最初のターンにジェイルブレイク インジェクションがある同じ敵対的テスト データセットです。 敵対的データ シミュレーターを使用して、ジェイルブレイク インジェクションの有無にかかわらずデータセットを生成できます。 実行を構成するときに、評価メトリックごとに 条件名 の値が同じであることを確認します。
アプリケーションが脱獄に対して脆弱かどうかを理解するには、ベースラインを指定し、比較表の 脱獄欠陥率 トグルをオンにします。 脱獄欠陥率とは、テストデータセット内のインスタンス割合を指し、ベースラインと比較して、データセット全体のサイズに対して、いずれかのコンテンツリスクメトリックの重大度スコアが脱獄挿入により高くなる場合のことです。 [比較] ダッシュボードで複数の評価を選択して、欠陥率の差を表示できます。

ヒント
ジェイルブレイクの欠陥率は、同じサイズのデータセットに関してのみ、それらを比較することで計算され、また、すべての実行にコンテンツ リスクと安全性に関するメトリックが含まれている場合にのみ計算されます。
組み込みの評価メトリックを理解する
組み込みのメトリックについて理解することは、AI アプリケーションのパフォーマンスと有効性を評価するために不可欠です。 これらの主要な測定ツールに関する分析情報を取得すると、結果を解釈し、情報に基づいた意思決定を行い、アプリケーションを微調整して、最適な結果を達成する態勢が整います。 次の側面の詳細については、「 評価メトリックと監視メトリック 」を参照してください。
- 各メトリックの重要性
- 計算方法
- モデルのさまざまな側面を評価する役割
- 結果を解釈してデータドリブンの改善を行う方法
トラブルシューティング
| 症状 | 考えられる原因 | アクション |
|---|---|---|
| 実行が保留中のまま | サービスの高負荷/キューに入れられたジョブ | リフレッシュ;クォータを確認する。延長された場合は再送信する |
| メトリックが見つからない | 作成時に選択されていません | 必要なメトリックの選択を再実行する |
| すべての安全メトリックゼロ | カテゴリが無効になっているか、サポートされていないモデル | モデルとメトリックのサポート マトリックスを確認する |
| 接地性が予期せず低い | 取得/コンテキストが不完全 | コンテキストの構築/取得の待機時間を確認する |
次のステップ
- プロンプトの繰り返しまたは 微調整を使用して、低メトリックを改善します。
- トレースを追加して、待機時間や予期しないツールの手順を診断します。
- Azure AI Foundry SDK を使用してクラウドで評価を実行します。
関連コンテンツ
ご利用の生成 AI アプリケーションを評価する方法の詳細については、次をご参照ください。
損害の軽減手法についての詳細情報。