このクイック スタートでは、 Azure AI Foundry ポータル で Content Understanding サービスを使用して、構造化された情報をデータから抽出する方法について説明します。 Azure AI Foundry を使用すると、生成型 AI アプリケーションと API を責任を持って構築およびデプロイできます。
ドキュメント、画像、オーディオ、ビデオなどのファイルがあり、そこからキー情報を自動的に抽出するとします。 Content Understanding を使用すると、データ処理を整理するタスクを作成し、抽出または生成する情報を指定するフィールド スキーマを定義してから、アナライザーを構築できます。 アナライザーは、アプリケーションまたはワークフローに統合できる API エンドポイントになります。
このガイドでは、シナリオに合わせてアナライザーをビルドしてテストします。 最初から始めたり、一般的なユース ケースに推奨されるテンプレートを使用したりできます。

前提条件
開始するには、次のリソースとアクセス許可があることを確認します。
Azure サブスクリプション。 Azure サブスクリプションをお持ちでない場合は、無料アカウントを作成してください。
サポートされているリージョン (、
westus、またはswedencentral) のいずれかで作成されたaustraliaeast。 プロジェクトを使用して作業を整理し、カスタマイズされた AI アプリを構築しながら状態を保存します。 プロジェクトは、 AI Foundry のホーム ページまたは Content Understanding ランディング ページから作成できます。
注
この機能には ハブ ベースのプロジェクト を使用する必要があります。 Foundry プロジェクトはサポートされていません。 「 自分が持っているプロジェクトの種類を確認する方法 」と 「ハブ ベースのプロジェクトを作成する」を参照してください。
Content Understanding Standard モードを利用して単一ファイル タスクを作成する
Azure AI Foundry でカスタム タスクを作成するには、次の手順に従います。 このタスクを使用して、最初のアナライザーをビルドします。
- Azure AI Foundry のホーム ページに移動します。
- ハブ ベースのプロジェクトを選択します。 プロジェクトを表示するには、[ すべてのリソースの表示 ] を選択する必要がある場合があります。
- 左側のナビゲーション ウィンドウから [Content Understanding ] を選択します。
- [+ 作成] を選択します。
- このガイドでは、Content Understanding Standard モードを使用する
Single-file taskを作成しますが、Pro モードを使用したマルチファイル タスクの作成に関心がある場合は、 Azure AI Foundry ポータルで Azure AI Content Understanding マルチファイル タスクを作成するを参照してください。 シナリオに適したモードの詳細については、 Azure AI Content Understanding のプロモードと標準モードを確認してください。 - タスクの名前を入力します。 必要に応じて、説明を入力し、他の設定を変更します。
- [作成] を選択します
最初のアナライザーを作成する
すべてが構成されたので、最初のアナライザーをビルドできます。
単一ファイルの Content Understanding タスクを作成する場合は、まずデータのサンプルをアップロードし、フィールド スキーマを作成します。 スキーマは、アナライザーでデータから分析情報を抽出できるようにするカスタマイズ可能なフレームワークです。 この例では、請求書ドキュメントからキー データを抽出するスキーマを作成しますが、任意の種類のデータを取り込むことができますが、手順は変わりません。 サポートされるファイルの種類の完全な一覧については、「入力ファイルの制限」を参照してください。
請求書ドキュメントまたはシナリオに関連するその他のデータのサンプル ファイルをアップロードします。
次に、コンテンツ タイプに基づいて、コンテンツの解釈サービスからアナライザー テンプレートが提案されます。 各モダリティ用に提供されているすべてのテンプレートの完全な一覧については、「コンテンツの解釈で提供されるアナライザー テンプレート」を参照してください。 この例では、[ドキュメント分析] を選択して、請求書のシナリオに合わせて独自のスキーマを作成します。 独自のデータを使用する場合は、ニーズに最も適合するアナライザー テンプレートを選択するか、独自のものを作成します。 使用可能なテンプレートの完全な一覧については、アナライザー テンプレートに関するページを参照してください。
[作成] を選択します
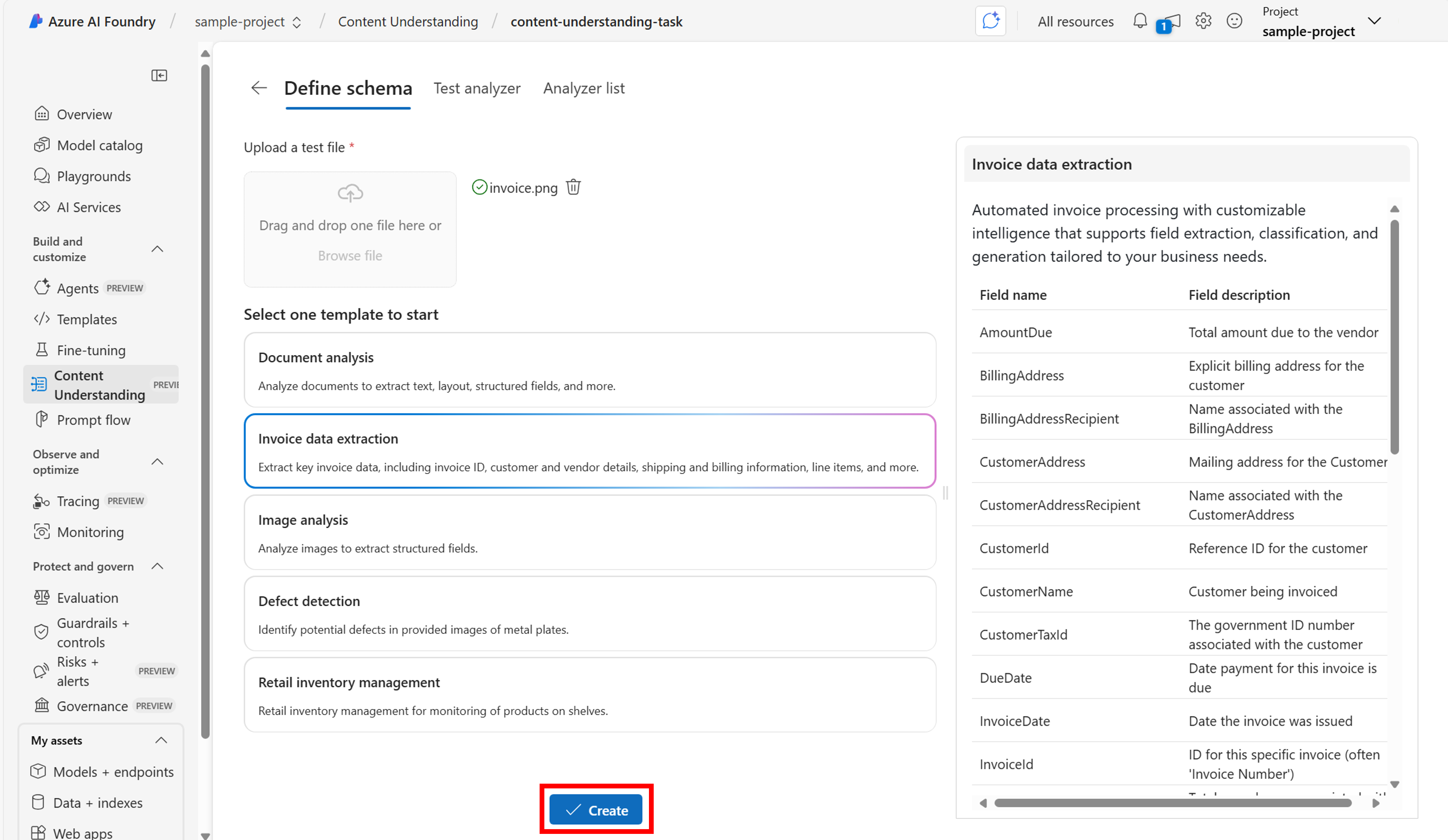
次に、生成するすべての出力を反映するフィールドをスキーマに追加します。
明確でシンプルなフィールド名を指定します。 フィールドの例としては、vendorName、items、price などがあります。
フィールドごとに値の型 (strings、dates、numbers、lists、groups) を示します。 詳細については、サポートされているフィールドの種類に関するページを参照してください。
[省略可能] フィールドの説明を入力して、例外や規則を含む目的の動作を示します。
各フィールドの値を生成する方法を指定します。
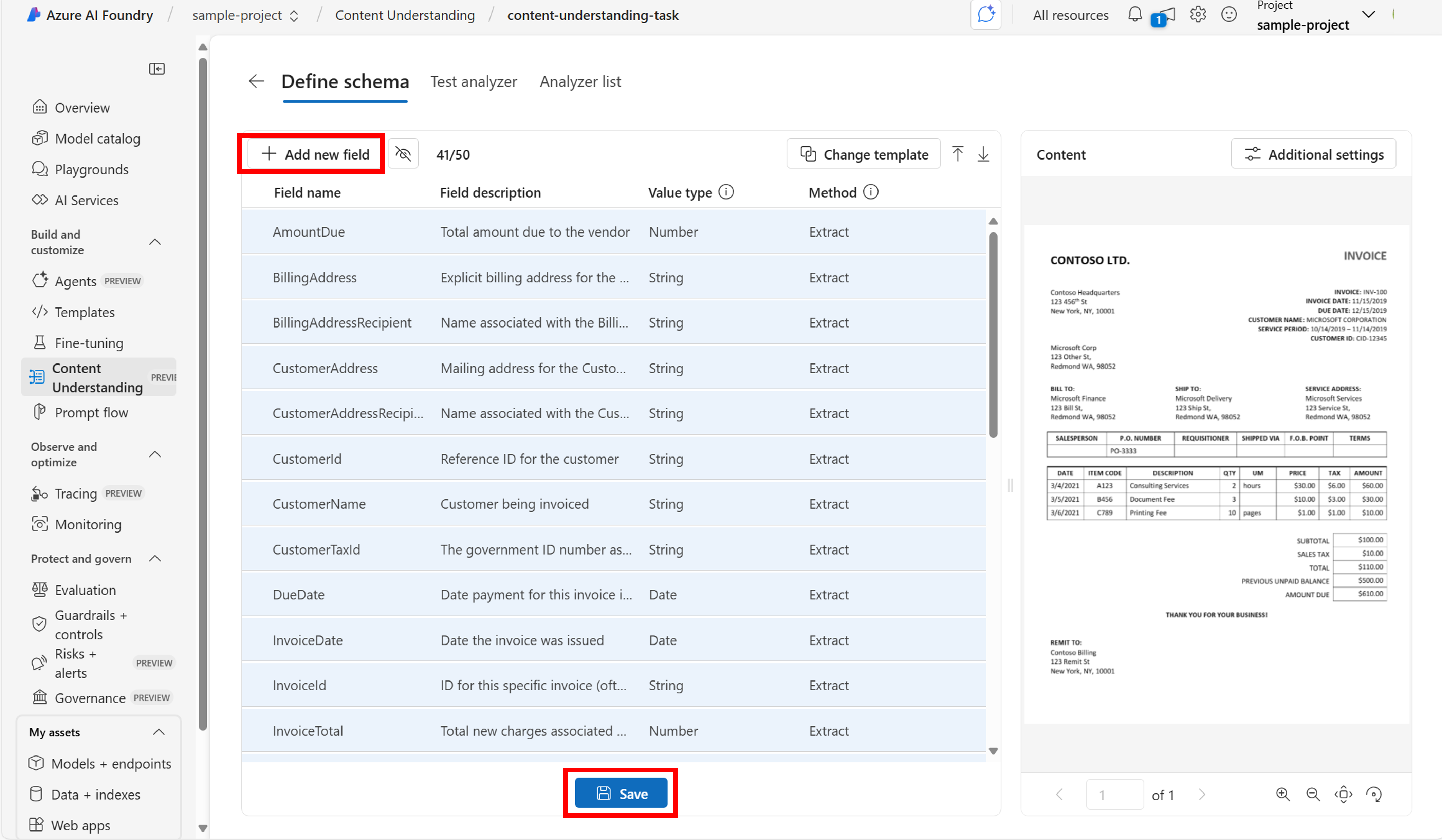
フィールド スキーマを定義する方法のベスト プラクティスについては、 Azure AI Content Understanding のベスト プラクティスを参照してください。 スキーマの構築には数分かかる場合があります。
スキーマをテストする準備ができたら、[ 保存] を選択します。 いつでも戻って、必要に応じて変更を加えることができます。
完成したスキーマを使用して、コンテンツの解釈で、サンプル データの出力を生成できるようになりました。 このステップでは、さらにデータを追加してアナライザーの正確性をテストし、必要に応じてスキーマを変更することができます。
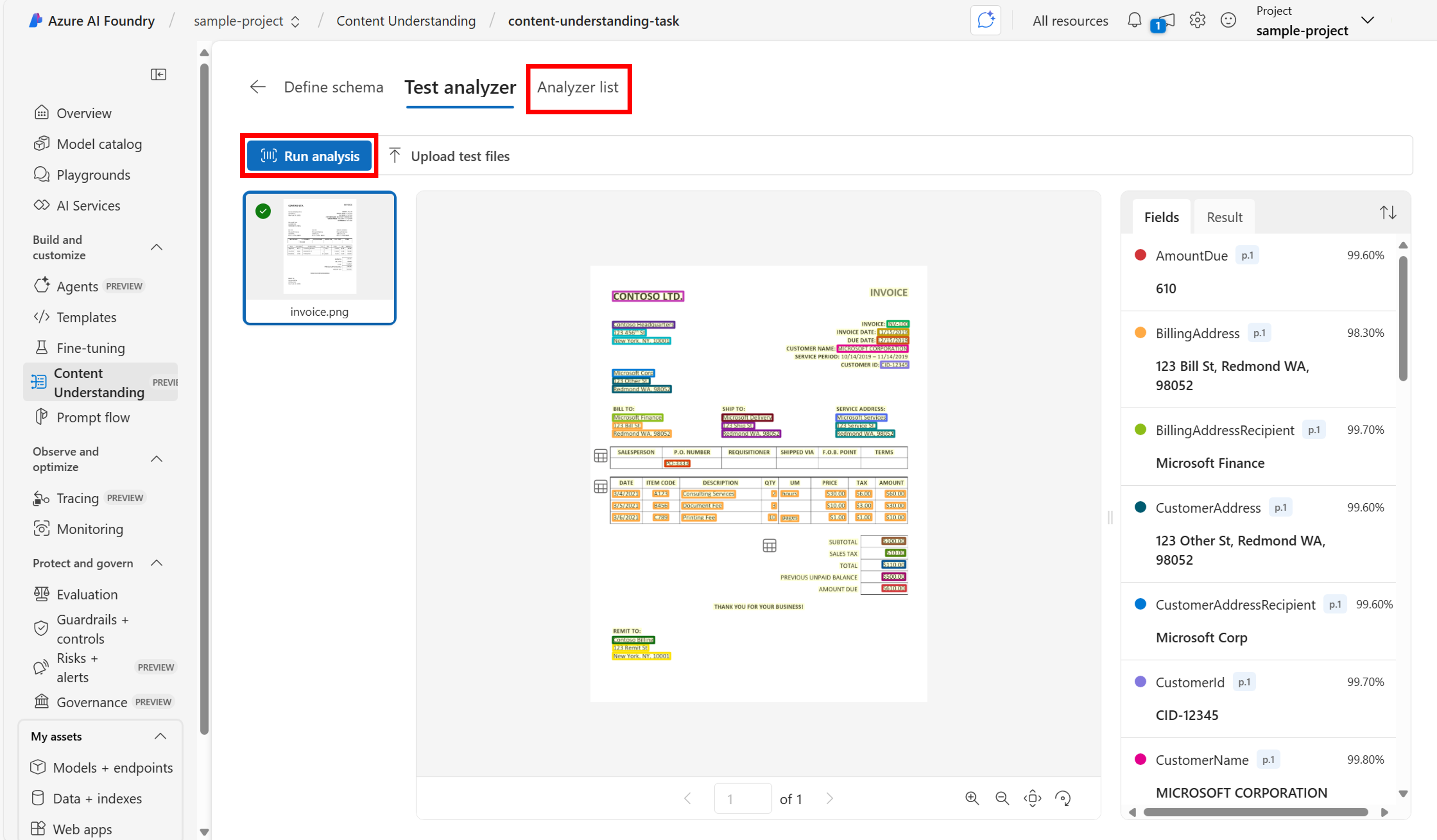
出力の品質に問題がなければ、[ Build analyzer] を選択します。 この操作により、独自のアプリケーションに統合できるアナライザー ID が作成され、コードからアナライザーを呼び出すことができるようになります。
最初の Content Understanding アナライザーが正常に構築され、データから分析情報の抽出を開始する準備が整いました。 REST API を使用してアナライザーを呼び出すには、「クイックスタート: Azure AI コンテンツの解釈 REST API」を参照してください。
プロジェクトの共有
作成したプロジェクトを共有し、アクセスを管理するには、管理センターに移動します。 プロジェクトのナビゲーション ウィンドウの下部にあります。
![[管理センター] の場所を示すスクリーンショット。](../media/quickstarts/cu-landing-page.png)
管理センターでは、ユーザーを管理し、個々のロールを割り当てることができます。
![管理センターの [プロジェクト ユーザー] セクションのスクリーンショット。](../media/quickstarts/management-center.png)
次のステップ
- Azure AI Foundry での アナライザー テンプレートの 作成と使用の詳細について説明します。