クエリフェデレーションでは、JDBC API を使用してクエリが外部データベースにプッシュダウンされます。 クエリは、Databricks とリモート コンピューティングの両方で実行されます。 クエリ フェデレーションは、MySQL、PostgreSQL、BigQuery、Redshift、Teradata などのソースに使用されます。
Lakehouse フェデレーションを使用する理由
Lakehouse は、データの冗長性と分離を減らすために、データの中央ストレージを強調しています。 組織には運用環境に多数のデータ システムがあり、接続されたシステムのデータに対してさまざまな理由でクエリを実行する必要がある場合があります。
- オンデマンド レポート。
- 概念実証作業。
- 新しい ETL パイプラインまたはレポートの探索フェーズ。
- 段階的移行中のワークロードのサポート。
これらの各シナリオでは、クエリ フェデレーションを使用すると、適切な場所でデータをクエリでき、複雑で時間のかかる ETL 処理を回避できるため、より迅速に分析情報を得ることができます。
クエリ フェデレーションは、次の場合のユース ケースを対象としています。
- Azure Databricks にデータを取り込む必要はありません。
- クエリで外部データベース システムのコンピューティングを利用したいと考えています。
- Unity Catalog インターフェイスと、きめ細かいアクセス制御、データ系統、検索などのデータ ガバナンスの利点を必要としています。
クエリ フェデレーションと Lakeflow Connect
クエリフェデレーションを使用すると、データを移動せずに外部データ ソースに対してクエリを実行できます。 Databricks では、マネージド コネクタを使用してインジェストすることをお勧めします。これは、高いデータ 量、待機時間の短いクエリ、サードパーティの API の制限に対応するためにスケーリングされるためです。 ただし、データを移動せずにクエリを実行する必要があります。 マネージド インジェスト コネクタとクエリ フェデレーションのどちらかを選択する場合は、ETL パイプラインでのアドホック レポートまたは概念実証作業のクエリ フェデレーションを選択します。
クエリフェデレーションのセットアップの概要
Lakehouse フェデレーションを使用してデータセットを読み取り専用でクエリできるようにするには、次のものを作成します。
- 外部データベース システムにアクセスするためのパスと資格情報を指定する、Unity カタログ内のセキュリティ保護可能なオブジェクトである接続。
- 外部カタログ。外部データ システム内のデータベースをミラー化する Unity カタログ内のセキュリティ保護可能なオブジェクトです。これにより、Azure Databricks ワークスペースでそのデータ システムに対して読み取り専用クエリを実行し、Unity カタログを使用してアクセスを管理できます。
サポートされるデータ ソース
クエリ フェデレーションでは、次のソースへの接続がサポートされています。
- MySQL
- PostgreSQL
- Teradata
- Oracle
- Amazon Redshift
- Salesforce Data Cloud
- Snowflake
- Microsoft SQL Server
- Azure Synapse (SQL Data Warehouse)
- Google BigQuery
- Databricks
接続の要件
ワークスペースの要件:
- Unity Catalog を使用できるワークスペース。
コンピューティング要件:
- コンピューティング リソースからターゲット データベース システムへのネットワーク接続。 「レイクハウス フェデレーションのためのネットワークに関する推奨事項」を参照してください。
- Azure Databricks コンピューティングでは、Databricks Runtime 13.3 LTS 以降を使用し、Standard または デディケート アクセス モードを使用する必要があります。
- SQL ウェアハウスはプロまたはサーバーレスである必要があり、2023.40 以降を使用する必要があります。
必要なアクセス許可:
- 接続を作成するには、メタストア管理者であるか、ワークスペースにアタッチされている Unity カタログメタストアに対する
CREATE CONNECTION権限を持つユーザーである必要があります。 - 外部カタログを作成するには、メタストアに対する
CREATE CATALOG権限を持ち、接続の所有者であるか、接続に対するCREATE FOREIGN CATALOG特権を持っている必要があります。
追加の権限要件は、以下の各タスク ベースのセクションで規定されています。
接続を作成する
接続では、外部データベース システムにアクセスするためのパスと資格情報を指定します。 接続を作成するには、Azure Databricks ノートブックまたは Databricks SQL クエリ エディターでカタログ エクスプローラーまたは CREATE CONNECTION SQL コマンドを使用できます。
Note
Databricks REST API または Databricks CLI を使用して接続を作成することもできます。 POST /api/2.1/unity-catalog/connections および Unity Catalog コマンドを参照してください。
必要な権限: メタストア管理者、または CREATE CONNECTION 特権を持つユーザー。
カタログ エクスプローラー
Azure Databricks ワークスペースで、[
![データ] アイコンをクリックします。](../_static/images/product-icons/dataicon.svg) カタログ。
カタログ。[カタログ] ペインの上部にある
 [追加] アイコンをクリックし、メニューから [接続の追加] を選択します。
[追加] アイコンをクリックし、メニューから [接続の追加] を選択します。または、[クイック アクセス] ページで、[外部データ >] ボタンをクリックし、[接続] タブに移動し、[接続の作成] をクリックします。
わかりやすい接続名を入力します。
[接続の種類] (MySQL や PostgreSQL などのデータベース プロバイダー) を選択します。
(省略可能)コメントを追加します。
[次へ] をクリックします。
接続プロパティ (ホスト情報、パス、アクセス資格情報など) を入力します。
接続の種類ごとに異なる接続情報が必要になります。 左側の目次に記載されている、接続の種類に応じた記事を参照してください。
[接続の作成] をクリックします。
外部カタログの名前を入力します。
(省略可能) [接続のテスト] をクリックして、動作することを確認します。
カタログを作成 をクリックします。
作成したカタログにユーザーがアクセスできるワークスペースを選択します。 [すべてのワークスペースにアクセス権を持たせる] を選択するか、[ワークスペースへの割り当て] をクリックしてワークスペースを選択し、[割り当て] をクリックします。
カタログ内のすべてのオブジェクトへのアクセスを管理できる 所有者 を変更します。 テキストボックスに主要項目を入力し、表示された結果からその項目をクリックします。
カタログに関する権限 を付与します。 [許可] をクリックします。
- カタログ内のオブジェクトにアクセスできる プリンシパル を指定します。 テキストボックスに主要項目を入力し、表示された結果からその項目をクリックします。
- 各プリンシパルに付与する 特権プリセット を選択します。 既定では、すべてのアカウント ユーザーに
BROWSEが付与されます。- ドロップダウン メニューから [データ 閲覧者 を選択して、カタログ内のオブジェクトに対する
read権限を付与します。 - ドロップダウン メニュー データ エディター を選択して、カタログ内のオブジェクトに対する
read権限とmodify権限を付与します。 - 付与する特権を手動で選択します。
- ドロップダウン メニューから [データ 閲覧者 を選択して、カタログ内のオブジェクトに対する
- [許可] をクリックします。
- [次へ] をクリックします。
- [メタデータ] ページで、タグのキーと値のペアを指定します。 詳細については、「Unity カタログのセキュリティ保護可能なオブジェクトにタグを適用する」を参照してください。
- (省略可能)コメントを追加します。
- [保存] をクリックします。
SQL
ノートブックまたは SQL クエリ エディターで次のコマンドを実行します。 この例は、PostgreSQL データベースへの接続を対象としています。 オプションは接続の種類によって異なります。 左側の目次に記載されている、接続の種類に応じた記事を参照してください。
CREATE CONNECTION <connection-name> TYPE postgresql
OPTIONS (
host '<hostname>',
port '<port>',
user '<user>',
password '<password>'
);
資格情報などの機密性の高い値には、プレーンテキストの文字列ではなく Azure Databricks のシークレットを使用することをお勧めします。 例えば次が挙げられます。
CREATE CONNECTION <connection-name> TYPE postgresql
OPTIONS (
host '<hostname>',
port '<port>',
user secret ('<secret-scope>','<secret-key-user>'),
password secret ('<secret-scope>','<secret-key-password>')
)
シークレットの設定については、「シークレットの管理」を参照してください。
既存の接続の管理については、「Lakehouse フェデレーションの接続の管理」を参照してください。
外部カタログを作成する
Note
UI を使用してデータ ソースへの接続を作成する場合は、外部カタログの作成が含まれるので、この手順は省略できます。
外部カタログは、外部データ システム内のデータベースをミラー化して、Azure Databricks と Unity Catalog を使用してそのデータベース内のデータへのアクセスを照会および管理できるようにします。 外部カタログを作成するには、既に定義されているデータ ソースへの接続を使用します。
外部カタログを作成するには、Azure Databricks ノートブックまたは SQL クエリ エディターでカタログ エクスプローラーまたは CREATE FOREIGN CATALOG SQL コマンドを使用できます。 Unity Catalog API を使用することもできます。 「Azure Databricks リファレンス ドキュメント」を参照してください。
外部カタログ メタデータは、カタログとのやり取りごとに Unity Catalog に同期されます。 Unity カタログとデータ ソースの間のデータ型マッピングについては、各データ ソースのドキュメントの 「データ型マッピング 」セクションを確認してください。
必要な権限: メタストアに対するCREATE CATALOG 権限と、接続の所有権または接続に対する CREATE FOREIGN CATALOG 特権。
カタログ エクスプローラー
Azure Databricks ワークスペースで、[
カタログ をクリックしてカタログ エクスプローラーを開きます。[カタログ] ウィンドウの上部にある [
[データの追加] アイコンをクリックし、メニューから [カタログの作成] を選択します。または、[クイック アクセス] ページで、[カタログ] ボタンをクリックし、[カタログの作成] ボタンをクリックします。
「カタログを作成する」で外部カタログを作成する手順に従います。
SQL
ノートブックまたは SQL クエリ エディターで次の SQL コマンドを実行します。 角かっこ内の項目は省略可能です。 プレースホルダー値を次のように置き換えます。
-
<catalog-name>: Azure Databricks のカタログの名前。 -
<connection-name>: データ ソース、パス、アクセス資格情報を指定する接続オブジェクト。 -
<database-name>: Azure Databricks でカタログとしてミラーリングするデータベースの名前。 2 層の名前空間を使用する MySQL には必要ありません。 -
<external-catalog-name>: Databricks-to-Databricks のみ: ミラーリングしている外部の Databricks ワークスペースのカタログ名。 「外部カタログを作成する」を参照してください。
CREATE FOREIGN CATALOG [IF NOT EXISTS] <catalog-name> USING CONNECTION <connection-name>
OPTIONS (database '<database-name>');
外部カタログの管理と操作については、「外部カタログの管理と操作」を参照してください。
具体化されたビューを使用して外部テーブルからデータを読み込む
Databricks では、具体化されたビューを作成するときに、クエリ フェデレーションを使用して外部データを読み込うことをお勧めします。 具体化されたビューを参照してください。
クエリ フェデレーションを使用すると、ユーザーは次のようにフェデレーション データを参照できます。
CREATE MATERIALIZED VIEW xyz AS SELECT * FROM federated_catalog.federated_schema.federated_table;
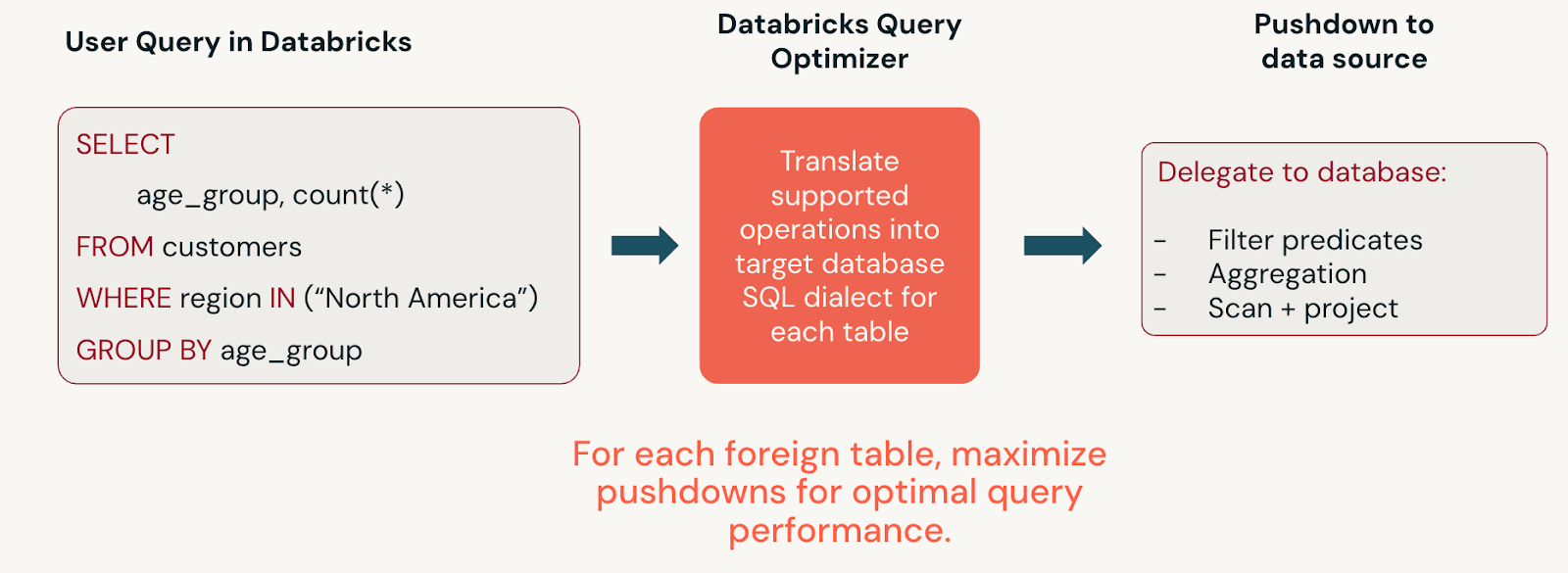
システム生成フェデレーション クエリを表示する
クエリ フェデレーションは、Databricks SQL ステートメントを、フェデレーション データ ソースにプッシュダウンできるステートメントに変換します。 生成された SQL ステートメントを表示するには、クエリ プロファイル のグラフ ビューで外部データ ソース スキャン ノードクリックするか、EXPLAIN FORMATTED SQL ステートメントを実行します。 対象範囲については、各データ ソースのドキュメントの「 サポートされているプッシュダウン 」セクションを参照してください。
Limitations
クエリは読み取り専用です。
唯一の例外は、ワークスペースのレガシ Hive メタストア (カタログ フェデレーション) のフェデレーションに Lakehouse Federation を使用する場合です。 そのシナリオの外部テーブルは書き込み可能です。 フェデレーション Hive メタストアの外部カタログに書き込む場合の意味を参照してください。
接続のスロットリングは、Databricks SQL の同時クエリ制限を使用して決定されます。 ウェアハウス間の接続ごとの制限はありません。 「キューと自動スケールのロジック」を参照してください。
Unity Catalog で無効な名前を持つテーブルとスキーマはサポートされておらず、外部カタログの作成時に Unity Catalog によって無視されます。 命名規則と制限事項の一覧については、「制限事項」を参照してください。
Unity カタログでは、テーブル名とスキーマ名は小文字に変換されます。 これにより名前の競合が発生した場合、Databricks は外部カタログにインポートされるオブジェクトを保証できません。
参照される外部テーブルごとに、Databricks はリモート システム内のサブクエリをスケジュールして、そのテーブルからデータのサブセットを返し、その結果を 1 つのストリームで 1 つの Databricks Executor タスクに返します。 結果セットが大きすぎると、Executor がメモリ不足になる可能性があります。
専用アクセス モード (以前のシングル ユーザー アクセス モード) は、接続を所有するユーザーのみが使用できます。
Lakehouse Federation では、Azure Synapse 接続または Redshift 接続の大文字と小文字を区別する識別子を持つ外部テーブルをフェデレーションすることはできません。
リソース クォータ
Azure Databricks は Unity Catalog のセキュリティ保護可能なすべてのオブジェクトにリソース クォータを実施されます。 これらのクォータは、リソースの制限に記載されています。 外部カタログとそのカタログに含まれるすべてのオブジェクトは、クォータ使用量の合計に含まれます。
これらのリソース制限を超えることが予想される場合は、Azure Databricks アカウント チームにお問い合わせください。
Unity Catalog リソース クォータ API を使用して、クォータの使用状況を監視できます。 「 Unity Catalog リソース クォータの使用状況の監視」を参照してください。