適用対象: Azure CLI ml 拡張機能 v2 (現在)Python SDK azure-ai-ml v2 (現在)
Azure CLI ml 拡張機能 v2 (現在)Python SDK azure-ai-ml v2 (現在)
機械学習モデルまたはパイプラインをトレーニングした後、またはモデル カタログから適切なモデルを見つけたら、それらを運用環境にデプロイして、他のユーザーが 推論に使用できるようにする必要があります。 推論とは、機械学習モデルまたはパイプラインに新しい入力データを適用して出力を生成するプロセスです。 通常、これらの出力は "予測" と呼ばれますが、推論では、分類やクラスタリングなどの他の機械学習タスクの出力を生成できます。 Azure Machine Learning では、エンドポイントを使用して推論 を実行します。
エンドポイントとデプロイ
エンドポイントは、モデルの要求または呼び出しに使用できる安定した永続的な URL です。 エンドポイントに必要な入力を指定し、出力を受け取ります。 Azure Machine Learning では、標準デプロイ、オンライン エンドポイント、バッチ エンドポイントがサポートされます。 エンドポイントから提供されるもの:
- 安定した永続的な URL ( endpoint-name.region.inference.ml.azure.com など)
- 認証メカニズム
- 承認メカニズム
デプロイは、実際の推論を実行するモデルまたはコンポーネントをホストするために必要なリソースとコンピューティングのセットです。 エンドポイントにはデプロイが含まれています。 オンライン エンドポイントとバッチ エンドポイントの場合、1 つのエンドポイントに複数のデプロイを含めることができます。 デプロイでは、独立した資産をホストし、資産のニーズに基づいてさまざまなリソースを使用できます。 エンドポイントには、任意のデプロイに要求を送信できるルーティング メカニズムもあります。
Azure Machine Learning の一部の種類のエンドポイントでは、デプロイに専用のリソースが使用されます。 これらのエンドポイントを実行するには、Azure サブスクリプションにコンピューティング クォータが必要です。 ただし、一部のモデルではサーバーレスデプロイがサポートされているため、サブスクリプションからのクォータを使用できません。 サーバーレス展開の場合、使用量に基づいて課金されます。
Intuition
写真から車の種類と色を予測するアプリケーションに取り組んでいるとします。 このアプリケーションでは、特定の資格情報を持つユーザーが URL に対して HTTP 要求を行い、その要求の一部として自動車の画像を提供します。 その代わりに、ユーザーは車の種類と色を文字列値として含む応答を受け取ります。 このシナリオでは、URL はエンドポイントとして機能 します。
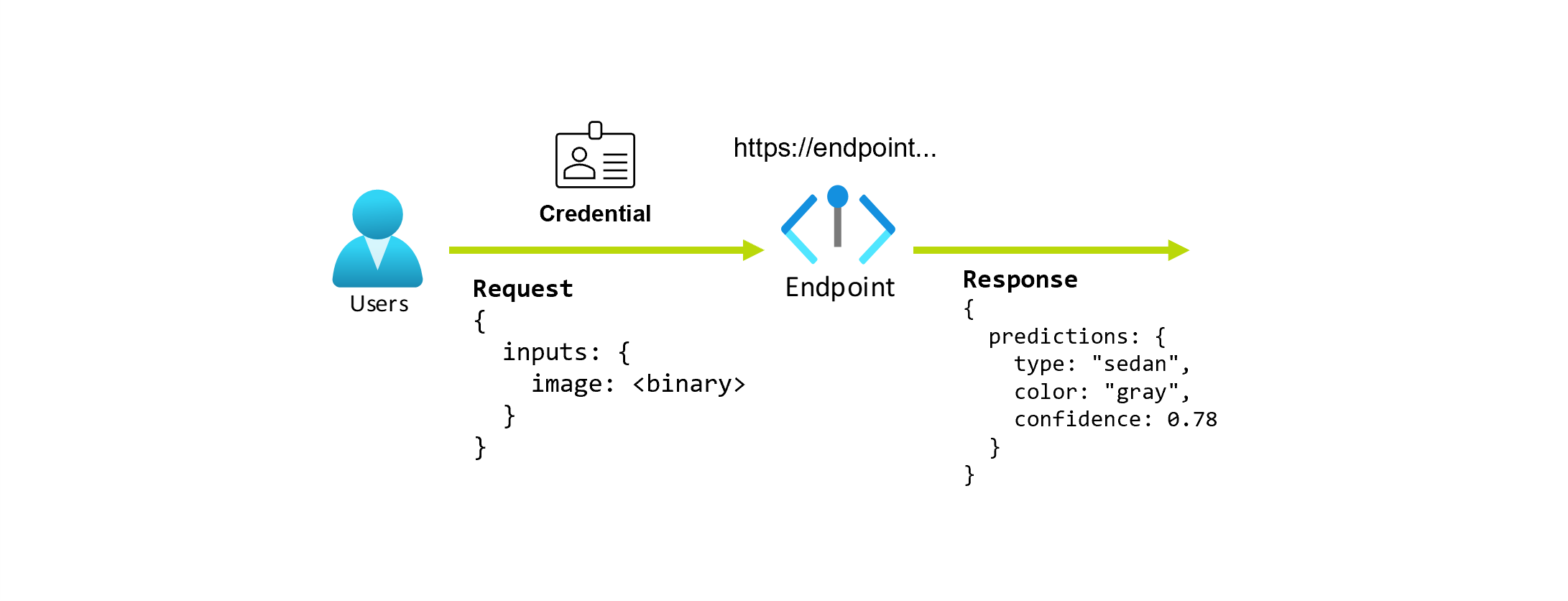
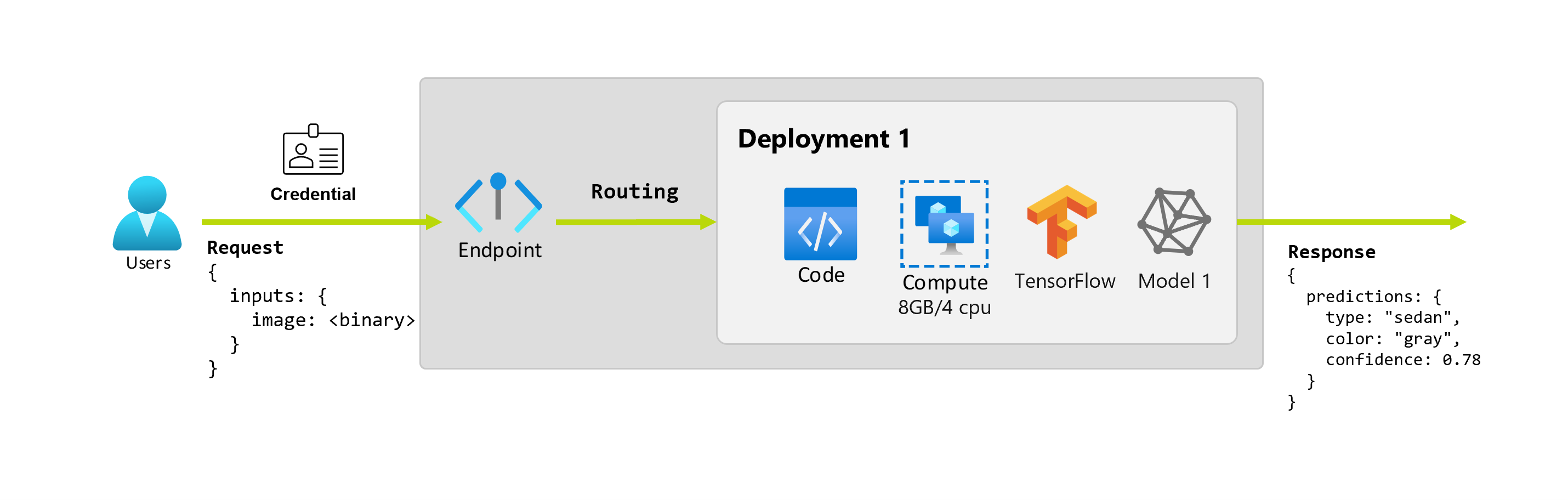
次に、データ サイエンティストの Alice がアプリケーションを実装しているとします。 Alice には豊富な TensorFlow エクスペリエンスがあり、TensorFlow Hub の ResNet アーキテクチャを使用して Keras シーケンシャル分類子を使用してモデルを実装することにしました。 モデルをテストした後、Alice はその結果に満足し、モデルを使用して車の予測問題を解決することにしました。 モデルは大きく、実行するには 4 コアの 8 GB のメモリが必要です。 このシナリオでは、Alice のモデルと、モデルを実行するために必要なリソース (コードやコンピューティングなど) が エンドポイントの下にデプロイを構成します。
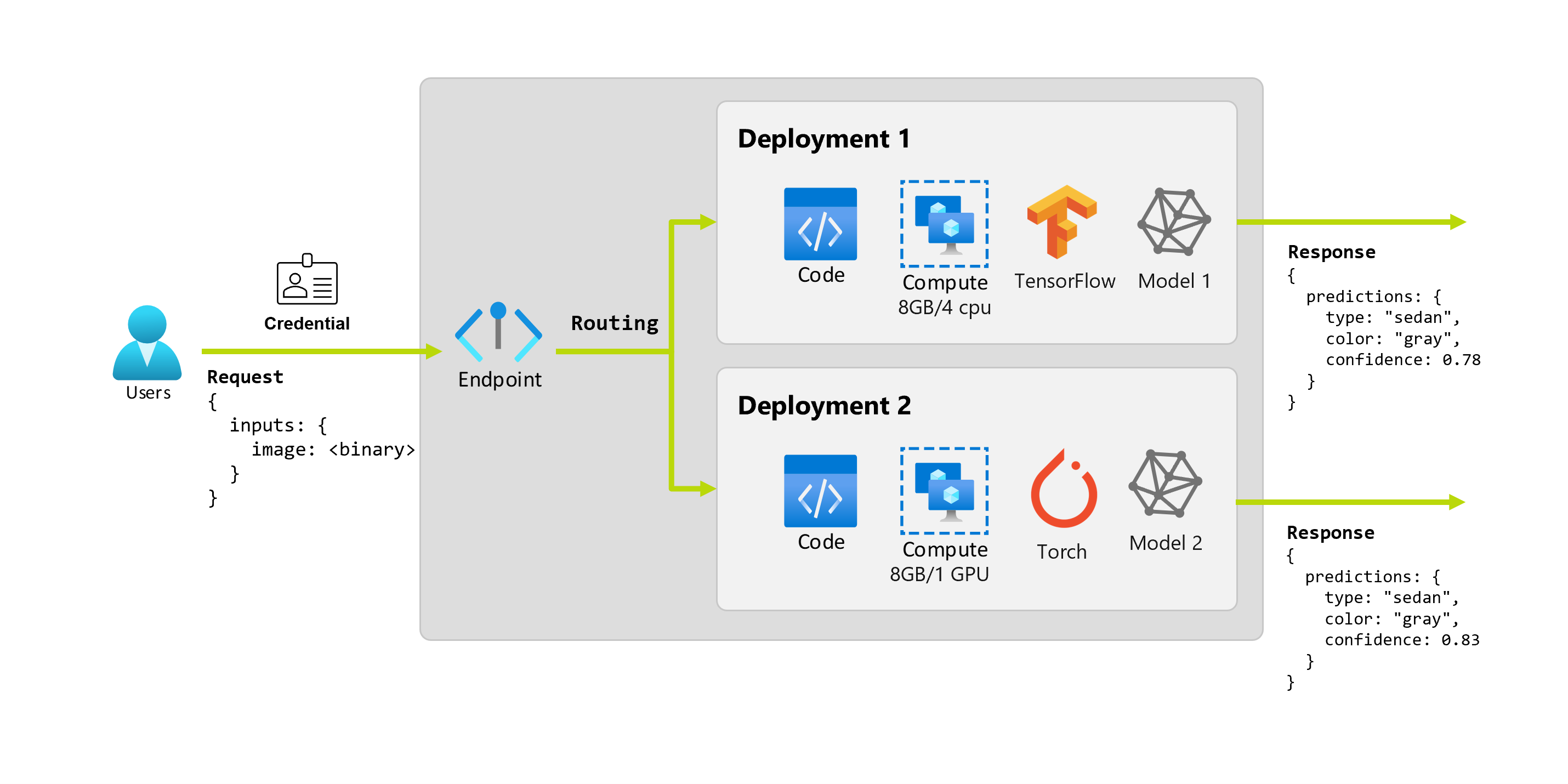
数か月後、組織は、照明条件の悪い画像に対してアプリケーションのパフォーマンスが低下していることを検出します。 もう 1 人のデータ サイエンティストである Bob は、モデルがこの要素の堅牢性を構築するのに役立つデータ拡張手法に関する専門知識を持っています。 ただし、Bob は PyTorch を使用してモデルを実装し、PyTorch で新しいモデルをトレーニングすることを好みます。 Bob は、組織が古いモデルを廃止する準備ができるまで、運用環境でこのモデルを段階的にテストしたいと考えています。 新しいモデルは GPU にデプロイするとパフォーマンスも向上するため、デプロイには GPU を含める必要があります。 このシナリオでは、Bob のモデルと、モデルを実行するために必要なリソース (コードやコンピューティングなど) が 、同じエンドポイントの下に別のデプロイを構成します。
エンドポイント: 標準デプロイ、オンライン、バッチ
Azure Machine Learning では、 標準デプロイ、 オンライン エンドポイント、 バッチ エンドポイントがサポートされます。
標準デプロイ と オンライン エンドポイント は、リアルタイム推論用に設計されています。 エンドポイントを呼び出すと、エンドポイントの応答で結果が返されます。 標準デプロイでは、サブスクリプションからのクォータは使用されません。代わりに、標準請求で課金されます。
バッチ エンドポイントは、 実行時間の長いバッチ推論用に設計されています。 バッチ エンドポイントを呼び出すと、実際の作業を実行するバッチ ジョブが生成されます。
標準デプロイ、オンライン、バッチ エンドポイントを使用する場合
標準デプロイ:
標準デプロイを使用して、大規模な基本モデルを使用して、既製のリアルタイム推論や、そのようなモデルの微調整を行います。 すべてのモデルを標準デプロイにデプロイできるわけではありません。 次の場合は、このデプロイ モードを使うことをお勧めします。
- モデルは、標準デプロイで使用できる基本モデルまたは微調整された基本モデルです。
- クォータのないデプロイにメリットがあります。
- モデルの実行に使用する推論スタックをカスタマイズする必要はありません。
オンライン エンドポイント:
オンライン エンドポイントを使用して、同期的な低待機時間要求でリアルタイム推論のモデルを運用化します。 次の場合に使用することをお勧めします。
- モデルは基本モデルまたは基本モデルの微調整されたバージョンですが、標準デプロイではサポートされていません。
- 低遅延の要件がある。
- モデルが比較的短時間で要求に応答できる。
- モデルの入力は、要求の HTTP ペイロードに収まります。
- 要求の数についてスケールアップする必要があります。
バッチ エンドポイント:
バッチ エンドポイントを使用して、実行時間の長い非同期推論のモデルまたはパイプラインを運用化します。 次の場合に使用することをお勧めします。
- 実行に長い時間がかかるコストの高いモデルまたはパイプラインがある。
- 機械学習パイプラインを運用化し、コンポーネントを再利用したいと考えている。
- 複数のファイルに分散されている大量のデータに対して推論を実行する必要があります。
- 低遅延を必要としない
- モデルの入力は、ストレージ アカウントまたは Azure Machine Learning データ資産に格納されます。
- 並列処理の恩恵を受けることができる
標準デプロイ、オンライン、バッチ エンドポイントの比較
すべての標準デプロイ、オンライン エンドポイント、バッチ エンドポイントはエンドポイントの概念に基づいているため、1 つから他方に簡単に移行できます。 オンラインおよびバッチ エンドポイントには、同じエンドポイントの複数のデプロイを管理する機能もあります。
Endpoints
次の表は、標準デプロイ、オンライン エンドポイント、およびエンドポイント レベルでのバッチ エンドポイントで使用できるさまざまな機能の概要を示しています。
| Feature | 標準デプロイ | オンライン エンドポイント | Batch エンドポイント |
|---|---|---|---|
| 安定した呼び出し URL | Yes | Yes | Yes |
| 複数のデプロイのサポート | No | Yes | Yes |
| デプロイのルーティング | None | トラフィックの分割 | 既定値への切り替え |
| 安全なロールアウトのためのトラフィックのミラーリング | No | Yes | No |
| Swagger のサポート | Yes | Yes | No |
| Authentication | Key | キーと Microsoft Entra ID (プレビュー) | Microsoft Entra ID |
| プライベート ネットワークのサポート (レガシ) | No | Yes | Yes |
| マネージド ネットワーク分離 | Yes | Yes | はい (必要な追加構成を参照) |
| カスタマー マネージド キー | NA | Yes | Yes |
| コスト基準 | エンドポイントごと、分あたり1 | None | None |
11 分あたりの標準デプロイには、小さな分数が課金されます。 使用量に関連する料金については、「 デプロイ 」セクションを参照してください。これはトークンごとに課金されます。
Deployments
次の表は、デプロイ レベルで標準デプロイ、オンライン エンドポイント、バッチ エンドポイントで使用できるさまざまな機能の概要を示しています。 これらの概念は、エンドポイントの下の各デプロイ (オンラインおよびバッチ エンドポイントの場合) に適用され、標準デプロイ (デプロイの概念がエンドポイントに組み込まれている) に適用されます。
| Feature | 標準デプロイ | オンライン エンドポイント | Batch エンドポイント |
|---|---|---|---|
| 展開タイプ | Models | Models | モデルとパイプライン コンポーネント |
| MLflow モデル デプロイ | なし。カタログ内の特定のモデルのみ | Yes | Yes |
| カスタム モデル デプロイ | なし。カタログ内の特定のモデルのみ | はい (スコアリング スクリプトを使用) | はい (スコアリング スクリプトを使用) |
| 推論サーバー 3 | Azure AI モデル推論 API | - Azure Machine Learning 推論サーバー -トライトン - カスタム (BYOC を使用) |
バッチ推論 |
| 使用されるコンピューティング リソース | なし (サーバーレス) | インスタンスまたは詳細なリソース | クラスター インスタンス |
| コンピューティングの種類 | なし (サーバーレス) | マネージド コンピューティングと Kubernetes | マネージド コンピューティングと Kubernetes |
| 優先順位の低いコンピューティング | NA | No | Yes |
| コンピューティングをゼロにスケーリングする | Built-in | No | Yes |
| 自動スケール コンピューティング4 | Built-in | はい (リソースの使用に基づく) | はい (ジョブ数に基づく) |
| 過剰な能力の管理 | Throttling | Throttling | Queuing |
| コスト基準5 | トークンごと | デプロイごと: 実行中のコンピューティング インスタンス | ジョブごと: ジョブで使用されたコンピューティング インスタンス (クラスターのインスタンスの最大数に制限されます) |
| デプロイのローカル テスト | No | Yes | No |
2推論サーバー は、要求を受け取り、処理し、応答を作成するサービス テクノロジを指します。 推論サーバーでは、入力の形式と予想される出力も指定されます。
3自動スケール は、負荷に基づいてデプロイの割り当てられたリソースを動的にスケールアップまたはスケールダウンする機能です。 オンライン デプロイとバッチ デプロイでは、自動スケーリングにさまざまな戦略が使用されます。 オンライン デプロイではリソース使用率 (CPU、メモリ、要求など) に基づいてスケールアップおよびスケールダウンしますが、バッチ エンドポイントでは作成されたジョブの数に基づいてスケールアップまたはスケールダウンします。
4 オンラインデプロイとバッチデプロイの両方が、消費されたリソースによって課金されます。 オンライン デプロイでは、デプロイ時にリソースがプロビジョニングされます。 バッチ デプロイでは、リソースはデプロイ時ではなく、ジョブの実行時に消費されます。 そのため、バッチ デプロイ自体に関連するコストはありません。 同様に、キューに登録されたジョブでもリソースは消費されません。
開発者インターフェイス
エンドポイントは、組織が運用レベルのワークロードを Azure Machine Learning で操作できるように設計されています。 エンドポイントは堅牢でスケーラブルなリソースであり、MLOps ワークフローを実装するのに最適な機能を提供します。
複数の開発者ツールを使って、バッチ エンドポイントとオンライン エンドポイントを作成および管理できます。
- Azure CLI と Python SDK
- Azure Resource Manager/REST API
- Azure Machine Learning スタジオ Web ポータル
- Azure portal (IT および管理者)
- Azure CLI インターフェイスと REST および ARM インターフェイスを使用した、CI/CD MLOps パイプラインのサポート