適用対象: Azure CLI ml extension v2 (現行)Python SDK azure-ai-ml v2 (現行)
Azure CLI ml extension v2 (現行)Python SDK azure-ai-ml v2 (現行)
この記事では、リアルタイム推論で使うためにモデルをオンライン エンドポイントにデプロイする方法について説明します。 まずローカル コンピューターにモデルをデプロイして、発生するエラーをデバッグします。 次に、Azure でそのモデルをデプロイしてテストし、デプロイ ログを表示し、サービス レベル アグリーメント (SLA) を監視します。 この記事の最後には、リアルタイム推論に使用できるスケーラブルな HTTPS/REST エンドポイントがあります。
オンライン エンドポイントは、リアルタイムの推論に使用されるエンドポイントです。 オンライン エンドポイントには、マネージド オンライン エンドポイントと Kubernetes オンライン エンドポイントの 2 種類があります。 相違点の詳細については、「 マネージド オンライン エンドポイントと Kubernetes オンライン エンドポイント」を参照してください。
マネージド オンライン エンドポイントは、ターンキー方式で機械学習モデルを展開するのに役立ちます。 マネージド オンライン エンドポイントは、スケーラブルでフル マネージドの方法で Azure の強力な CPU および GPU マシンと動作します。 マネージド オンライン エンドポイントは、モデルの提供、スケーリング、セキュリティ保護、監視を行います。 この支援により、基になるインフラストラクチャの設定と管理の手間から解放されます。
このアーティクルの主な例では、デプロイにマネージド オンライン エンドポイントを使用します。 代わりに Kubernetes を使用する場合は、マネージド オンライン エンドポイントに関する説明に沿って本ドキュメント内に記載されている注記を参照してください。
前提条件
適用対象:Azure CLI ml 拡張機能 v2 (現行)
Azure CLI と Azure CLI のml拡張機能(インストールおよび構成済み)。 詳細については、「 CLI のインストールと設定 (v2)」を参照してください。
Bash シェルまたは互換性のあるシェル (Linux システム上のシェルや Linux 用 Windows サブシステムなど)。 この記事の Azure CLI の例では、この種類のシェルを使用することを前提としています。
Azure Machine Learning ワークスペース。 ワークスペースを作成する手順については、「 設定」を参照してください。
Azure ロールベースのアクセス制御 (Azure RBAC) は、Azure Machine Learning の操作へのアクセスを許可するために使用されます。 この記事の手順を実行するには、Azure Machine Learning ワークスペースの所有者ロールまたは共同作成者ロールがユーザー アカウントに割り当てられているか、カスタム ロールで Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*を許可する必要があります。 Azure Machine Learning Studio を使用してオンライン エンドポイントまたはデプロイを作成および管理する場合は、リソース グループの所有者からの追加のアクセス許可 Microsoft.Resources/deployments/write 必要があります。 詳細については、「Azure Machine Learning ワークスペースへのアクセスの管理」を参照してください。
(省略可能) ロ―カルでデプロイするには、ローカル コンピューターに Docker エンジンをインストールする必要があります。 このオプション を強くお勧めします 。これにより、問題のデバッグが容易になります。
適用対象: Python SDK azure-ai-ml v2 (現行)
Azure Machine Learning ワークスペース。 ワークスペースを作成する手順については、「ワークスペースの 作成」を参照してください。
Azure Machine Learning SDK for Python v2。 SDK をインストールするには、次のコマンドを使用します。
pip install azure-ai-ml azure-identity
SDK の既存のインストールを最新バージョンに更新するには、次のコマンドを使用します。
pip install --upgrade azure-ai-ml azure-identity
詳細については、「 Python 用 Azure Machine Learning パッケージ クライアント ライブラリ」を参照してください。
Azure RBAC は、Azure Machine Learning の操作へのアクセスを許可するために使用されます。 この記事の手順を実行するには、Azure Machine Learning ワークスペースの所有者ロールまたは共同作成者ロールがユーザー アカウントに割り当てられているか、カスタム ロールで Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*を許可する必要があります。 詳細については、「Azure Machine Learning ワークスペースへのアクセスの管理」を参照してください。
(省略可能) ロ―カルでデプロイするには、ローカル コンピューターに Docker エンジンをインストールする必要があります。 このオプション を強くお勧めします 。これにより、問題のデバッグが容易になります。
この記事の手順に従う前に、次の前提条件があることを確認してください。
- Azure サブスクリプション。 Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。 無料版または有料版の Azure Machine Learning をお試しください。
- Azure Machine Learning ワークスペースとコンピューティング インスタンス。 これらのリソースがない場合は、「 開始する必要があるリソースの作成」を参照してください。
- Azure RBAC は、Azure Machine Learning の操作へのアクセスを許可するために使用されます。 この記事の手順を実行するには、Azure Machine Learning ワークスペースの所有者ロールまたは共同作成者ロールがユーザー アカウントに割り当てられているか、カスタム ロールで
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*を許可する必要があります。 詳細については、「Azure Machine Learning ワークスペースへのアクセスの管理」を参照してください。
これらの手順では、機械学習用の Azure CLI と CLI 拡張機能を使用しますが、主な焦点ではありません。 これらは、テンプレートを Azure に渡し、テンプレートのデプロイの状態を確認するためのユーティリティとしてより多く使用されています。
Azure CLI と Azure CLI のml拡張機能(インストールおよび構成済み)。 詳細については、「 CLI のインストールと設定 (v2)」を参照してください。
Bash シェルまたは互換性のあるシェル (Linux システム上のシェルや Linux 用 Windows サブシステムなど)。 この記事の Azure CLI の例では、この種類のシェルを使用することを前提としています。
Azure Machine Learning ワークスペース。 ワークスペースを作成する手順については、「 設定」を参照してください。
- Azure RBAC は、Azure Machine Learning の操作へのアクセスを許可するために使用されます。 この記事の手順を実行するには、Azure Machine Learning ワークスペースの所有者ロールまたは共同作成者ロールがユーザー アカウントに割り当てられているか、カスタム ロールで
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*を許可する必要があります。 詳細については、「Azure Machine Learning ワークスペースへのアクセスの管理」を参照してください。
デプロイ用に十分な仮想マシン (VM) クォータが割り当てられていることを確認してください。 Azure Machine Learning では、一部の VM バージョンでアップグレードを実行するために、コンピューティング リソースの% が 20 個予約されています。 たとえば、デプロイで 10 個のインスタンスを要求する場合、VM バージョンのコア数ごとに 12 個のクォータが必要です。 この追加分のコンピューティング リソースを考慮していないと、エラーが発生します。 一部の VM バージョンは、追加のクォータ予約から除外されます。 クォータの割り当ての詳細については、「 デプロイのための仮想マシン クォータの割り当て」を参照してください。
または、限られた時間、Azure Machine Learning 共有クォータ プールからのクォータを使用することもできます。 Azure Machine Learning には共有クォータ プールが用意されており、さまざまなリージョンのユーザーが、可用性に応じて、そのクォータにアクセスして限られた時間だけテストを実行できます。
スタジオを使ってモデル カタログから Llama-2、Phi、Nemotron、Mistral、Dolly、Deci-DeciLM モデルをマネージド オンライン エンドポイントにデプロイした場合、Azure Machine Learning では、テストを実行できるように、少しの間、その共有クォータ プールにアクセスできます。 共有クォータ プールについて詳しくは、「Azure Machine Learning の共有クォータ」をご覧ください。
システムを準備する
環境変数の設定
まだ Azure CLI の既定値を設定していない場合は、既定の設定を保存する必要があります。 サブスクリプション、ワークスペース、およびリソース グループの値を複数回渡さないようにするには、次のコードを実行します。
az account set --subscription <subscription ID>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
examples リポジトリをクローンします
この記事に従うには、まず azureml-examples リポジトリを複製してから、リポジトリの azureml-examples/cli ディレクトリに変更します。
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli
--depth 1を使用して、リポジトリへの最新のコミットのみを複製します。これにより、操作を完了する時間が短縮されます。
このチュートリアルのコマンドは、cli ディレクトリのファイル deploy-local-endpoint.sh と deploy-managed-online-endpoint.sh にあります。 YAML 構成ファイルは 、endpoints/online/managed/sample/ サブディレクトリにあります。
注意
Kubernetes オンライン エンドポイントの YAML 構成ファイルは、 endpoints/online/kubernetes/ サブディレクトリにあります。
examples リポジトリをクローンします
トレーニング例を実行するには、まず azureml-examples リポジトリを複製してから、 azureml-examples/sdk/python/endpoints/online/managed directory に変更します。
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/sdk/python/endpoints/online/managed
--depth 1を使用して、リポジトリへの最新のコミットのみを複製します。これにより、操作を完了する時間が短縮されます。
この記事の情報は、online-endpoints-simple-deployment.ipynb ノートブックに基づいています。 それにはこの記事と同じ内容が含まれていますが、コードの順序は若干異なります。
Azure Machine Learning ワークスペースに接続する
ワークスペースは、Azure Machine Learning の最上位のリソースです。 Azure Machine Learning を使用するときに作成するすべての成果物を一元的に操作できます。 このセクションでは、展開タスクを実行するワークスペースに接続します。 手順を実行するには、 online-endpoints-simple-deployment.ipynb ノートブックを 開きます。
必要なライブラリをインポートします。
# import required libraries
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
CodeConfiguration
)
from azure.identity import DefaultAzureCredential
注意
Kubernetes オンライン エンドポイントを使用する場合は、azure.ai.ml.entities ライブラリから KubernetesOnlineEndpoint クラスと KubernetesOnlineDeployment クラスをインポートします。
ワークスペースの詳細を構成し、ワークスペースへのハンドルを取得します。
ワークスペースに接続するには、サブスクリプション、リソース グループ、ワークスペース名という識別子パラメーターが必要です。 MLClient の詳細を azure.ai.ml で使用して、必要な Azure Machine Learning ワークスペースへのハンドルを取得します。 次の例では、既定の Azure 認証を使用しています。
# enter details of your Azure Machine Learning workspace
subscription_id = "<subscription ID>"
resource_group = "<resource group>"
workspace = "<workspace name>"
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
ローカル コンピューターに Git をインストール済みの場合は、手順に従ってサンプル リポジトリを複製できます。 それ以外の場合は、手順に従ってサンプル リポジトリからファイルをダウンロードします。
examples リポジトリをクローンします
この記事に従うには、まず azureml-examples リポジトリを複製してから、 azureml-examples/cli/endpoints/online/model-1 ディレクトリに変更します。
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli/endpoints/online/model-1
--depth 1を使用して、リポジトリへの最新のコミットのみを複製します。これにより、操作を完了する時間が短縮されます。
サンプル リポジトリからファイルをダウンロードする
サンプル リポジトリを複製した場合は、ローカル コンピューターにこのサンプル用のファイルのコピーが既にあるので、次のセクションに進むことができます。 リポジトリを複製しなかった場合は、ローカル コンピューターにダウンロードします。
- サンプル リポジトリ (azureml-examples) に移動します。
- ページの [<> コード] ボタンに移動し、[ローカル] タブで [ZIP のダウンロード] を選択します。
- フォルダー /cli/endpoints/online/model-1/model とファイル /cli/endpoints/online/model-1/onlinescoring/score.py を見つけます。
環境変数の設定
この記事の例で使用できるように、次の環境変数を設定します。 これらの値を Azure サブスクリプション ID、ワークスペースが配置されている Azure リージョン、ワークスペースが含まれているリソース グループ、ワークスペース名に置き換えます。
export SUBSCRIPTION_ID="<subscription ID>"
export LOCATION="<your region>"
export RESOURCE_GROUP="<resource group>"
export WORKSPACE="<workspace name>"
いくつかのテンプレート例では、ワークスペースの Azure Blob Storage にファイルをアップロードする必要があります。 次の手順では、ワークスペースに対してクエリを実行し、この情報を例で使用する環境変数に格納します。
アクセス トークンを取得します。
TOKEN=$(az account get-access-token --query accessToken -o tsv)
REST API バージョンを設定します。
API_VERSION="2022-05-01"
ストレージ情報を取得します。
# Get values for storage account
response=$(curl --___location --request GET "https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.MachineLearningServices/workspaces/$WORKSPACE/datastores?api-version=$API_VERSION&isDefault=true" \
--header "Authorization: Bearer $TOKEN")
AZUREML_DEFAULT_DATASTORE=$(echo $response | jq -r '.value[0].name')
AZUREML_DEFAULT_CONTAINER=$(echo $response | jq -r '.value[0].properties.containerName')
export AZURE_STORAGE_ACCOUNT=$(echo $response | jq -r '.value[0].properties.accountName')
examples リポジトリをクローンします
この記事に従うには、まず azureml-examples リポジトリを複製してから、 azureml-examples ディレクトリに変更します。
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples
--depth 1を使用して、リポジトリへの最新のコミットのみを複製します。これにより、操作を完了する時間が短縮されます。
エンドポイントを定義する
オンライン エンドポイントを定義するには、エンドポイント名と認証モードを指定します。 マネージド オンライン エンドポイントについて詳しくは、「オンライン エンドポイント」をご覧ください。
エンドポイント名を設定する
エンドポイント名を設定するには、次のコマンドを実行します。 <YOUR_ENDPOINT_NAME> を Azure リージョンでの一意の名前に置き換えます。 名前付け規則の詳細については、「 エンドポイントの制限」を参照してください。
export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"
次のスニペットは、endpoints/online/managed/sample/endpoint.yml ファイルを示しています。
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: my-endpoint
auth_mode: key
エンドポイント YAML 形式のリファレンスを次の表で説明します。 これらの属性の指定方法については、オンライン エンドポイント YAML リファレンスに関する記事を参照してください。 マネージド エンドポイントに関連する制限については、 Azure Machine Learning オンライン エンドポイントとバッチ エンドポイントに関するページを参照してください。
| 鍵 |
説明 |
$schema |
(省略可能) YAML スキーマ。 上記のコード スニペットをブラウザーで表示すると、YAML ファイルで使用可能なすべてのオプションを確認できます。 |
name |
エンドポイントの名前。 |
auth_mode |
キーベースの認証に key を使用します。
Azure Machine Learning のトークン ベースの認証に aml_token を使用します。
Microsoft Entra トークンベースの認証 (プレビュー) の場合は aad_token を使います。
認証の詳細については、オンライン エンドポイントのクライアントを認証するに関する記事を参照してください。 |
まず、オンライン エンドポイントの名前を定義してから、エンドポイントを構成します。
<YOUR_ENDPOINT_NAME>を Azure リージョンで一意の名前に置き換えるか、サンプル メソッドを使用してランダムな名前を定義します。 使用しないメソッドは必ず削除してください。 名前付け規則の詳細については、「 エンドポイントの制限」を参照してください。
# method 1: define an endpoint name
endpoint_name = "<YOUR_ENDPOINT_NAME>"
# method 2: example way to define a random name
import datetime
endpoint_name = "endpt-" + datetime.datetime.now().strftime("%m%d%H%M%f")
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name = endpoint_name,
description="this is a sample endpoint",
auth_mode="key"
)
前のコードでは、キーベースの認証の key を使っています。 Azure Machine Learning トークン ベースの認証を使用するには、aml_token を使用します。 Microsoft Entra トークン ベースの認証 (プレビュー) を使うには、aad_token を使います。 認証の詳細については、オンライン エンドポイントのクライアントを認証するに関する記事を参照してください。
スタジオから Azure にデプロイする場合は、エンドポイントとデプロイを作成して追加します。 その時点で、エンドポイントとデプロイの名前を指定するように求められます。
デプロイを定義する
デプロイは、実際の推論を実行するモデルをホストするのに必要なリソースのセットです。 この例では、回帰を実行する scikit-learn モデルをデプロイし、スコアリング スクリプト score.py を使用して、特定の入力要求でモデルを実行します。
デプロイの主な属性については、「オンライン デプロイ」をご覧ください。
デプロイ構成では、デプロイするモデルの場所が使用されます。
次のスニペットは、デプロイを構成するのに必要なすべての入力が指定された endpoints/online/managed/sample/blue-deployment.yml ファイルを示しています。
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: ../../model-1/model/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yaml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
blue-deployment.yml ファイルで、次のデプロイ属性が指定されています。
model: path パラメーター (ファイルのアップロード先) を使用して、モデルプロパティをインラインで指定します。 CLI によって自動的にモデル ファイルがアップロードされ、自動生成された名前でモデルが登録されます。environment: ファイルのアップロード先を含むインライン定義を使用します。 CLI によって conda.yaml ファイルが自動的にアップロードされ、環境が登録されます。 後で環境を構築するために、デプロイでは基本イメージの image パラメーターが使用されます。 この例では、mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latestです。 conda_fileの依存関係は、基本イメージの上にインストールされます。code_configuration: デプロイ時に、スコアリング モデルの Python ソースなどのローカル ファイルを開発環境からアップロードします。
YAML スキーマの詳細については、オンライン エンドポイント YAML リファレンスに関するドキュメントを参照してください。
注意
コンピューティング先としてマネージド オンライン エンドポイントではなく Kubernetes エンドポイントを使うには:
- Azure Machine Learning スタジオを使用して、Kubernetes クラスターを作成し、Azure Machine Learning ワークスペースにコンピューティング先としてアタッチします。
- エンドポイント YAML を使用して、マネージド エンドポイント YAML ではなく Kubernetes をターゲットにします。 YAML を編集して
compute の値を登録済みコンピューティング先の名前に変更する必要があります。 Kubernetes デプロイに適用される他のプロパティを持つこの deployment.yaml を使用できます。
マネージド オンライン エンドポイントに関してこの記事で使われているすべてのコマンドは、Kubernetes エンドポイントにも適用されます。ただし、次の機能は Kubernetes エンドポイントには適用されません。
デプロイを構成するには、次のコードを使用します。
model = Model(path="../model-1/model/sklearn_regression_model.pkl")
env = Environment(
conda_file="../model-1/environment/conda.yaml",
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
Model: path パラメーター (ファイルのアップロード先) を使用して、モデルプロパティをインラインで指定します。 SDK によって自動的にモデル ファイルがアップロードされ、自動生成された名前でモデルが登録されます。Environment: ファイルのアップロード先を含むインライン定義を使用します。 SDK によって conda.yaml ファイルが自動的にアップロードされ、環境が登録されます。 後で環境を構築するために、デプロイでは基本イメージの image パラメーターが使用されます。 この例では、mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latestです。 conda_fileの依存関係は、基本イメージの上にインストールされます。CodeConfiguration: デプロイ時に、スコアリング モデルの Python ソースなどのローカル ファイルを開発環境からアップロードします。
オンライン デプロイ定義について詳しくは、「OnlineDeployment クラス」をご覧ください。
Azure にデプロイするときは、エンドポイントとデプロイを作成して追加します。 その時点で、エンドポイントとデプロイの名前を指定するように求められます。
スコアリング スクリプトを理解する
オンライン エンドポイントのスコアリング スクリプトの形式は、前のバージョンの CLI や Python SDK で使用されている形式と同じです。
code_configuration.scoring_script で指定されているスコアリング スクリプトには、init() 関数と run() 関数が含まれている必要があります。
スコアリング スクリプトには、init() 関数と run() 関数が含まれている必要があります。
スコアリング スクリプトには、init() 関数と run() 関数が含まれている必要があります。
スコアリング スクリプトには、init() 関数と run() 関数が含まれている必要があります。 この記事では、score.py ファイルを使います。
デプロイにテンプレートを使用する場合は、最初にスコアリング ファイルを Blob Storage にアップロードしてから、それを登録する必要があります。
次のコードでは、Azure CLI コマンド az storage blob upload-batch を使用してスコアリング ファイルをアップロードします。
az storage blob upload-batch -d $AZUREML_DEFAULT_CONTAINER/score -s cli/endpoints/online/model-1/onlinescoring --account-name $AZURE_STORAGE_ACCOUNT
次のコードでは、テンプレートを使用してコードを登録します。
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/code-version.json \
--parameters \
workspaceName=$WORKSPACE \
codeAssetName="score-sklearn" \
codeUri="https://$AZURE_STORAGE_ACCOUNT.blob.core.windows.net/$AZUREML_DEFAULT_CONTAINER/score"
この例では、先ほど複製またはダウンロードしたリポジトリの score.py ファイル を使用します。
import os
import logging
import json
import numpy
import joblib
def init():
"""
This function is called when the container is initialized/started, typically after create/update of the deployment.
You can write the logic here to perform init operations like caching the model in memory
"""
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment.
# It is the path to the model folder (./azureml-models/$MODEL_NAME/$VERSION)
# Please provide your model's folder name if there is one
model_path = os.path.join(
os.getenv("AZUREML_MODEL_DIR"), "model/sklearn_regression_model.pkl"
)
# deserialize the model file back into a sklearn model
model = joblib.load(model_path)
logging.info("Init complete")
def run(raw_data):
"""
This function is called for every invocation of the endpoint to perform the actual scoring/prediction.
In the example we extract the data from the json input and call the scikit-learn model's predict()
method and return the result back
"""
logging.info("model 1: request received")
data = json.loads(raw_data)["data"]
data = numpy.array(data)
result = model.predict(data)
logging.info("Request processed")
return result.tolist()
init() 関数は、コンテナーが初期化または起動された時に呼び出されます。 初期化は、通常、デプロイが作成または更新された直後に実行されます。 init 関数は、モデルをメモリにキャッシュするなど (この score.py ファイル内で示されている)、グローバルな初期化操作のロジックを記述する場所です。
run()関数は、エンドポイントが呼び出されるたびに呼び出されます。 これは、実際のスコア付けと予測を行います。 この score.py ファイル内では、run() 関数で、 JSON 入力からデータを抽出し、scikit-learn モデルの predict() メソッドを呼び出してから、予測結果を返しています。
ローカル エンドポイントを使ってデプロイしローカルでデバッグする
Azure にデプロイする前に、エンドポイントをローカルで実行してコードと構成を検証およびデバッグすることを 強くお勧めします 。 Azure CLI と Python SDK はローカル エンドポイントとデプロイをサポートしますが、Azure Machine Learning Studio と ARM テンプレートはサポートしていません。
ローカルにデプロイするには、Docker エンジンをインストールして実行する必要があります。 通常、Docker エンジンは、コンピューターの起動時に起動します。 起動しない場合は、Docker エンジンをトラブルシューティングします。
Azure Machine Learning 推論 HTTP サーバー Python パッケージを使用して、Docker エンジンなしでスコアリング スクリプトをローカルでデバッグできます。 推論サーバーを使用したデバッグは、ローカル エンドポイントにデプロイする前にスコアリング スクリプトをデバッグするのに役立ちます。これにより、デプロイ コンテナーの構成の影響を受けずにデバッグできます。
Azure にデプロイする前にオンライン エンドポイントをローカルでデバッグする方法の詳細については、「 オンライン エンドポイントのデバッグ」を参照してください。
モデルをローカルにデプロイする
まず、エンドポイントを作成します。 必要に応じて、ローカル エンドポイントの場合は、この手順をスキップできます。 デプロイを直接作成できます (次の手順を参照)。これにより、必要なメタデータが作成されます。 モデルをローカル環境にデプロイすると、開発とテストに役立ちます。
az ml online-endpoint create --local -n $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
ml_client.online_endpoints.begin_create_or_update(endpoint, local=True)
スタジオでは、ローカル エンドポイントはサポートされていません。 エンドポイントをローカルでテストする手順については、Azure CLI または Python のタブを参照してください。
このテンプレートは、ローカル エンドポイントをサポートしていません。 エンドポイントをローカルでテストする手順については、Azure CLI または Python のタブを参照してください。
ここで、エンドポイントの下に blue という名前のデプロイを作成します。
az ml online-deployment create --local -n blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment.yml
--local フラグは、エンドポイントを Docker 環境にデプロイするよう CLI に命令するものです。
ml_client.online_deployments.begin_create_or_update(
deployment=blue_deployment, local=True
)
local=True フラグは、エンドポイントを Docker 環境にデプロイするよう SDK に指示します。
スタジオでは、ローカル エンドポイントはサポートされていません。 エンドポイントをローカルでテストする手順については、Azure CLI または Python のタブを参照してください。
このテンプレートは、ローカル エンドポイントをサポートしていません。 エンドポイントをローカルでテストする手順については、Azure CLI または Python のタブを参照してください。
ローカル デプロイが成功したかどうかを確認する
デプロイ状態を調べて、エラーなしでモデルがデプロイされたかどうかを確認します。
az ml online-endpoint show -n $ENDPOINT_NAME --local
出力は次の JSON のようになります。 provisioning_state パラメーターはSucceeded。
{
"auth_mode": "key",
"___location": "local",
"name": "docs-endpoint",
"properties": {},
"provisioning_state": "Succeeded",
"scoring_uri": "http://localhost:49158/score",
"tags": {},
"traffic": {}
}
ml_client.online_endpoints.get(name=endpoint_name, local=True)
このメソッドからは、ManagedOnlineEndpoint エンティティが返されます。 provisioning_state パラメーターはSucceeded。
ManagedOnlineEndpoint({'public_network_access': None, 'provisioning_state': 'Succeeded', 'scoring_uri': 'http://localhost:49158/score', 'swagger_uri': None, 'name': 'endpt-10061534497697', 'description': 'this is a sample endpoint', 'tags': {}, 'properties': {}, 'id': None, 'Resource__source_path': None, 'base_path': '/path/to/your/working/directory', 'creation_context': None, 'serialize': <msrest.serialization.Serializer object at 0x7ffb781bccd0>, 'auth_mode': 'key', '___location': 'local', 'identity': None, 'traffic': {}, 'mirror_traffic': {}, 'kind': None})
スタジオでは、ローカル エンドポイントはサポートされていません。 エンドポイントをローカルでテストする手順については、Azure CLI または Python のタブを参照してください。
このテンプレートは、ローカル エンドポイントをサポートしていません。 エンドポイントをローカルでテストする手順については、Azure CLI または Python のタブを参照してください。
次の表は、provisioning_state に指定できる値です。
| 価値 |
説明 |
Creating |
リソースを作成しています。 |
Updating |
リソースを更新しています。 |
Deleting |
リソースは削除中です。 |
Succeeded |
作成または更新操作が成功しました。 |
Failed |
作成、更新、または削除の操作が失敗しました。 |
ローカル エンドポイントを呼び出し、モデルを使用してデータをスコアリングする
エンドポイントを呼び出してモデルをスコアリングするには、invoke コマンドを使い、JSON ファイルに格納されているクエリ パラメーターを渡します。
az ml online-endpoint invoke --local --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
REST クライアント (curl など) を使用する場合は、スコアリング URI が必要です。 スコアリング URI を取得するには、az ml online-endpoint show --local -n $ENDPOINT_NAME を実行します。 返された値で、scoring_uri 属性を探します。
エンドポイントを呼び出してモデルをスコアリングするには、invoke コマンドを使い、JSON ファイルに格納されているクエリ パラメーターを渡します。
ml_client.online_endpoints.invoke(
endpoint_name=endpoint_name,
request_file="../model-1/sample-request.json",
local=True,
)
REST クライアント (curl など) を使用する場合は、スコアリング URI が必要です。 スコアリング URI を取得するには、次のコードを実行します。 返された値で、scoring_uri 属性を探します。
endpoint = ml_client.online_endpoints.get(endpoint_name, local=True)
scoring_uri = endpoint.scoring_uri
スタジオでは、ローカル エンドポイントはサポートされていません。 エンドポイントをローカルでテストする手順については、Azure CLI または Python のタブを参照してください。
このテンプレートは、ローカル エンドポイントをサポートしていません。 エンドポイントをローカルでテストする手順については、Azure CLI または Python のタブを参照してください。
呼び出し操作からの出力をログで確認する
例の score.py ファイルでは、run() メソッドがいくつかの出力をコンソールにログしています。
この出力は、get-logs コマンドを使って確認できます。
az ml online-deployment get-logs --local -n blue --endpoint $ENDPOINT_NAME
この出力は、get_logs メソッドを使って確認できます。
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, local=True, lines=50
)
スタジオでは、ローカル エンドポイントはサポートされていません。 エンドポイントをローカルでテストする手順については、Azure CLI または Python のタブを参照してください。
このテンプレートは、ローカル エンドポイントをサポートしていません。 エンドポイントをローカルでテストする手順については、Azure CLI または Python のタブを参照してください。
オンライン エンドポイントを Azure にデプロイする
次に、オンライン エンドポイントを Azure にデプロイする 運用環境のベスト プラクティスとして、デプロイで使用するモデルと環境を登録することをお勧めします。
モデルと環境を登録する
登録済みの名前とバージョンをデプロイの間に指定できるように、Azure にデプロイする前にモデルと環境を登録することをお勧めします。 資産を登録した後は、デプロイを作成するたびにアップロードしなくても再利用できます。 この方法により、再現性と追跡性が向上します。
Azure へのデプロイとは異なり、ローカル デプロイでは、登録済みのモデルと環境の使用はサポートされていません。 代わりに、ローカル デプロイではローカル モデル ファイルが使用され、ローカル ファイルのみを含む環境が使用されます。
Azure へのデプロイの場合は、ローカル資産か登録済み資産 (モデルと環境) のどちらかを使うことができます。 この記事のこの項では、Azure へのデプロイで登録済み資産を使っていますが、代わりにローカル資産を使うこともできます。 ローカル デプロイの場合の使用するローカル ファイルをアップロードするデプロイ構成の例は、「デプロイを構成する」をご覧ください。
モデルと環境を登録するには、model: azureml:my-model:1 または environment: azureml:my-env:1 という形式を使います。
登録のために、 model と environment の YAML 定義を endpoints/online/managed/sample フォルダー内の個別の YAML ファイルに抽出し、 az ml model create コマンドと az ml environment createコマンドを使用できます。 これらのコマンドの詳細については、az ml model create -h と az ml environment create -h を実行してください。
モデルの YAML 定義を作成します。 ファイルにmodel.yml名前を 付けます。
$schema: https://azuremlschemas.azureedge.net/latest/model.schema.json
name: my-model
path: ../../model-1/model/
モデルを登録します。
az ml model create -n my-model -v 1 -f endpoints/online/managed/sample/model.yml
環境の YAML 定義を作成します。 ファイルにenvironment.yml名前を 付けます。
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: my-env
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
conda_file: ../../model-1/environment/conda.yaml
環境を登録します。
az ml environment create -n my-env -v 1 -f endpoints/online/managed/sample/environment.yml
モデルを資産として登録する方法の詳細については、「 Azure CLI または Python SDK を使用してモデルを登録する」を参照してください。 環境の作成の詳細については、「 カスタム環境の作成」を参照してください。
モデルを登録します。
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
file_model = Model(
path="../model-1/model/",
type=AssetTypes.CUSTOM_MODEL,
name="my-model",
description="Model created from local file.",
)
ml_client.models.create_or_update(file_model)
環境を登録します。
from azure.ai.ml.entities import Environment
env_docker_conda = Environment(
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
conda_file="../model-1/environment/conda.yaml",
name="my-env",
description="Environment created from a Docker image plus Conda environment.",
)
ml_client.environments.create_or_update(env_docker_conda)
デプロイ時に登録済みの名前とバージョンを指定できるようにモデルを資産として登録する方法については、「 Azure CLI または Python SDK を使用してモデルを登録する」を参照してください。
環境の作成の詳細については、「 カスタム環境の作成」を参照してください。
モデルを登録する
モデルの登録は、ワークスペース内の論理エンティティであり、単一のモデル ファイル、または複数ファイルのディレクトリを含めることができます。 運用環境のベスト プラクティスとして、モデルと環境を登録します。 この記事でエンドポイントとデプロイを作成する前に、モデルを含む モデル フォルダー を登録します。
サンプル モデルを登録するには、次の手順に従います。
[Azure Machine Learning Studio] に移動します。
左側のウィンドウで、[ モデル ] ページを選択します。
[登録] を選択し、次に [ローカル ファイルから] を選択します。
[Model type] (モデルの種類) で [Unspecified 型] を選択します。
[参照] を選択し、[フォルダーの参照] を選択します。
![[フォルダーの参照] オプションを示すスクリーンショット。](media/how-to-deploy-online-endpoints/register-model-folder.png?view=azureml-api-2)
先ほど複製またはダウンロードしたリポジトリのローカル コピーから 、\azureml-examples\cli\endpoints\online\model-1\model フォルダーを選択します。 メッセージが表示されたら、[ アップロード ] を選択し、アップロードが完了するまで待ちます。
[次へ] を選択します。
モデルのフレンドリ名を入力します。 この記事の手順では、モデルの名前が model-1 であることを前提としています。
[ 次へ] を選択し、[ 登録 ] を選択して登録を完了します。
登録済みモデルの使用方法の詳細については、「登録済みモデル の操作」を参照してください。
環境を作成して登録する
左側のウィンドウで、[ 環境 ] ページを選択します。
[ カスタム環境 ] タブを選択し、[ 作成] を選択します。
[ 設定] ページで、環境の my-env などの名前を入力します。
[ Select environment source]\(環境ソースの選択\) で、[ Use existing docker image with optional conda source]\(オプションの conda ソースで既存の Docker イメージを使用する\) を選択します。

[ 次へ ] を選択して、[ カスタマイズ ] ページに移動します。
先ほど複製またはダウンロードしたリポジトリから 、\azureml-examples\cli\endpoints\online\model-1\environment\conda.yaml ファイルの内容をコピーします。
その内容をテキスト ボックスに貼り付けます。

[作成] ページが表示されるまで [次へ] を選択し、[作成] を選択します。
スタジオで環境を作成する方法の詳細については、「環境の 作成」を参照してください。
テンプレートを使用してモデルを登録するには、最初にモデル ファイルを Blob Storage にアップロードする必要があります。 次の例では、az storage blob upload-batch コマンドを使用して、ワークスペースの既定のストレージにファイルをアップロードします。
az storage blob upload-batch -d $AZUREML_DEFAULT_CONTAINER/model -s cli/endpoints/online/model-1/model --account-name $AZURE_STORAGE_ACCOUNT
ファイルをアップロードした後、テンプレートを使用してモデル登録を作成します。 次の例では、modelUri パラメーターにモデルへのパスが含まれています。
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/model-version.json \
--parameters \
workspaceName=$WORKSPACE \
modelAssetName="sklearn" \
modelUri="azureml://subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/workspaces/$WORKSPACE/datastores/$AZUREML_DEFAULT_DATASTORE/paths/model/sklearn_regression_model.pkl"
環境の一部は、モデルをホストするために必要なモデルの依存関係を指定する conda ファイルです。 次の例は、conda ファイルの内容を環境変数に読み取る方法を示しています。
CONDA_FILE=$(cat cli/endpoints/online/model-1/environment/conda.yaml)
次の例は、テンプレートを使用して環境を登録する方法を示しています。 前の手順の conda ファイルの内容は、 condaFile パラメーターを使用してテンプレートに渡されます。
ENV_VERSION=$RANDOM
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/environment-version.json \
--parameters \
workspaceName=$WORKSPACE \
environmentAssetName=sklearn-env \
environmentAssetVersion=$ENV_VERSION \
dockerImage=mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04:20210727.v1 \
condaFile="$CONDA_FILE"
重要
デプロイのカスタム環境を定義するときは、 azureml-inference-server-http パッケージが conda ファイルに含まれていることを確認します。 このパッケージは、推論サーバーが正常に機能するために不可欠です。 独自のカスタム環境を作成する方法に慣れていない場合は、 minimal-py-inference ( mlflowを使用しないカスタム モデルの場合) や mlflow-py-inference ( mlflow を使用するモデルの場合) など、キュレーションされた環境のいずれかを使用します。 これらのキュレーションされた環境は、Azure Machine Learning Studio のインスタンスの [ 環境 ] タブにあります。
デプロイ構成では、デプロイする登録済みモデルと登録済みの環境が使用されます。
デプロイ定義で登録済み資産 (モデルと環境) を使います。 次のスニペットは、 エンドポイント/オンライン/マネージド/サンプル/blue-deployment-with-registered-assets.yml ファイルと、デプロイを構成するために必要なすべての入力を示しています。
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model: azureml:my-model:1
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment: azureml:my-env:1
instance_type: Standard_DS3_v2
instance_count: 1
デプロイを構成するには、登録済みのモデルと環境を使います。
model = "azureml:my-model:1"
env = "azureml:my-env:1"
blue_deployment_with_registered_assets = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
スタジオからデプロイする場合は、エンドポイントと、それに追加するデプロイを作成します。 その時点で、エンドポイントとデプロイの名前を入力するように求められます。
CPU と GPU の異なるインスタンス タイプおよびイメージを使用する
ローカル デプロイの場合も Azure へのデプロイの場合も、デプロイ定義で、CPU または GPU のインスタンス種類とイメージを指定できます。
blue-deployment-with-registered-assets.yml ファイル内のデプロイ定義では、インスタンスStandard_DS3_v2汎用の種類と GPU 以外の Docker イメージ mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latestが使用されています。 GPU コンピューティングの場合は、GPU コンピューティングの種類のバージョンと GPU Docker イメージを選択します。
サポートされている汎用インスタンスと GPU インスタンスの種類については、 マネージド オンライン エンドポイント SKU の一覧を参照してください。 Azure Machine Learning CPU と GPU の基本イメージの一覧については、「Azure Machine Learning 基本イメージ」を参照してください。
ローカル デプロイの場合も Azure へのデプロイの場合も、デプロイ構成で、CPU または GPU のインスタンス種類とイメージを指定できます。
先ほどは、汎用型の Standard_DS3_v2 インスタンスと非 GPU Docker イメージmcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latestを使ったデプロイを構成しました。 GPU コンピューティングの場合は、GPU コンピューティングの種類のバージョンと GPU Docker イメージを選択します。
サポートされている汎用インスタンスと GPU インスタンスの種類については、 マネージド オンライン エンドポイント SKU の一覧を参照してください。 Azure Machine Learning CPU と GPU の基本イメージの一覧については、「Azure Machine Learning 基本イメージ」を参照してください。
上記の環境の登録は、dockerImage パラメーターを使用して値をenvironment-version.jsonテンプレートに渡し、非GPUの Docker イメージmcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04 を指定します。 GPU コンピューティングの場合は、テンプレートに GPU Docker イメージの値を指定し ( dockerImage パラメーターを使用)、 online-endpoint-deployment.json テンプレートに GPU コンピューティングの種類のバージョンを指定します ( skuName パラメーターを使用します)。
サポートされている汎用インスタンスと GPU インスタンスの種類については、 マネージド オンライン エンドポイント SKU の一覧を参照してください。 Azure Machine Learning CPU と GPU の基本イメージの一覧については、「Azure Machine Learning 基本イメージ」を参照してください。
次に、オンライン エンドポイントを Azure にデプロイする
Deploy to Azure (Azure へのデプロイ)
Azure クラウドにエンドポイントを作成します。
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
エンドポイントの下に blue という名前のデプロイを作成します。
az ml online-deployment create --name blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml --all-traffic
デプロイ作成では、基になる環境やイメージを初めて構築しているかどうかによって、最長で 15 分かかる可能性があります。 同じ環境を使う後続のデプロイは、より迅速に処理されます。
CLI コンソールをブロックしたくない場合は、コマンドに --no-wait フラグを追加してください。 ただし、このオプションを選択すると、デプロイ状態の対話型表示が停止します。
デプロイの作成に使われるコード --all-traffic で az ml online-deployment create フラグを指定すると、新規作成されたブルー デプロイにエンドポイント トラフィックの 100% が割り当てられるようになります。 このフラグを使用すると、開発とテストの目的で役立ちますが、運用環境では、明示的なコマンドを使用して新しいデプロイにトラフィックをルーティングできます。 たとえば、 az ml online-endpoint update -n $ENDPOINT_NAME --traffic "blue=100"を使用します。
エンドポイントを作成します。
前に定義した endpoint パラメーターと、前に作成した MLClient パラメーターを使用して、ワークスペースにエンドポイントを作成できるようになりました。 このコマンドでは、エンドポイントの作成を開始し、エンドポイントの作成が続行されている間に確認応答を返します。
ml_client.online_endpoints.begin_create_or_update(endpoint)
デプロイを作成します。
前に定義した blue_deployment_with_registered_assets パラメーターと、前に作成した MLClient パラメーターを使用して、ワークスペースにデプロイを作成できるようになりました。 このコマンドでは、デプロイの作成を開始し、デプロイの作成が続行されている間に確認応答を返します。
ml_client.online_deployments.begin_create_or_update(blue_deployment_with_registered_assets)
Python コンソールをブロックしないようにする場合は、パラメーターにフラグ no_wait=True を追加できます。 ただし、このオプションを選択すると、デプロイ状態の対話型表示が停止します。
# blue deployment takes 100 traffic
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint)
マネージド オンライン エンドポイントとデプロイを作成する
スタジオを使用して、マネージド オンライン エンドポイント をブラウザーで直接作成します。 スタジオでマネージド オンライン エンドポイントを作成する場合は、初期デプロイを定義する必要があります。 空のマネージド オンライン エンドポイントを作成することはできません。
スタジオでマネージド オンライン エンドポイントを作成する方法の 1 つは、[モデル] ページからの作成です。 この方法は、既存のマネージド オンライン デプロイにモデルを追加するための簡単な方法でもあります。 以前に「model-1」の項で登録した という名前のモデルをデプロイするには、次のようにします。
[Azure Machine Learning Studio] に移動します。
左側のウィンドウで、[ モデル ] ページを選択します。
model-1 という名前のモデルを選択します。
[デプロイ]>[リアルタイム エンドポイント] を選択します。
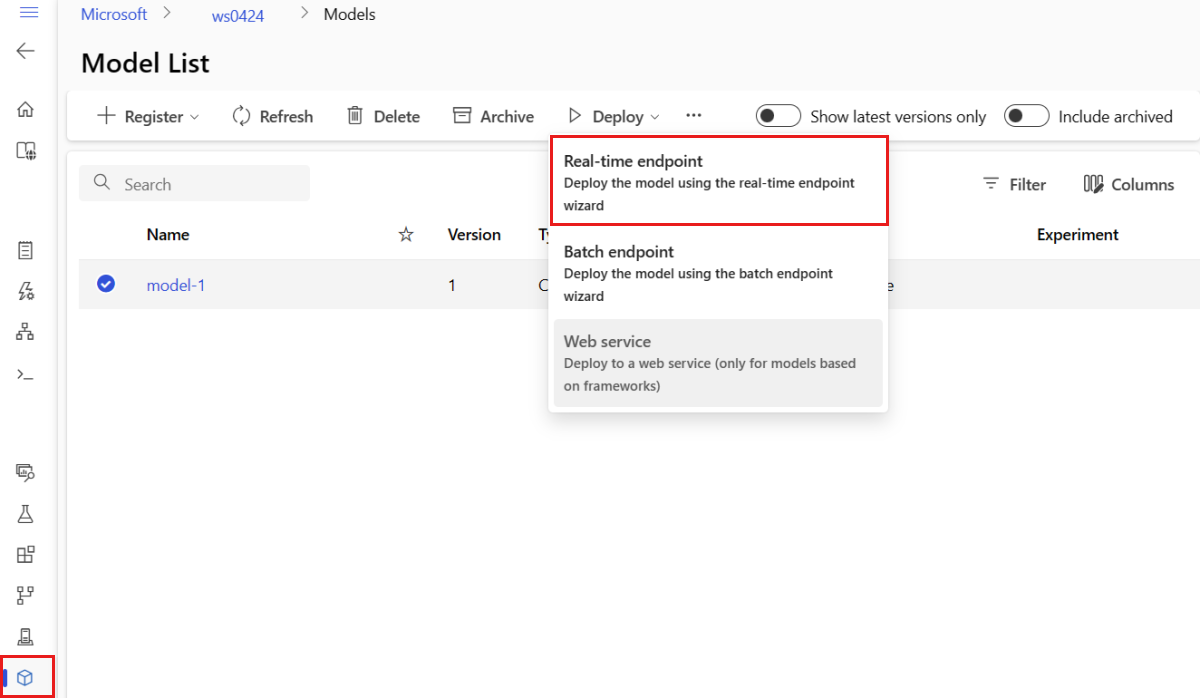
このアクションによって開いたウィンドウで、エンドポイントに関する詳細を指定できます。
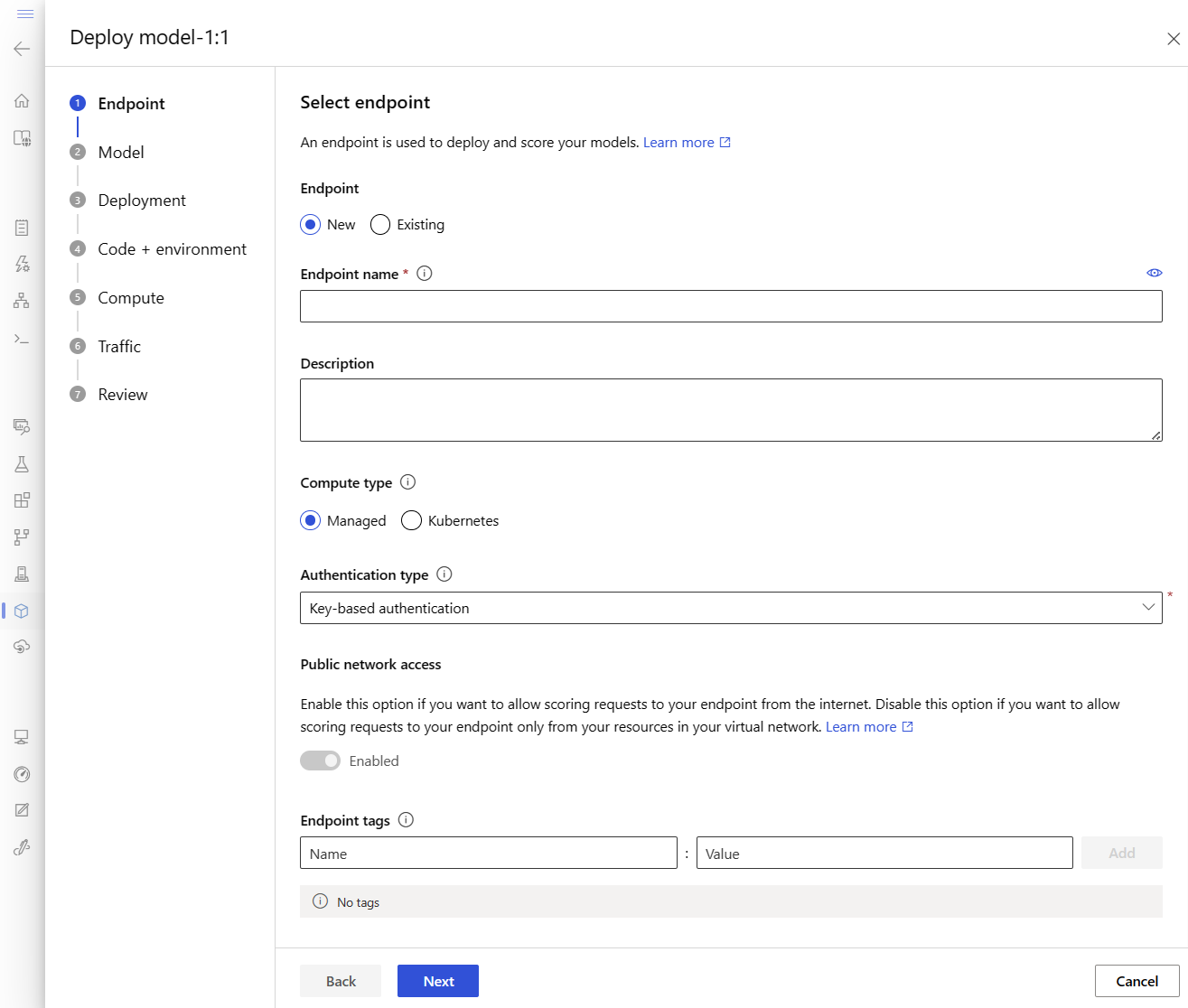
Azure リージョンで一意のエンドポイント名を入力します。 名前付け規則の詳細については、「 エンドポイントの制限」を参照してください。
既定の選択内容 (コンピューティングの種類が [マネージド]) のままにします。
既定の選択内容 (認証の種類が [キーベースの認証]) のままにします。 認証の詳細については、オンライン エンドポイントのクライアントを認証するに関する記事を参照してください。
[デプロイ] ページが表示されるまで、[次へ] を選択します。 Application Insights 診断を有効に切り替えて、後で Studio でエンドポイントのアクティビティのグラフを表示し、Application Insights を使用してメトリックとログを分析できるようにします。
[次へ] を選んで、[コード + 環境] ページに移動します。 次のオプションを選択します。
- 推論用のスコアリング スクリプトを選択します。先ほど複製またはダウンロードしたリポジトリから 、\azureml-examples\cli\endpoints\online\model-1\onlinescoring\score.py ファイルを参照して選択します。
- [環境の選択] セクション: [カスタム環境] を選択してから、前に作成したmy-env:1 環境を選択します。
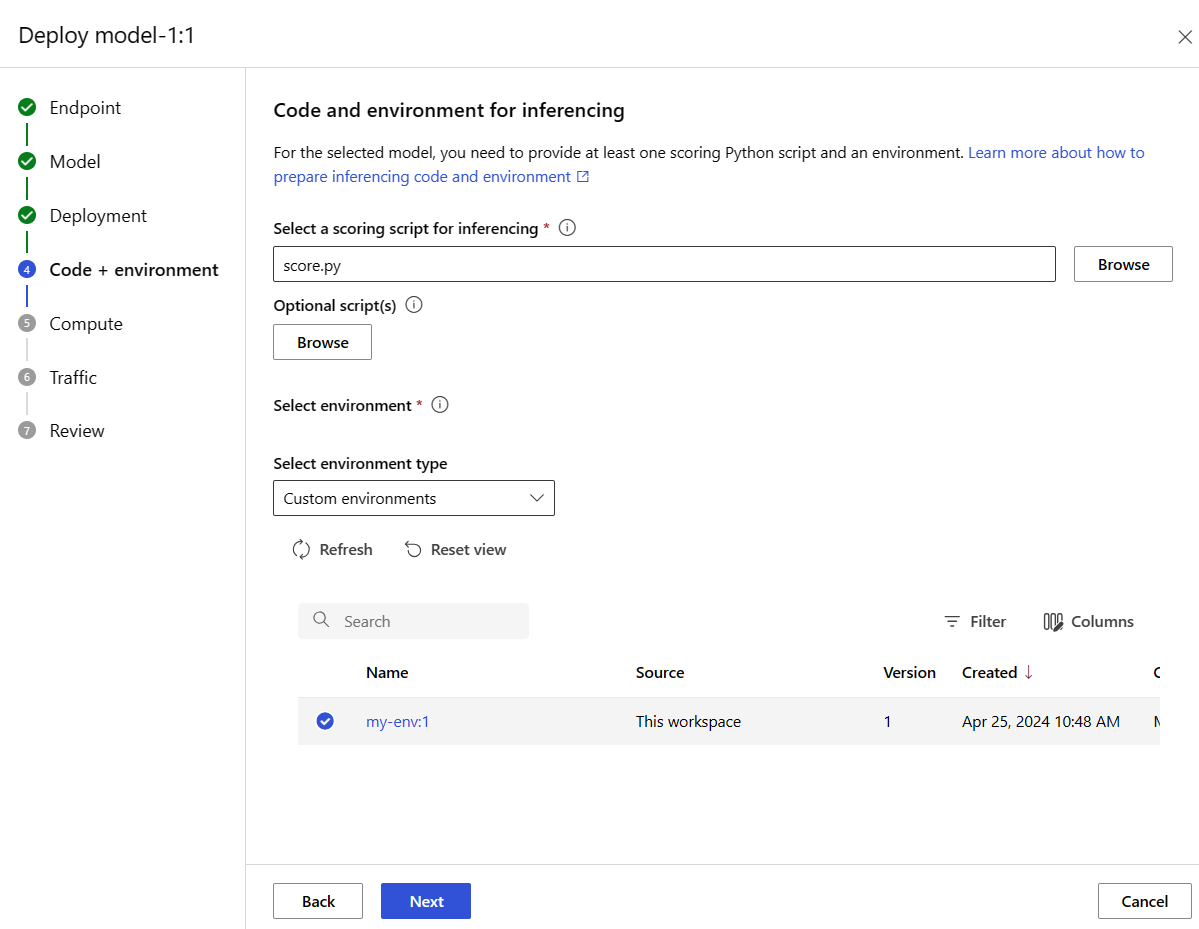
[次へ] を選択し、デプロイの作成を求めるメッセージが表示されるまで既定値をそのまま使用します。
デプロイ設定を確認し、[ 作成] を選択します。
あるいは、スタジオの [エンドポイント] ページでマネージド オンライン エンドポイントを作成することもできます。
[Azure Machine Learning Studio] に移動します。
左側のウィンドウで、[エンドポイント] ページ を 選択します。
[+ 作成] を選択します。
![[エンドポイント] タブからのマネージド オンライン エンドポイントの作成を示すスクリーンショット。](media/how-to-deploy-online-endpoints/endpoint-create-managed-online-endpoint.png?view=azureml-api-2)
このアクションにより、モデルを選択しエンドポイントとデプロイに関する詳細を指定するためのウィンドウが開かれます。 前に説明したようにエンドポイントとデプロイの設定を入力し、[ 作成 ] を選択してデプロイを作成します。
テンプレートを使ってオンライン エンドポイントを作成するには:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/online-endpoint.json \
--parameters \
workspaceName=$WORKSPACE \
onlineEndpointName=$ENDPOINT_NAME \
identityType=SystemAssigned \
authMode=AMLToken \
___location=$LOCATION
エンドポイントの作成後に、エンドポイントにモデルをデプロイします。
resourceScope="/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.MachineLearningServices"
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/online-endpoint-deployment.json \
--parameters \
workspaceName=$WORKSPACE \
___location=$LOCATION \
onlineEndpointName=$ENDPOINT_NAME \
onlineDeploymentName=blue \
codeId="$resourceScope/workspaces/$WORKSPACE/codes/score-sklearn/versions/1" \
scoringScript=score.py \
environmentId="$resourceScope/workspaces/$WORKSPACE/environments/sklearn-env/versions/$ENV_VERSION" \
model="$resourceScope/workspaces/$WORKSPACE/models/sklearn/versions/1" \
endpointComputeType=Managed \
skuName=Standard_F2s_v2 \
skuCapacity=1
デプロイでのエラーをデバッグするには、「オンライン エンドポイントのデプロイとスコアリングのトラブルシューティング」をご覧ください。
オンライン エンドポイントの状態を確認する
show コマンドを使って、エンドポイントとデプロイについて provisioning_state に情報を表示します。
az ml online-endpoint show -n $ENDPOINT_NAME
list コマンドを使って、ワークスペース内のすべてのエンドポイントを表形式で一覧表示します。
az ml online-endpoint list --output table
エンドポイントの状態を調べて、エラーなしでモデルがデプロイされたかどうかを確認します。
ml_client.online_endpoints.get(name=endpoint_name)
list メソッドを使って、ワークスペース内のすべてのエンドポイントを表形式で一覧表示します。
for endpoint in ml_client.online_endpoints.list():
print(endpoint.name)
このメソッドは、ManagedOnlineEndpoint エンティティのリスト (列挙子) を返します。
その他の情報を取得するには、さらに パラメーターを指定します。 たとえば、エンドポイントの一覧をテーブルのように出力します。
print("Kind\tLocation\tName")
print("-------\t----------\t------------------------")
for endpoint in ml_client.online_endpoints.list():
print(f"{endpoint.kind}\t{endpoint.___location}\t{endpoint.name}")
マネージド オンライン エンドポイントを表示する
[ エンドポイント ] ページですべてのマネージド オンライン エンドポイントを表示できます。 エンドポイントの [詳細] ページに移動して、エンドポイント URI、状態、テスト ツール、アクティビティ モニター、デプロイ ログ、サンプル消費コードなどの重要な情報を見つけます。
左側のウィンドウで、[ エンドポイント ] を選択すると、ワークスペース内のすべてのエンドポイントの一覧が表示されます。
(省略可能) コンピューティングの種類 にフィルターを作成して、 マネージド コンピューティングの種類のみを表示します。
エンドポイント名を選択して、エンドポイントの [詳細] ページを表示します。
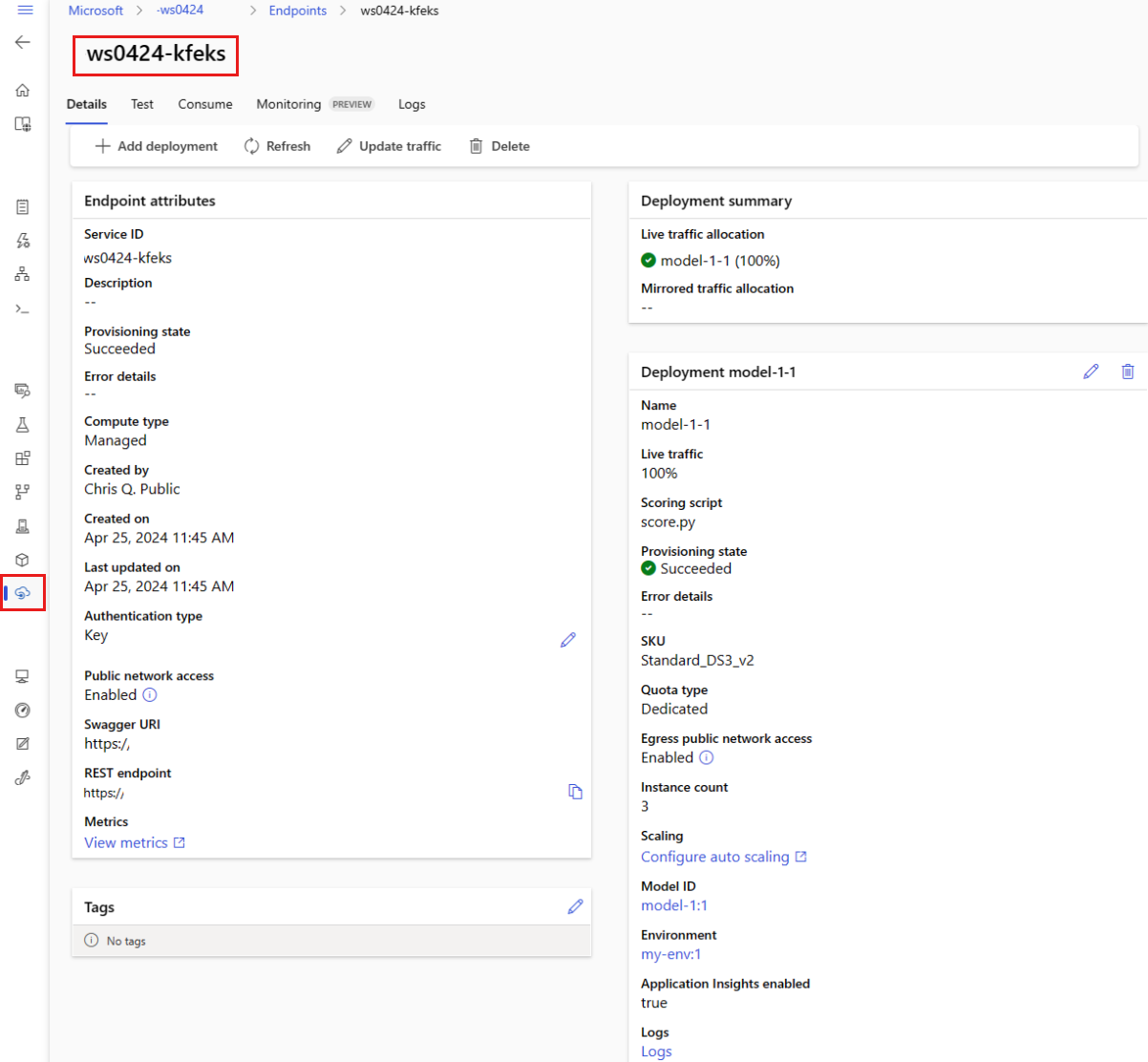
テンプレートはリソースのデプロイに役立ちますが、リソースの一覧表示、表示、または呼び出しには使用できません。 これらの操作を実行するには、Azure CLI、Python SDK、またはスタジオを使用します。 次のコードでは、Azure CLI を使用しています。
show コマンドを使用して、エンドポイントとデプロイのprovisioning_state パラメーターに情報を表示します。
az ml online-endpoint show -n $ENDPOINT_NAME
list コマンドを使って、ワークスペース内のすべてのエンドポイントを表形式で一覧表示します。
az ml online-endpoint list --output table
オンライン デプロイの状態を確認する
ログを調べて、モデルがエラーなしでデプロイされたかどうかを確認します。
コンテナーからのログ出力を表示するには、次の CLI コマンドを使用します。
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
既定では、ログは推論サーバー コンテナーからプルされます。 ストレージ初期化子コンテナーのログを表示するには、--container storage-initializer フラグを追加します。 デプロイのログについて詳しくは、「コンテナー ログを取得する」をご覧ください。
get_logs メソッドを使ってログ出力を表示できます。
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50
)
既定では、ログは推論サーバー コンテナーからプルされます。 ストレージ初期化子コンテナーのログを表示するには、container_type="storage-initializer" オプションを追加します。 デプロイのログについて詳しくは、「コンテナー ログを取得する」をご覧ください。
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50, container_type="storage-initializer"
)
ログ出力を表示するには、エンドポイントのページから [ログ] タブを選択します。 エンドポイントに複数のデプロイがある場合は、ドロップダウン リストを使用して、表示するログを含むデプロイを選択します。
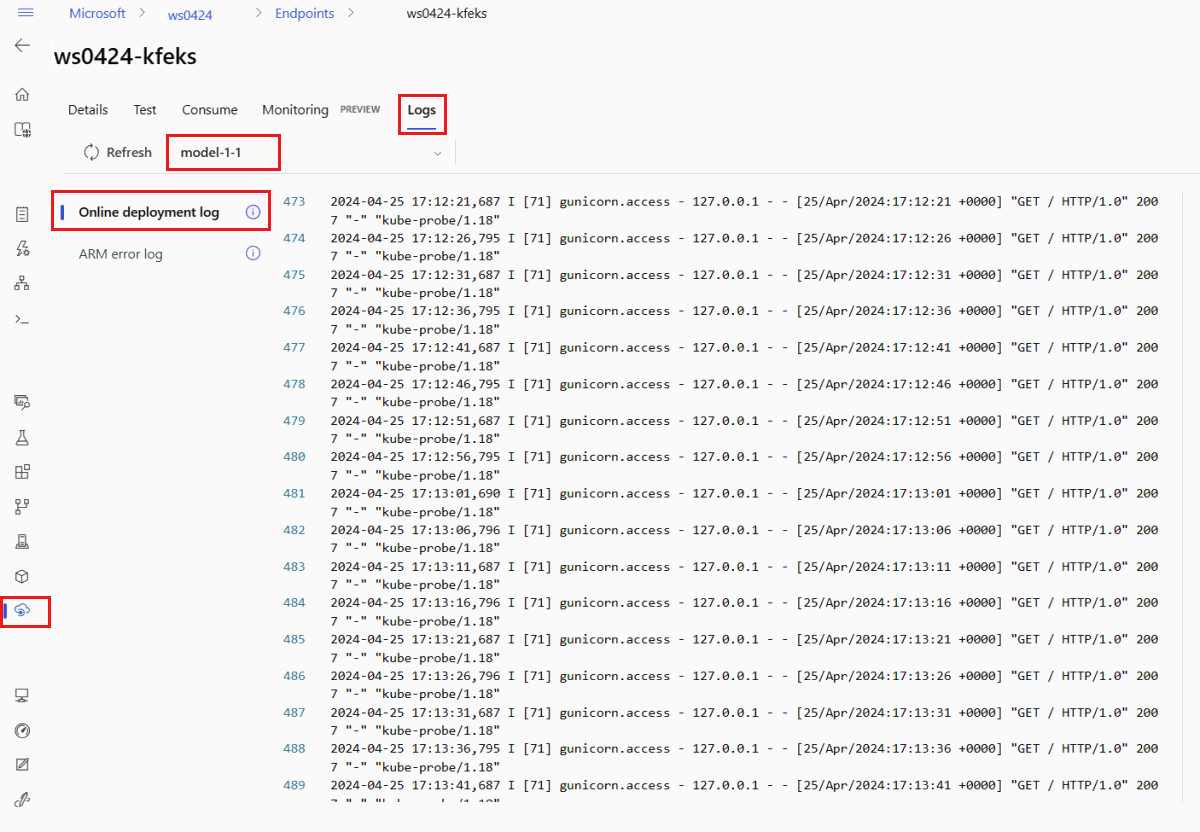
既定では、ログは推論サーバーからプルされます。 ストレージ初期化子コンテナーのログを表示するには、Azure CLI または Python SDK を使用します (詳細については、各タブを参照してください)。 ストレージ初期化子コンテナーからのログでは、コードとモデル データがコンテナーに正常にダウンロードされたかどうかに関する情報が提供されます。 デプロイのログについて詳しくは、「コンテナー ログを取得する」をご覧ください。
テンプレートはリソースのデプロイに役立ちますが、リソースの一覧表示、表示、または呼び出しには使用できません。 これらの操作を実行するには、Azure CLI、Python SDK、またはスタジオを使用します。 次のコードでは、Azure CLI を使用しています。
コンテナーからのログ出力を表示するには、次の CLI コマンドを使用します。
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
既定では、ログは推論サーバー コンテナーからプルされます。 ストレージ初期化子コンテナーのログを表示するには、--container storage-initializer フラグを追加します。 デプロイのログについて詳しくは、「コンテナー ログを取得する」をご覧ください。
エンドポイントを呼び出し、モデルを使用してデータをスコアリングする
invoke コマンドか任意の REST クライアントを使ってエンドポイントを呼び出しデータをスコアリングします。
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
エンドポイントに対する認証に使うキーを取得します。
認証キーを取得できる Microsoft Entra セキュリティ プリンシパルは、Microsoft.MachineLearningServices/workspaces/onlineEndpoints/token/action と Microsoft.MachineLearningServices/workspaces/onlineEndpoints/listkeys/action を許可するカスタム ロールにそれを割り当てることで制御できます。 ワークスペースへの承認を管理する方法の詳細については、「 Azure Machine Learning ワークスペースへのアクセスを管理する」を参照してください。
ENDPOINT_KEY=$(az ml online-endpoint get-credentials -n $ENDPOINT_NAME -o tsv --query primaryKey)
curl を使ってデータをスコアリングします。
SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query scoring_uri)
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --data @endpoints/online/model-1/sample-request.json
showコマンドとget-credentials コマンドを使用して認証資格情報を取得していることに注意してください。 また、 --query フラグを使用して、必要な属性のみをフィルター処理していることに注意してください。 --query フラグについて詳しくは、Azure CLI コマンドの出力に対するクエリに関する記事をご覧ください。
起動ログを表示するには、再度 get-logs を実行します。
前に作成した MLClient パラメーターを使用すると、エンドポイントへのハンドルを取得します。 その後、次のパラメーターを指定して invoke コマンドを使用してエンドポイントを呼び出すことができます。
endpoint_name: エンドポイントの名前です。request_file: 要求データを含むファイル。deployment_name: エンドポイントでテストする特定のデプロイの名前。
JSON ファイルを使用してサンプル要求を送信します。
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=endpoint_name,
deployment_name="blue",
request_file="../model-1/sample-request.json",
)
エンドポイントの詳細ページの [ テスト ] タブを使用して、マネージド オンラインデプロイをテストします。 サンプル入力を入力し、結果を表示します。
エンドポイントの詳細ページの [ テスト ] タブを選択します。
ドロップダウン リストを使用して、テストするデプロイを選択します。
入力サンプルを入力します。
[Test] を選択します。

テンプレートはリソースのデプロイに役立ちますが、リソースの一覧表示、表示、または呼び出しには使用できません。 これらの操作を実行するには、Azure CLI、Python SDK、またはスタジオを使用します。 次のコードでは、Azure CLI を使用しています。
invoke コマンドか任意の REST クライアントを使ってエンドポイントを呼び出しデータをスコアリングします。
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file cli/endpoints/online/model-1/sample-request.json
(省略可能) デプロイを更新する
コード、モデル、または環境を更新する場合は、YAML ファイルを更新します。 az ml online-endpoint update コマンドを実行します。
1 つの update コマンドでインスタンス数を他のモデル設定 (コード、モデル、環境など) と共に更新すると、最初にスケーリング操作が実行されます。 その他の更新プログラムは次に適用されます。 運用環境では、これらの操作を個別に実行することをお勧めします。
update の動作を理解するには:
ファイル online/model-1/onlinescoring/score.py を開きます。
init() 関数の最後の行を変更します。logging.info("Init complete") の後に、logging.info("Updated successfully") を追加してください。
ファイルを保存します。
次のコマンドを実行します。
az ml online-deployment update -n blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml
YAML を使用した更新は宣言型です。 つまり、YAML の変更は、基になる Resource Manager リソース (エンドポイントとデプロイ) に反映されます。 この宣言型アプローチによって GitOps が促進されます。つまり、エンドポイントとデプロイに対する "すべて" の変更は YAML を経由することになります (instance_count も含む)。
パラメーターなどの--setを CLI の update コマンドで使用すると、YAML 内の属性をオーバーライドしたり、"あるいは" 特定の属性を YAML ファイルに渡さずに設定したりできます。 個別の属性に対する --set の使用は、特に開発およびテストのシナリオで利便性を発揮します。 たとえば、最初のデプロイの instance_count 値をスケールアップするのであれば、--set instance_count=2 フラグを使用できます。 ただし、YAML が更新されないため、この手法に GitOps を促進する効果はありません。
YAML ファイルの指定は必須 ではありません 。 たとえば、特定のデプロイに対して異なるコンカレンシー設定をテストする場合は、 az ml online-deployment update -n blue -e my-endpoint --set request_settings.max_concurrent_requests_per_instance=4 environment_variables.WORKER_COUNT=4などを試すことができます。 この方法では、既存のすべての構成が保持されますが、指定されたパラメーターのみが更新されます。
エンドポイントの作成時または更新時に実行される init() 関数を変更したため、メッセージ Updated successfully がログに表示されます。 次を実行してログを取得します。
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
update コマンドは、ローカル デプロイでも動作します。 同じ az ml online-deployment update コマンドを --local フラグと共に使用します。
コード、モデル、または環境を更新する場合は、構成を更新してから、 MLClientの online_deployments.begin_create_or_update メソッドを実行して デプロイを作成または更新します。
1 つの begin_create_or_update メソッドでインスタンス数を他のモデル設定 (コード、モデル、環境など) と共に更新すると、最初にスケーリング操作が実行されます。 その後、他の更新プログラムが適用されます。 運用環境では、これらの操作を個別に実行することをお勧めします。
begin_create_or_update の動作を理解するには:
ファイル online/model-1/onlinescoring/score.py を開きます。
init() 関数の最後の行を変更します。logging.info("Init complete") の後に、logging.info("Updated successfully") を追加してください。
ファイルを保存します。
メソッドを実行します。
ml_client.online_deployments.begin_create_or_update(blue_deployment_with_registered_assets)
エンドポイントの作成時または更新時に実行される init() 関数を変更したため、メッセージ Updated successfully がログに表示されます。 次を実行してログを取得します。
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50
)
begin_create_or_update メソッドは、ローカルデプロイでも動作します。 同じメソッドと local=True フラグを使います。
現時点では、デプロイのインスタンス数に対してのみ更新を行うことができます。 個々のデプロイを、インスタンス数を調整してスケールアップまたはスケールダウンするには、次の手順に従います。
- エンドポイントの [詳細] ページを開き、更新するデプロイのカードを見つけます。
- デプロイの名前の横にある編集アイコン (鉛筆アイコン) を選択します。
- デプロイに関連付けられているインスタンス数を更新します。 デプロイ スケールの種類として[既定]または[ターゲット使用率]を選択します。
- [既定値] を選択した場合は、[インスタンス数] に数値を指定することもできます。
- [ターゲット使用率] を選択した場合は、デプロイを自動スケールするときにパラメーターに使用する値を指定できます。
- [更新] を選択して、デプロイのインスタンス数の更新を完了します。
現在、ARM テンプレートを使用してデプロイを更新するオプションはありません。
注意
この項で示すデプロイの更新は、インプレース ローリング更新の例です。
- マネージド オンライン エンドポイントの場合、デプロイは一度に 20% のノードで新しい構成に更新されます。 つまり、デプロイに 10 個のノードがある場合は、一度に 2 つのノードが更新されます。
- Kubernetes オンライン エンドポイントの場合は、デプロイ インスタンスが新しい構成で新規作成され前のデプロイ インスタンスが削除されるということが繰り返されます。
- 運用環境で使用する場合は、 ブルーグリーンデプロイを検討してください。これは、Web サービスを更新するためのより安全な代替手段を提供します。
自動スケールでは、アプリケーションの負荷を処理するために適切な量のリソースが自動的に実行されます。 マネージド オンライン エンドポイントでは、Azure Monitor 自動スケーリング機能との統合によって、自動スケーリングをサポートします。 自動スケールを構成するには、「オンライン エンドポイントを自動スケーリングする」をご覧ください。
(省略可能) Azure Monitor を使用して SLA を監視する
メトリックを表示し、SLA に基づいてアラートを設定するには、「 オンライン エンドポイントの監視」で説明されている手順に従います。
(省略可能) Log Analytics と統合する
CLI の get-logs コマンドまたは SDK の get_logs メソッドは、自動的に選択されたインスタンスからのログの最後の数百行のみを提供します。 一方、Log Analytics は、ログを永続的に保存して分析する手段となります。 ログの使用方法の詳細については、「 ログの使用」を参照してください。
エンドポイントとデプロイを削除する
エンドポイントとその基になるデプロイをすべて削除するには、次のコマンドを使用します。
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
エンドポイントとその基になるデプロイをすべて削除するには、次のコマンドを使用します。
ml_client.online_endpoints.begin_delete(name=endpoint_name)
エンドポイントとデプロイを使用しない場合は、それらを削除します。 エンドポイントを削除すると、その基にあるデプロイもすべて削除されます。
- [Azure Machine Learning Studio] に移動します。
- 左側のウィンドウで、[エンドポイント] ページ を 選択します。
- エンドポイントを選択します。
- [削除] を選択します。
または、エンドポイントの詳細ページで [削除] アイコンを選択して、マネージド オンライン エンドポイントを直接削除することもできます。
エンドポイントとその基になるデプロイをすべて削除するには、次のコマンドを使用します。
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
関連するコンテンツ
![[フォルダーの参照] オプションを示すスクリーンショット。](media/how-to-deploy-online-endpoints/register-model-folder.png?view=azureml-api-2#lightbox)





![[エンドポイント] タブからのマネージド オンライン エンドポイントの作成を示すスクリーンショット。](media/how-to-deploy-online-endpoints/endpoint-create-managed-online-endpoint.png?view=azureml-api-2#lightbox)


