適用対象: Azure CLI ml extension v2 (現行)Python SDK azure-ai-ml v2 (現行)
Azure CLI ml extension v2 (現行)Python SDK azure-ai-ml v2 (現行)
この記事では、中断を引き起こさずに、新しいバージョンの機械学習モデルを運用環境にデプロイする方法について説明します。 安全なロールアウト戦略とも呼ばれるブルーグリーンデプロイ戦略を使用して、新しいバージョンの Web サービスを運用環境に導入します。 この戦略を使用する場合は、完全にロールアウトする前に、新しいバージョンの Web サービスを少数のユーザーまたは要求にロールアウトできます。
この記事では、オンライン エンドポイントまたはオンライン (リアルタイム) 推論に使用されるエンドポイントを使用することを前提としています。 オンライン エンドポイントには、2 つの種類があります。マネージド オンライン エンドポイントと Kubernetes オンライン エンドポイントです。 エンドポイントとエンドポイントの種類の違いの詳細については、「 マネージド オンライン エンドポイントと Kubernetes オンライン エンドポイント」を参照してください。
この記事では、デプロイにマネージド オンライン エンドポイントを使用します。 ただし、マネージド オンライン エンドポイントの代わりに Kubernetes エンドポイントを使用する方法を説明するメモも含まれています。
この記事では、次の方法について説明します。
- モデルの最初のバージョンを提供するために、
blueというデプロイを使用してオンライン エンドポイントを定義します。 blueデプロイをスケーリングして、より多くの要求を処理できるようにします。greenデプロイと呼ばれる 2 番目のバージョンのモデルをエンドポイントにデプロイしますが、ライブ トラフィックは送信しません。greenデプロイを分離してテストします。- ライブ トラフィックの割合を
greenデプロイにミラーリングして検証します。 - ライブ トラフィックのごく一部を
greenデプロイに送信します。 - すべてのライブ トラフィックを
greenデプロイに送信します。 - 未使用の
blue展開を削除します。
前提条件
- Azure CLI
- Python SDK
-
[ スタジオ](#tab/azure-studio)
Azure CLI と Azure CLI の
ml拡張機能(インストールおよび構成済み)。 詳細については、「 CLI のインストールと設定 (v2)」を参照してください。Bash シェルまたは互換性のあるシェル (Linux システム上のシェルや Linux 用 Windows サブシステムなど)。 この記事の Azure CLI の例では、この種類のシェルを使用することを前提としています。
Azure Machine Learning ワークスペース。 ワークスペースを作成する手順については、「 設定」を参照してください。
次の Azure ロールベースのアクセス制御 (Azure RBAC) ロールの少なくとも 1 つを持つユーザー アカウント。
- Azure Machine Learning ワークスペースの所有者ロール
- Azure Machine Learning ワークスペースの共同作成者ロール
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*アクセス許可を持つカスタム ロール
詳細については、「Azure Machine Learning ワークスペースへのアクセスの管理」を参照してください。
必要に応じて、 Docker エンジンがインストールされ、ローカルで実行されます。 この前提条件を強くお勧めします。 モデルをローカルにデプロイするために必要であり、デバッグに役立ちます。
システムを準備する
- Azure CLI
- Python SDK
-
[ スタジオ](#tab/azure-studio)
環境変数の設定
Azure CLI で使用する既定値を構成できます。 サブスクリプション、ワークスペース、およびリソース グループの値が複数回渡されないようにするには、次のコードを実行します。
az account set --subscription <subscription-ID>
az configure --defaults workspace=<Azure-Machine-Learning-workspace-name> group=<resource-group-name>
examples リポジトリをクローンします
このアーティクルに従って、まずサンプル リポジトリ (azureml-examples) を複製します。 次に、リポジトリの cli/ ディレクトリに移動します。
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples
cd cli
ヒント
--depth 1を使用してリポジトリに最新のコミットのみを複製します。これにより、操作を完了するために必要な時間が短縮されます。
このチュートリアルのコマンドは cli ディレクトリの deploy-safe-rollout-online-endpoints.sh ファイルにあり、YAML 構成ファイルは endpoints/online/managed/sample/ サブディレクトリにあります。
注意
Kubernetes オンライン エンドポイントの YAML 構成ファイルは、endpoints/online/kubernetes/ サブディレクトリにあります。
エンドポイントとデプロイを定義する
オンライン エンドポイントは、オンライン (リアルタイム) の推論に使用されます。 オンライン エンドポイントには、クライアントからデータを受信して、リアルタイムで応答を返信できる準備が整ったデプロイが含まれています。
エンドポイントを定義する
次の表は、エンドポイントを定義する際に指定する主な属性を一覧表示しています。
| 属性 | 必須または省略可能 | 内容 |
|---|---|---|
| 名前 | 必須 | エンドポイントの名前。 Azure リージョンで一意である必要があります。 名前付け規則の詳細については、 Azure Machine Learning オンライン エンドポイントとバッチ エンドポイントに関するページを参照してください。 |
| 認証モード | オプション | エンドポイントの認証方法。 キーベースの認証、 key、Azure Machine Learning トークン ベースの認証 、 aml_tokenから選択できます。 キーには有効期限がありませんが、トークンには有効期限があります。 認証の詳細については、「 オンライン エンドポイントのクライアントを認証する」を参照してください。 |
| 内容 | オプション | エンドポイントの説明。 |
| タグ | オプション | エンドポイントのタグのディクショナリ。 |
| トラフィック | オプション | デプロイ間でトラフィックをルーティングする方法に関するルール。 トラフィックはキーと値のペアのディクショナリとして表します。ここで、キーはデプロイ名を表し、値はそのデプロイへのトラフィックの割合を表します。 トラフィックは、エンドポイントの下のデプロイが作成された後にのみ設定できます。 デプロイの作成後に、オンライン エンドポイントのトラフィックを更新することもできます。 ミラー化されたトラフィックの使用方法の詳細については、「 新しいデプロイへのライブ トラフィックのごく一部の割り当て」を参照してください。 |
| トラフィックのミラーリング | オプション | デプロイにミラーリングするライブ トラフィックの割合。 ミラー化されたトラフィックを使用する方法の詳細については、「ミラー化されたトラフィック を使用してデプロイをテストする」を参照してください。 |
エンドポイントの作成時に指定できる属性の完全な一覧については、 CLI (v2) オンライン エンドポイント YAML スキーマを参照してください。 Python 用 Azure Machine Learning SDK のバージョン 2 については、「 ManagedOnlineEndpoint クラス」を参照してください。
デプロイを定義する
デプロイは、実際の推論を行うモデルをホストするために必要なリソースのセットです。 次の表は、デプロイを定義する際に指定する主な属性について説明しています。
| 属性 | 必須または省略可能 | 内容 |
|---|---|---|
| 名前 | 必須 | デプロイメントの名前。 |
| エンドポイント名 | 必須 | デプロイを作成するエンドポイントの名前。 |
| モデル | オプション | デプロイに使用するモデル。 この値は、ワークスペース内の既存のバージョン管理されたモデルへの参照またはインライン モデルの仕様のいずれかです。 この記事の例では、 scikit-learn モデルは回帰を行います。 |
| コード パス | オプション | モデルをスコア付けするためのすべての Python ソース コードを含むローカル開発環境上のフォルダーへのパス。 入れ子になったディレクトリとパッケージを使用できます。 |
| スコアリング スクリプト | オプション | 指定された入力要求に対してモデルを実行する Python コード。 この値には、ソース コード フォルダー内のスコアリング ファイルへの相対パスを指定できます。 スコアリング スクリプトは、デプロイされた Web サービスに送信されたデータを受け取り、それをモデルに渡します。 その後、スクリプトはモデルを実行して、その応答をクライアントに返します。 スコアリング スクリプトはモデルに固有のものであり、モデルが入力として期待し、出力として返すデータを理解する必要があります。 この記事の例では、score.py ファイルを使用します。 この Python コードには、 init 関数と run 関数が含まれている必要があります。 init関数は、モデルの作成または更新後に呼び出されます。 たとえば、モデルをメモリにキャッシュするために使用できます。 run 関数は、実際のスコアリングおよび予測を実行するために、エンドポイントが呼び出されるたびに呼び出されます。 |
| 環境 | 必須 | モデルとコードをホスティングする環境。 この値は、ワークスペース内の既存のバージョン管理された環境への参照、またはインライン環境仕様のいずれかになります。 この環境には、Conda の依存関係を持つ Docker イメージ、Dockerfile、または登録済みの環境を使用できます。 |
| インスタンスの種類 | 必須 | デプロイに使用する仮想マシンのサイズ。 サポートされているサイズの一覧については、 マネージド オンライン エンドポイント SKU の一覧を参照してください。 |
| インスタンス数 | 必須 | デプロイに使用するインスタンスの数。 期待するワークロードに基づいて値を設定します。 高可用性を実現するために、少なくとも 3 つのインスタンスを使用することをお勧めします。 Azure Machine Learning では、アップグレードを実行するために追加の 20% が予約されます。 詳細については、 Azure Machine Learning オンライン エンドポイントとバッチ エンドポイントに関するページを参照してください。 |
デプロイの作成時に指定できる属性の完全な一覧については、 CLI (v2) マネージド オンライン デプロイ YAML スキーマに関する説明を参照してください。 Python SDK のバージョン 2 については、 ManagedOnlineDeployment クラスを参照してください。
- Azure CLI
- Python SDK
-
[ スタジオ](#tab/azure-studio)
オンライン エンドポイントの作成
最初にエンドポイント名を設定してから構成します。 この記事では、endpoints/online/managed/sample/endpoint.yml ファイルを使用してエンドポイントを構成します。 このファイルには、次の行が含まれています。
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: my-endpoint
auth_mode: key
次の表では、エンドポイント YAML 形式で使用されるキーについて説明します。 これらの属性を指定する方法については、 CLI (v2) オンライン エンドポイント YAML スキーマを参照してください。 マネージド オンライン エンドポイントに関連する制限については、 Azure Machine Learning オンライン エンドポイントとバッチ エンドポイントに関するページを参照してください。
| 鍵 | 内容 |
|---|---|
$schema |
(省略可能) YAML スキーマ。 YAML ファイルで使用可能なすべてのオプションを表示するには、前のコード ブロックのスキーマをブラウザーで表示します。 |
name |
エンドポイントの名前。 |
auth_mode |
認証モード。 キーベースの認証に key を使用します。 Azure Machine Learning のトークン ベースの認証に aml_token を使用します。 最新のトークンを取得するには、az ml online-endpoint get-credentials コマンドを使用します。 |
オンライン エンドポイントを作成するには。
次の Unix コマンドを実行して、エンドポイント名を設定します。
YOUR_ENDPOINT_NAMEを一意の名前に置き換えます。export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"重要
エンドポイント名は Azure リージョン内で一意である必要があります。 たとえば、Azure
westus2リージョンでは、my-endpointという名前のエンドポイントは 1 つしか使用できません。次のコードを実行して、クラウドにエンドポイントを作成します。 このコードでは、endpoint.yml ファイルを使用してエンドポイントを構成します。
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
青いデプロイを作成する
エンドポイント/オンライン/マネージド/サンプル/blue-deployment.yml ファイルを使用して、 blueという名前のデプロイの主要な側面を構成できます。 このファイルには、次の行が含まれています。
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: ../../model-1/model/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yaml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
blue-deployment.yml ファイルを使用してエンドポイントの blue デプロイを作成するには、次のコマンドを実行します。
az ml online-deployment create --name blue --endpoint-name $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment.yml --all-traffic
重要
az ml online-deployment create コマンドの--all-traffic フラグは、エンドポイント トラフィックの 100% を新しく作成されたblueデプロイに割り当てます。
blue-deployment.yaml ファイルの path 行は、ファイルのアップロード先を指定します。 Azure Machine Learning CLI では、この情報を使用してファイルをアップロードし、モデルと環境を登録します。 運用環境のベスト プラクティスとして、モデルと環境を登録し、YAML コードで登録済みの名前とバージョンを個別に指定する必要があります。 model: azureml:my-model:1など、モデルの形式model: azureml:<model-name>:<model-version>を使用します。 環境では、environment: azureml:my-env:1などの形式environment: azureml:<environment-name>:<environment-version>を使用します。
登録するためには、model と environment の YAML 定義を別々の YAML ファイルに抽出し、az ml model create コマンドと az ml environment create コマンドを使用します。 これらのコマンドの詳細については、 az ml model create -h と az ml environment create -hを実行します。
モデルを資産として登録する方法の詳細については、「 Azure CLI または Python SDK を使用してモデルを登録する」を参照してください。 環境の作成の詳細については、「 カスタム環境の作成」を参照してください。
![[ローカル ファイルからモデルを登録する] ページのスクリーンショット。[参照] の下の [フォルダーの参照] が強調表示されています。](media/how-to-safely-rollout-managed-endpoints/register-model-folder.png?view=azureml-api-2#lightbox)
![[モデル一覧] ページのスクリーンショット。モデルの一覧で、model-1 モデルが選択されています。デプロイとリアルタイム エンドポイントが強調表示されます。](media/how-to-safely-rollout-managed-endpoints/deploy-models-page.png?view=azureml-api-2#lightbox)
![マネージド オンライン エンドポイントを作成するためのウィザードの [エンドポイントの選択] ページのスクリーンショット。エンドポイント名といくつかの設定が表示されます。](media/how-to-safely-rollout-managed-endpoints/online-endpoint-wizard.png?view=azureml-api-2#lightbox)
![マネージド オンライン エンドポイントを作成するためのウィザードのレビュー ページのスクリーンショット。設定情報が表示され、[作成] が強調表示されます。](media/how-to-safely-rollout-managed-endpoints/review-deployment-creation-page.png?view=azureml-api-2#lightbox)
![スタジオの [エンドポイント] ページのスクリーンショット。エンドポイントと作成が強調表示され、1 つのエンドポイントが表示されます。](media/how-to-safely-rollout-managed-endpoints/endpoint-create-managed-online-endpoint.png?view=azureml-api-2#lightbox)
既存のデプロイを確認する
既存のデプロイを確認する方法の 1 つは、特定の入力要求に対してモデルをスコア付けできるようにエンドポイントを呼び出すことです。 Azure CLI または Python SDK を使用してエンドポイントを呼び出す場合は、受信トラフィックを受信するデプロイの名前を指定できます。
注意
Azure CLI または Python SDK とは異なり、Azure Machine Learning Studio では、エンドポイントを呼び出すときにデプロイを指定する必要があります。
デプロイ名を使用してエンドポイントを呼び出す
エンドポイントを呼び出すときに、トラフィックを受信するデプロイの名前を指定できます。 この場合、Azure Machine Learning はエンドポイント トラフィックを指定されたデプロイに直接ルーティングし、その出力を返します。 Azure Machine Learning CLI v2 の--deployment-name オプション、または Python SDK v2 の deployment_name オプションを使用してデプロイを指定できます。
デプロイを指定せずにエンドポイントを呼び出す
トラフィックを受信するデプロイを指定せずにエンドポイントを呼び出すと、Azure Machine Learning は、トラフィック制御設定に基づいてエンドポイントの受信トラフィックをエンドポイントのデプロイにルーティングします。
トラフィック制御設定では、受信トラフィックの指定された割合がエンドポイント内の各デプロイに割り当てられます。 たとえば、トラフィック ルールでエンドポイント内の特定のデプロイが受信トラフィックを 40% 受信するように指定している場合、Azure Machine Learning はエンドポイント トラフィックの 40% をそのデプロイにルーティングします。
- Azure CLI
- Python SDK
-
[ スタジオ](#tab/azure-studio)
既存のエンドポイントとデプロイの状態を表示するには、次のコマンドを実行します。
az ml online-endpoint show --name $ENDPOINT_NAME
az ml online-deployment show --name blue --endpoint $ENDPOINT_NAME
出力には、 $ENDPOINT_NAME エンドポイントと blue デプロイに関する情報が一覧表示されます。
サンプル データを使用してエンドポイントをテストする
エンドポイントは、 invoke コマンドを使用して呼び出すことができます。 次のコマンドでは、 sample-request.json JSON ファイルを使用してサンプル要求を送信します。
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
![エンドポイント ページの [詳細] タブのスクリーンショット。デプロイと属性に関する情報が表示されます。](media/how-to-safely-rollout-managed-endpoints/managed-endpoint-details-page.png?view=azureml-api-2#lightbox)
![エンドポイント ページの [テスト] タブのスクリーンショット。青色のデプロイが選択され、入力データと出力データが表示されます。](media/how-to-safely-rollout-managed-endpoints/test-deployment.png?view=azureml-api-2#lightbox)
より多くのトラフィックを処理できるように既存のデプロイをスケーリングする
- Azure CLI
- Python SDK
-
[ スタジオ](#tab/azure-studio)
オンライン エンドポイントを使用した機械学習モデルのデプロイとスコア付けで説明されているデプロイでは、デプロイ YAML ファイルで instance_count の値を 1 に設定します。 update コマンドを使用してスケールアウトできます。
az ml online-deployment update --name blue --endpoint-name $ENDPOINT_NAME --set instance_count=2
注意
前のコマンドでは、 --set オプションによってデプロイ構成がオーバーライドされます。 または、--file オプションを使用して、YAML ファイルを更新し、update コマンドに入力として渡すことができます。
![[展開プロパティの更新] ダイアログのスクリーンショット。インスタンス数の値は 2 で、[更新] ボタンが表示されます。](media/how-to-safely-rollout-managed-endpoints/scale-blue-deployment.png?view=azureml-api-2#lightbox)
新しいモデルをデプロイするが、トラフィックを送信しない
- Azure CLI
- Python SDK
-
[ スタジオ](#tab/azure-studio)
green という名前の新しいデプロイを作成します。
az ml online-deployment create --name green --endpoint-name $ENDPOINT_NAME -f endpoints/online/managed/sample/green-deployment.yml
greenデプロイにトラフィックを明示的に割り当てていないため、そこにはトラフィックがゼロに割り当てられています。 次のコマンドを使用して、その事実を確認できます。
az ml online-endpoint show -n $ENDPOINT_NAME --query traffic
新しいデプロイをテストする
greenデプロイには 0% のトラフィックが割り当てられていますが、--deployment オプションを使用して直接呼び出すことができます。
az ml online-endpoint invoke --name $ENDPOINT_NAME --deployment-name green --request-file endpoints/online/model-2/sample-request.json
トラフィック ルールを介さずに、REST クライアントを使用して直接デプロイを呼び出したい場合、azureml-model-deployment: <deployment-name> という HTTP ヘッダーを設定します。 次のコードでは、URL 用クライアント (cURL) を使用してデプロイを直接呼び出します。 Unix または Windows Subsystem for Linux (WSL) 環境でコードを実行できます。 $ENDPOINT_KEY値を取得する手順については、「データ プレーン操作のキーまたはトークンを取得する」を参照してください。
# get the scoring uri
SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query scoring_uri)
# use curl to invoke the endpoint
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --header "azureml-model-deployment: green" --data @endpoints/online/model-2/sample-request.json
![[校繂] ページのスクリーンショット。エンドポイント、デプロイ、モデル、環境、コンピューティング インスタンス、トラフィックに関する情報が表示されます。](media/how-to-safely-rollout-managed-endpoints/add-green-deployment-endpoint-page.png?view=azureml-api-2#lightbox)
![[エンドポイントの選択] ページのスクリーンショット。[既存] オプション、[次へ] ボタン、およびエンドポイントの横にあるチェックマークが強調表示されます。](media/how-to-safely-rollout-managed-endpoints/add-green-deployment-models-page.png?view=azureml-api-2#lightbox)
ミラーリングされたトラフィックを使ってデプロイをテストする
greenデプロイをテストした後、その割合のトラフィックをコピーして、greenデプロイに送信することで、エンドポイントへのライブ トラフィックの割合をミラーリングできます。 トラフィック ミラーリング ( シャドウとも呼ばれます) は、クライアントに返される結果を変更しません。要求の 100% は引き続き blue デプロイに送信されます。 トラフィックのミラー化された割合がコピーされ、 green デプロイにも送信されるため、クライアントに影響を与えずにメトリックとログを収集できます。
ミラーリングは、クライアントに影響を与えずに新しいデプロイを検証する場合に便利です。 たとえば、ミラーリングを使用して、待機時間が許容範囲内にあるかどうかを確認したり、HTTP エラーがないことを確認したりできます。 新しいデプロイをテストするためのトラフィック ミラーリング (シャドウ) の使用は、 シャドウ テストとも呼ばれます。 ミラー化されたトラフィックを受信するデプロイ (この場合は green デプロイ) は、 シャドウ デプロイと呼ばれることもできます。
ミラーリングには次の制限事項があります。
- ミラーリングは、バージョン 2.4.0 以降の Azure Machine Learning CLI とバージョン 1.0.0 以降の Python SDK でサポートされています。 古いバージョンの Azure Machine Learning CLI または Python SDK を使用してエンドポイントを更新すると、ミラー トラフィック設定が失われます。
- 現在、ミラーリングは、Kubernetes オンライン エンドポイントではサポートされていません。
- トラフィックは、エンドポイント内の 1 つのデプロイにのみミラーリングできます。
- ミラー化できるトラフィックの最大割合は 50% です。 この上限により、 エンドポイント帯域幅クォータへの影響が制限されます。既定値は 5 MBps です。 割り当てられたクォータを超えると、エンドポイントの帯域幅が調整されます。 帯域幅調整の監視については、「 帯域幅の調整」を参照してください。
また、次の動作にも注意してください。
- 両方ではなく、ライブ トラフィックまたはミラー化されたトラフィックのみを受信するようにデプロイを構成できます。
- エンドポイントを呼び出すときに、そのデプロイの名前 (シャドウ デプロイでも) を指定して、予測を返すことができます。
- エンドポイントを呼び出し、受信トラフィックを受信するデプロイの名前を指定すると、Azure Machine Learning はトラフィックをシャドウ デプロイにミラーリングしません。 デプロイを指定しない場合、Azure Machine Learning は、エンドポイントに送信されたトラフィックからシャドウ デプロイにトラフィックをミラーリングします。
ミラー化されたトラフィックの 10% を受信するように green デプロイを設定した場合、クライアントは引き続き blue 展開からのみ予測を受け取ります。
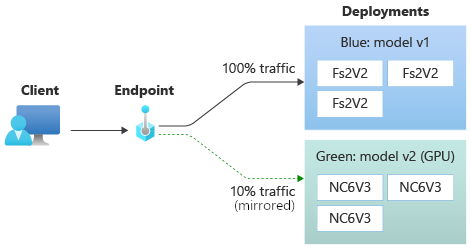
- Azure CLI
- Python SDK
-
[ スタジオ](#tab/azure-studio)
次のコマンドを使用して、トラフィックの 10% をミラーリングし、 green デプロイに送信します。
az ml online-endpoint update --name $ENDPOINT_NAME --mirror-traffic "green=10"
受信トラフィックを受信するデプロイを指定せずにエンドポイントを複数回呼び出すことで、ミラー化されたトラフィックをテストできます。
for i in {1..20} ; do
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
done
指定した割合のトラフィックが green デプロイに送信されることを確認するには、デプロイのログを確認します。
az ml online-deployment get-logs --name green --endpoint $ENDPOINT_NAME
テスト後、ミラー トラフィックを 0 に設定して、ミラーリングを無効にすることができます。
az ml online-endpoint update --name $ENDPOINT_NAME --mirror-traffic "green=0"
![[トラフィック割り当ての更新] ダイアログのスクリーンショット。緑色のデプロイの割り当ては 10% で、ミラーリングが有効になっています。](media/how-to-safely-rollout-managed-endpoints/mirror-traffic-green-deployment.png?view=azureml-api-2#lightbox)
![エンドポイント ページの [詳細] タブのスクリーンショット。ミラー化されたトラフィックの割り当てでは、緑のデプロイの割合はトラフィックの 10% です。](media/how-to-safely-rollout-managed-endpoints/endpoint-details-showing-mirrored-traffic-allocation.png?view=azureml-api-2#lightbox)
![エンドポイント ページの [詳細] タブのスクリーンショット。ライブ トラフィックの割り当てでは、青色のデプロイは 100% になります。トラフィックはミラー化されません。](media/how-to-safely-rollout-managed-endpoints/endpoint-details-showing-disabled-mirrored-traffic.png?view=azureml-api-2#lightbox)
ライブ トラフィックの小さい割合を新しいデプロイに割り当てる
greenデプロイをテストした後、それに対するトラフィックのごく一部を割り当てます。
- Azure CLI
- Python SDK
-
[ スタジオ](#tab/azure-studio)
az ml online-endpoint update --name $ENDPOINT_NAME --traffic "blue=90 green=10"
ヒント
トラフィックの合計割合は、トラフィックを無効にするには 0% に、トラフィックを有効にするには 100% にする必要があります。
green デプロイは、すべてのライブ トラフィックの 10% を受け取るようになりました。 クライアントは、 blue と green の両方のデプロイから予測を受け取ります。

すべてのトラフィックを新しいデプロイに送信する
greenデプロイに完全に満足したら、すべてのトラフィックをそれに切り替えます。
- Azure CLI
- Python SDK
-
[ スタジオ](#tab/azure-studio)
az ml online-endpoint update --name $ENDPOINT_NAME --traffic "blue=0 green=100"
以前のデプロイを削除する
次の手順に従って、マネージド オンライン エンドポイントから個々のデプロイを削除します。 個々のデプロイを削除しても、マネージド オンライン エンドポイント内の他のデプロイには影響しません。
- Azure CLI
- Python SDK
-
[ スタジオ](#tab/azure-studio)
az ml online-deployment delete --name blue --endpoint $ENDPOINT_NAME --yes --no-wait
エンドポイントとデプロイを削除する
エンドポイントとデプロイを使用する予定がない場合は、削除してください。 エンドポイントを削除すると、その基になるデプロイもすべて削除されます。
- Azure CLI
- Python SDK
-
[ スタジオ](#tab/azure-studio)
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait