適用対象: Azure CLI ml 拡張機能 v2 (現行)Python SDK azure-ai-ml v2 (現行)
Azure CLI ml 拡張機能 v2 (現行)Python SDK azure-ai-ml v2 (現行)
この記事では、 SweepJob クラスを使用して、Azure Machine Learning SDK v2 と CLI v2 を使用して効率的なハイパーパラメーター調整を自動化する方法について説明します。
- パラメーター検索スペースを定義する
- サンプリング アルゴリズムを選択する
- 最適化の目標を設定する
- 早期終了ポリシーを構成する
- スイープ ジョブの制限を設定する
- 実験を送信する
- トレーニング ジョブを視覚化する
- 最適な構成を選択する
ハイパーパラメーター調整とは
ハイパーパラメーターは、モデルトレーニングを 制御する調整可能な設定です。 たとえば、ニューラル ネットワークの場合は、非表示レイヤーの数とレイヤーあたりのノード数を選択します。 モデルのパフォーマンスはこれらの値に大きく依存します。
ハイパーパラメーターの調整 (または ハイパーパラメーターの最適化) は、最適なパフォーマンスを実現するハイパーパラメーター構成を見つけるプロセスです。 多くの場合、このプロセスは計算コストが高く、手動です。
Azure Machine Learning を使用すると、ハイパーパラメーターの調整を自動化し、実験を並行して行ってハイパーパラメーターを効率的に最適化できます。
検索空間を定義する
各ハイパーパラメーターに対して定義された値の範囲を調べることで、ハイパーパラメーターを調整します。
ハイパーパラメーターは、不連続または連続であり、 パラメーター式で表される値の分布を持つことができます。
不連続ハイパーパラメーター
不連続ハイパーパラメーターは、不連続値の中の Choice として指定します。
Choice には次のものを指定できます。
- 1 つまたは複数のコンマ区切りの値
-
rangeオブジェクト - 任意の
listオブジェクト
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32, 64, 128]),
number_of_hidden_layers=Choice(values=range(1,5)),
)
参照:
この場合、 batch_size は [16, 32, 64, 128] のいずれかを受け取り、 number_of_hidden_layers は [1, 2, 3, 4] のいずれかを取ります。
次の高度な不連続ハイパーパラメーターは、分布を使用して指定することもできます。
-
QUniform(min_value, max_value, q)- round(Uniform(min_value, max_value) / q) * q などの値を返します -
QLogUniform(min_value, max_value, q)- round(exp(Uniform(min_value, max_value)) / q) * q などの値を返します -
QNormal(mu, sigma, q)- round(Normal(mu, sigma) / q) * q などの値を返します -
QLogNormal(mu, sigma, q)- round(exp(Normal(mu, sigma)) / q) * q などの値を返します
連続ハイパーパラメーター
連続ハイパーパラメーターは、値の連続範囲に対する分布として指定されます。
-
Uniform(min_value, max_value)- min_value と max_value の間で均等に分布した値を返します -
LogUniform(min_value, max_value)- 戻り値の対数が均等に分布するように、exp(Uniform(min_value, max_value)) に従って得られた値を返します -
Normal(mu, sigma): 平均ミューと標準偏差シグマを使用して正規分布された実際の値を返します -
LogNormal(mu, sigma)- 戻り値の対数が正規分布されるように、exp(Normal(mu, sigma)) に従って得られた値を返します
パラメーター空間定義の例を次に示します。
from azure.ai.ml.sweep import Normal, Uniform
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
)
参照:
このコードでは、2 つのパラメーター learning_rate と keep_probability で検索空間を定義します。
learning_rate は、平均値 10 と標準偏差 3 の正規分布になります。
keep_probability は、最小値 0.05 と最大値 0.1 の一様分布になります。
CLI の場合は、 スイープ ジョブの YAML スキーマ を使用して、検索空間を定義します。
search_space:
conv_size:
type: choice
values: [2, 5, 7]
dropout_rate:
type: uniform
min_value: 0.1
max_value: 0.2
ハイパーパラメーター空間のサンプリング
ハイパーパラメーター空間のサンプリング方法を指定します。 Azure Machine Learning では、次の機能がサポートされます。
- ランダム サンプリング
- グリッド サンプリング
- ベイジアン サンプリング
ランダム サンプリング
ランダム サンプリングでは、不連続ハイパーパラメーターと連続ハイパーパラメーターがサポートされ、パフォーマンスの低いジョブの早期終了がサポートされます。 多くのユーザーは、ランダム サンプリングから始めて、有望なリージョンを特定してから調整します。
ランダム サンプリングでは、値は定義された検索空間から均一に (または指定されたランダム ルールを介して) 描画されます。 コマンド ジョブを作成したら、 sweep を使用してサンプリング アルゴリズムを定義します。
from azure.ai.ml.entities import CommandJob
from azure.ai.ml.sweep import RandomSamplingAlgorithm, SweepJob, SweepJobLimits
command_job = CommandJob(
inputs=dict(kernel="linear", penalty=1.0),
compute=cpu_cluster,
environment=f"{job_env.name}:{job_env.version}",
code="./scripts",
command="python scripts/train.py --kernel $kernel --penalty $penalty",
experiment_name="sklearn-iris-flowers",
)
sweep = SweepJob(
sampling_algorithm=RandomSamplingAlgorithm(seed=999, rule="sobol", logbase="e"),
trial=command_job,
search_space={"ss": Choice(type="choice", values=[{"space1": True}, {"space2": True}])},
inputs={"input1": {"file": "top_level.csv", "mode": "ro_mount"}}, # type:ignore
compute="top_level",
limits=SweepJobLimits(trial_timeout=600),
)
参照:
sobol
Sobol は、空間充填と再現性を向上させる準ランダム シーケンスです。 シードを指定し、rule="sobol"にRandomSamplingAlgorithmを設定します。
from azure.ai.ml.sweep import RandomSamplingAlgorithm
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = RandomSamplingAlgorithm(seed=123, rule="sobol"),
...
)
リファレンス: RandomSamplingAlgorithm
グリッド サンプリング
グリッド サンプリングでは、不連続ハイパーパラメーターがサポートされています。 検索空間を徹底的に検索する予算を確保できる場合は、グリッド サンプリングを使用します。 パフォーマンスの低いジョブの早期終了がサポートされています。
グリッド サンプリングでは、考えられるすべての値に対して単純なグリッド検索を実行します。 グリッド サンプリングは choice ハイパーパラメーターでのみ使用できます。 たとえば、次の空間には 6 個のサンプルがあります。
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32]),
number_of_hidden_layers=Choice(values=[1,2,3]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "grid",
...
)
参照: 選択肢
ベイジアン サンプリング
ベイジアン サンプリング (ベイジアン最適化) では、主要メトリックを効率的に改善するために、以前の結果に基づいて新しいサンプルが選択されます。
ベイジアン サンプリングは、ハイパーパラメーター空間を探索するための十分な予算がある場合に推奨されます。 最適な結果を得るために、ジョブの最大数は、調整するハイパーパラメーターの数の 20 倍以上にすることをお勧めします。
同時実行ジョブ数は調整プロセスの有効性に影響を与えます。 同時実行ジョブ数が少ないほど、サンプリングの収束が向上する可能性があります。これは、並列処理の次数が小さいほど、以前に完了したジョブの恩恵を受けるジョブの数が増えるためです。
ベイジアン サンプリングでは、 choice、 uniform、および quniform 分布がサポートされます。
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
...
)
参照:
スイープの目的を指定する
ハイパーパラメーター調整で最適化する主要メトリックと目標を指定して、一括処理ジョブの目的を定義します。 各トレーニング ジョブは、この主要メトリックに対して評価されます。 早期終了ポリシーでは、主要メトリックを使用してパフォーマンスの低いジョブを特定します。
-
primary_metric: 主要メトリックの名前は、トレーニング スクリプトによってログに記録されているメトリック名と完全に一致する必要があります -
goal:MaximizeまたはMinimizeのいずれかを指定できます。ジョブを評価する際に主要メトリックを最大化するか最小化するかを決定します。
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
primary_metric="accuracy",
goal="Maximize",
)
参照:
このサンプルでは "accuracy" を最大化します。
ハイパーパラメーターの調整のためのログ メトリック
トレーニング スクリプトでは、スイープ ジョブで予想される正確な名前でプライマリ メトリックをログに記録する 必要があります 。
次のサンプル スニペットで、トレーニング スクリプトの主要メトリックをログします。
import mlflow
mlflow.log_metric("accuracy", float(val_accuracy))
トレーニング スクリプトでは val_accuracy が計算され、主要メトリック "accuracy" としてログされます。 メトリックがログされるたびに、これをハイパーパラメーター調整サービスが受信します。 レポートの頻度は、ご自身で決定してください。
トレーニング ジョブの値のログに関する詳細については、Azure Machine Learning トレーニング ジョブでのログの有効化に関する記事を参照してください。
早期終了ポリシーを指定する
効率を向上させるために、パフォーマンスの低いジョブを早期に終了します。
次のパラメーターを構成して、ポリシーを適用するタイミングを制御できます。
-
evaluation_interval: ポリシーを適用する頻度。 トレーニング スクリプトによってログに記録されるたびに、主要メトリックは 1 間隔としてカウントされます。evaluation_intervalに 1 を指定すると、トレーニング スクリプトが主要メトリックを報告するたびにポリシーが適用されます。evaluation_intervalに 2 を指定すると、ポリシーは 1 回おきに適用されます。 指定しないと、evaluation_intervalは既定で 0 に設定されます。 -
delay_evaluation: 指定した間隔数の期間、最初のポリシー評価を遅延させます。 これは省略可能なパラメーターです。すべての構成を最小数の間隔で実行できるようにして、トレーニング ジョブの早期終了を回避します。 指定すると、このポリシーは delay_evaluation 以上の evaluation_interval の倍数ごとに適用されます。 指定しないと、delay_evaluationは既定で 0 に設定されます。
Azure Machine Learning では、以下の早期終了ポリシーがサポートされています。
バンディット ポリシー
バンディット ポリシー では、余裕期間または金額と評価間隔が使用されます。 プライマリ メトリックが最適なジョブから許容されるスラックの範囲外に外れた場合、ジョブが終了します。
次の構成パラメーターを指定します。
slack_factorまたはslack_amount: 最適なジョブに対する許容される差。slack_factorは比率です。slack_amountは絶対値です。たとえば、間隔 10 で適用されるバンディット ポリシーについて考えてみます。 主要メトリックを最大化するという目標があり、間隔 10 で最善のパフォーマンスになるジョブで主要メトリックが 0.8 であると報告されたとします。 ポリシーで 0.2 の
slack_factorが指定された場合、間隔 10 で最適なメトリックになるトレーニング ジョブのうち、0.66 (0.8/(1+slack_factor)) 未満のものが終了されます。evaluation_interval: (省略可能) ポリシーを適用する頻度delay_evaluation: (省略可能) 指定した間隔数の期間、最初のポリシー評価を遅延します
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(slack_factor = 0.1, delay_evaluation = 5, evaluation_interval = 1)
参照: BanditPolicy
この例では、評価間隔 5 から始めて、メトリックが報告される間隔ごとに早期終了ポリシーが適用されます。 最適なメトリックが (1/(1 + 0.1) 未満、または最善のパフォーマンスのジョブのうち 91% 未満のジョブはすべて終了されます。
中央値の停止ポリシー
中央値の停止は、ジョブによって報告された主要メトリックの移動平均に基づく早期終了ポリシーです。 このポリシーは、すべてのトレーニング ジョブを対象に移動平均を計算し、主要メトリック値が平均の中央値よりも低いジョブを終了します。
このポリシーでは、次の構成パラメーターを指定できます。
-
evaluation_interval: ポリシーを適用する頻度 (省略可能なパラメーター)。 -
delay_evaluation: 指定した間隔数の期間、最初のポリシー評価を遅延させます (省略可能なパラメーター)。
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(delay_evaluation = 5, evaluation_interval = 1)
この例では、評価間隔 5 から始めて、間隔ごとに早期終了ポリシーが適用されます。 すべてのトレーニング ジョブで、最適な主要メトリックが間隔 1:5 に対して移動平均の中央値未満の場合、ジョブは間隔 5 で停止されます。
切り捨て選択ポリシー
切り捨て選択を使用すると、各評価間隔で、パフォーマンスが最も低いジョブのうち、ある割合が取り消されます。 ジョブは、主要メトリックを使用して比較されます。
このポリシーでは、次の構成パラメーターを指定できます。
-
truncation_percentage: 各評価間隔で終了するパフォーマンスが最も低いジョブの割合。 1 ~ 99 の整数値。 -
evaluation_interval: (省略可能) ポリシーを適用する頻度 -
delay_evaluation: (省略可能) 指定した間隔数の期間、最初のポリシー評価を遅延します -
exclude_finished_jobs: ポリシーを適用するときに、完了したジョブを除外するかどうかを指定します
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5, exclude_finished_jobs=true)
この例では、評価間隔 5 から始めて、間隔ごとに早期終了ポリシーが適用されます。 ジョブは、間隔 5 でのそのパフォーマンスが間隔 5 のすべてのジョブのパフォーマンスの下位 20% に含まれる場合、間隔 5 で終了します。ポリシーを適用したときに完了済みのジョブは除外されます。
終了なしポリシー (既定)
ポリシーが指定されていない場合、ハイパーパラメーター調整サービスでは、すべてのトレーニング ジョブが完了するまで実行されます。
sweep_job.early_termination = None
参照: SweepJob
早期終了ポリシーを選択する
- 先のジョブまで終了せずに節約する保守的なポリシーでは、
evaluation_interval1 およびdelay_evaluation5 で中央値の停止ポリシーを検討します。 これらは保守的な設定であり、(評価データに基づいて) 主要メトリックに関する損失なしで約 25% から 35% の節約を実現できます。 - より積極的な節約では、バンディット ポリシーをより小さい許容される Slack で使用するか、切り捨て選択ポリシーをより大きな切り捨て率で使用します。
スイープ ジョブの制限を設定する
スイープ ジョブの制限を設定して、リソースの予算を制御します。
-
max_total_trials: トライアル ジョブの最大数。 1 ~ 1000 の整数にする必要があります。 -
max_concurrent_trials: (省略可能) 同時に実行できるトライアル ジョブの最大数。 指定しない場合、max_total_trials 数のジョブが並列で起動されます。 指定する場合は、1 から 1000 の整数にする必要があります。 -
timeout: スイープ ジョブ全体を実行できる最大時間 (秒単位)。 この制限に達すると、システムにより、すべてのトライアルを含めてスイープ ジョブが取り消されます。 -
trial_timeout: 各トライアル ジョブを実行できる最大時間 (秒単位)。 この制限に達すると、システムによってトライアルが取り消されます。
注
max_total_trials と timeout の両方を指定した場合、これら 2 つのしきい値のうちの最初のものに達すると、ハイパーパラメーター調整実験は終了します。
注
同時実行トライアル ジョブの数は、指定したコンピューティング先で使用可能なリソースによって制御されます。 目的の同時実行可能性のために、使用可能なリソースをコンピューティング先に確保する必要があります。
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=4, timeout=1200)
このコードでは、スイープ ジョブ全体のタイムアウトを 1,200 秒にして、一度に 4 つのトライアル ジョブを実行し、合計で最大 20 個のトライアル ジョブを使用するようにハイパーパラメーター調整実験を構成します。
ハイパーパラメーター調整実験を構成する
ハイパーパラメーター調整実験を構成するには、以下を指定します。
- 定義済みのハイパーパラメーター検索空間
- サンプリング アルゴリズム
- 早期終了ポリシー
- 目的
- リソース制限
- CommandJob または CommandComponent
- SweepJob
SweepJob は、コマンドまたはコマンド コンポーネントでハイパーパラメーター スイープを実行できます。
注
sweep_job で使用するコンピューティング先には、同時実行レベルを満たすのに十分なリソースが必要です。 コンピューティング先の詳細については、「コンピューティング ターゲット」を参照してください。
ハイパーパラメーター調整実験を構成します。
from azure.ai.ml import MLClient
from azure.ai.ml import command, Input
from azure.ai.ml.sweep import Choice, Uniform, MedianStoppingPolicy
from azure.identity import DefaultAzureCredential
# Create your base command job
command_job = command(
code="./src",
command="python main.py --iris-csv ${{inputs.iris_csv}} --learning-rate ${{inputs.learning_rate}} --boosting ${{inputs.boosting}}",
environment="AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu@latest",
inputs={
"iris_csv": Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/iris.csv",
),
"learning_rate": 0.9,
"boosting": "gbdt",
},
compute="cpu-cluster",
)
# Override your inputs with parameter expressions
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.01, max_value=0.9),
boosting=Choice(values=["gbdt", "dart"]),
)
# Call sweep() on your command job to sweep over your parameter expressions
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm="random",
primary_metric="test-multi_logloss",
goal="Minimize",
)
# Specify your experiment details
sweep_job.display_name = "lightgbm-iris-sweep-example"
sweep_job.experiment_name = "lightgbm-iris-sweep-example"
sweep_job.description = "Run a hyperparameter sweep job for LightGBM on Iris dataset."
# Define the limits for this sweep
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=10, timeout=7200)
# Set early stopping on this one
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation=5, evaluation_interval=2
)
参照:
command_jobは関数として呼び出されるため、パラメーター式を適用できます。
sweep関数は、trial、サンプリング アルゴリズム、目的、制限、コンピューティングで構成されます。 このスニペットは、コマンドまたはCommandComponentでハイパーパラメータースイープを実行するサンプルノートブックから来ています。 このサンプルでは、 learning_rate と boosting を調整します。 早期停止は MedianStoppingPolicyによって駆動されます。この場合、プライマリ メトリックがすべてのジョブの平均の中央値よりも悪いジョブが停止されます ( MedianStoppingPolicy リファレンスを参照)。
パラメーター値を受け取り、解析し、調整されるトレーニング スクリプトに渡す方法を確認するには、このコード サンプルを参照してください
重要
ハイパーパラメーターのスイープ ジョブはすべて、モデルと "すべてのデータ ローダー" の再構築を含め、トレーニングをゼロから再開します。 このコストを最小限に抑えるには、Azure Machine Learning パイプラインまたは手動プロセスを使用して、トレーニング ジョブの前に可能な限り多くのデータを準備します。
ハイパーパラメーター調整実験を送信する
ハイパーパラメーター調整構成を定義したら、ジョブを送信します。
# submit the sweep
returned_sweep_job = ml_client.create_or_update(sweep_job)
# get a URL for the status of the job
returned_sweep_job.services["Studio"].endpoint
参照:
ハイパーパラメーター調整のジョブを視覚化する
Azure Machine Learning Studio でハイパーパラメーター 調整ジョブを視覚化します。 詳細については、スタジオ内のジョブ記録の表示を参照してください。
メトリック グラフ: この視覚化では、ハイパーパラメーター調整の期間にわたってハイパードライブの子ジョブごとにログされたメトリックが追跡されます。 各線は 1 つの子実行を表し、各ポイントはランタイムのその反復での主要メトリックの値を測定します。

平行座標グラフ: この視覚化では、主要なメトリック パフォーマンスと個々のハイパーパラメーター値の相関関係が示されます。 グラフは、軸を移動する (軸ラベルを選択してドラッグする)、および 1 つの軸全体の値を強調表示する (1 つの軸を選択し、軸に沿って垂直方向にドラッグして、目的の値の範囲を強調表示する) ことで、インタラクティブになります。 並列座標グラフには、グラフの一番右の部分に軸が含まれ、そのジョブ インスタンスに設定されているハイパーパラメーターに対応する最適なメトリック値がプロットされます。 この軸は、グラフのグラデーションの凡例を、より読みやすい形式でデータに射影するために用意されています。

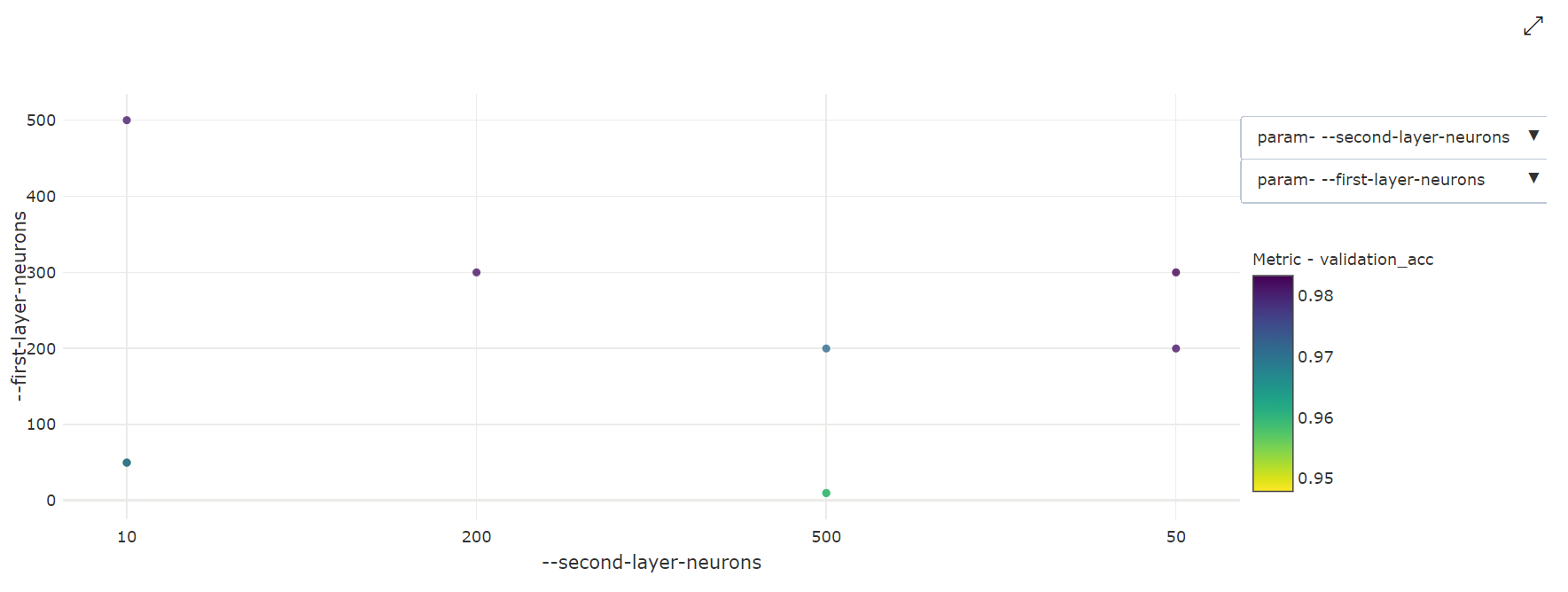
2 次元散布図: この視覚化では、2 つの個々のハイパーパラメーターとそれに関連付けられている主要なメトリック値の間の相関関係が示されます。
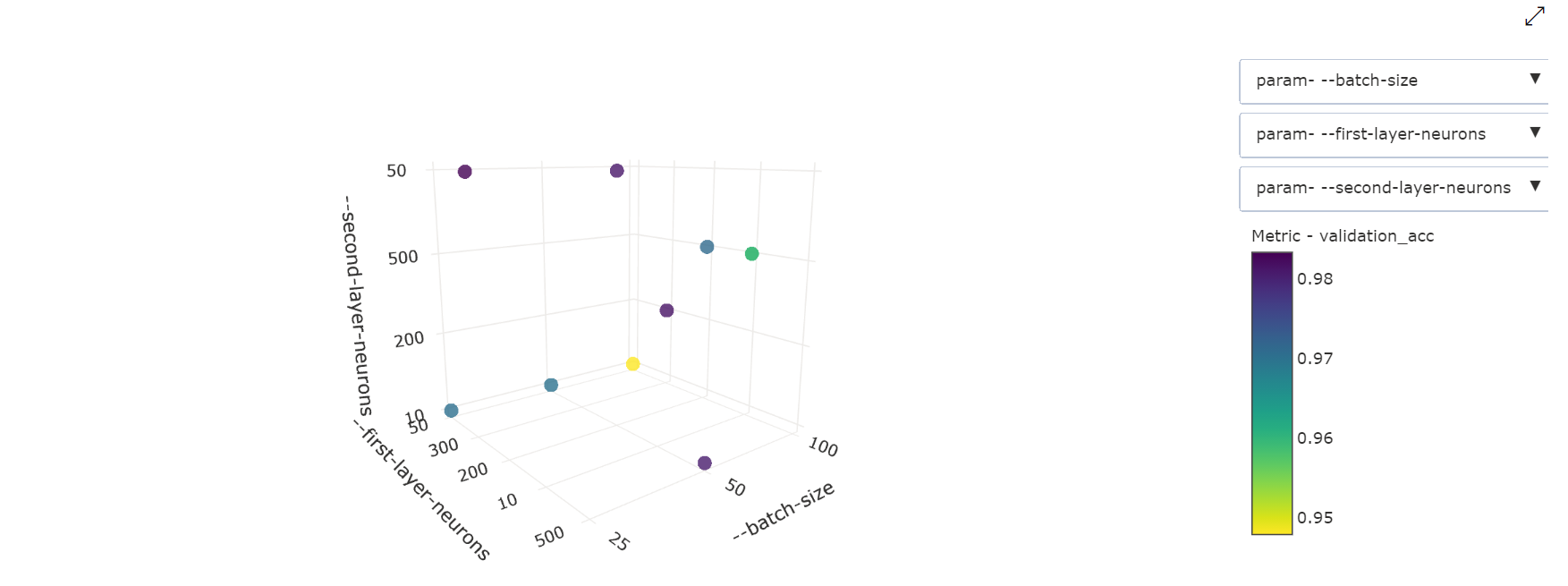
3 次元散布図: この視覚化は 2D と同じですが、主要なメトリック値との相関関係の 3 つのハイパーパラメーター ディメンションを使用できます。 グラフを選択してドラッグし、グラフの方向を変更し、3D 空間内のさまざまな相関関係を表示することもできます。
最良のトライアル ジョブを見つける
すべてのチューニング ジョブが完了したら、最適な評価版の出力を取得します。
# Download best trial model output
ml_client.jobs.download(returned_sweep_job.name, output_name="model")
参照:
CLI を使用して、最良のトライアル ジョブに関するすべての既定および名前付き出力と、スイープ ジョブのログをダウンロードできます。
az ml job download --name <sweep-job> --all
必要に応じて、最適な試用版の出力のみをダウンロードします。
az ml job download --name <sweep-job> --output-name model