この記事では、Azure Table Storage での信頼性のサポートについて説明します。可用性 ゾーン と 複数リージョンのデプロイによるリージョン内の回復性について説明します。
信頼性は、お客様と Microsoft の間で共有される責任です。 このガイドを使用して、特定のビジネス目標とアップタイム目標を満たす信頼性オプションを決定できます。
Table Storage は、構造化された NoSQL データをクラウドに格納するサービスです。 キーを介して各エンティティにアクセスし、一連の属性を含むスキーマレス ストアを提供します。 1 つのテーブルには、さまざまなプロパティ セットを持つエンティティを含めることができます。また、プロパティはさまざまなデータ型で構成できます。
Table Storage は、基になる Azure Storage プラットフォームを通じて、いくつかの信頼性機能を提供します。 Table Storage は、Azure Storage の一部として、テーブル データの高可用性と持続性を確保する同じ冗長オプション、可用性ゾーンのサポート、geo 機能を継承します。
この記事では、Table Storage での信頼性と可用性ゾーンのサポートについて説明します。 Azure における信頼性の詳細については、Azure の信頼性に関するページを参照してください。
注
Table Storage は、Azure Storage プラットフォームの一部です。 Table Storage の機能の一部は、多くの Azure Storage サービスで共通です。 この記事では、 Azure Storage を使用して、これらの一般的な機能を参照します。
運用環境のデプロイに関する推奨事項
運用環境では、次のアクションを実行します。
Table Storage リソースを含むストレージ アカウントに対して ZRS を有効にします。 ZRS では、プライマリ リージョン内の複数の可用性ゾーン間でデータが同期的にレプリケートされて、可用性が向上します。 このレプリケーションは、可用性ゾーンの障害から保護します。
リージョンの停止に対する回復性が必要で、ストレージ アカウントのプライマリ リージョンがペアになっている場合は、geo 冗長ストレージ (GRS) を有効にして、ペアになっているリージョンに非同期的にデータをレプリケートすることを検討してください。 サポートされているリージョンでは、geo ゾーン冗長ストレージ (GZRS) を使って、geo 冗長性とゾーン冗長性を組み合わせることができます。
大規模な生産ワークロードの場合、または高い回復性要件がある場合は、Azure Cosmos DB for Table の使用を検討してください。 Azure Cosmos DB for Table は、Table Storage 用に記述されたアプリケーションと互換性があります。 これは、待機時間の短い読み取りと書き込みの操作を大規模にサポートし、柔軟な整合性モデルを使用して複数のリージョン間で強力なグローバル分散を提供します。 また、組み込みのバックアップや、アプリケーションの回復性とパフォーマンスを向上させるその他の機能も提供します。
信頼性アーキテクチャの概要
Table Storage は、Azure Storage プラットフォーム インフラストラクチャ内で分散 NoSQL データベースとして動作します。 このサービスは、テーブル データの複数のコピーを通じて冗長性を提供し、特定の冗長性モデルはストレージ アカウントの構成に依存します。
ローカル冗長ストレージ (LRS) は、ストレージ アカウント内のデータを、選択したプライマリ リージョンにある 1 つ以上の Azure Availability Zones にレプリケートします。 優先する可用性ゾーンを選択するオプションはありませんが、Azure では、負荷分散を向上させるために、ゾーン間で LRS アカウントを移動または拡張する場合があります。 データがゾーン間で分散される保証はありません。 可用性ゾーンの詳細については、「可用性ゾーンとは」を参照してください。

ゾーン冗長ストレージ (ZRS)、geo 冗長ストレージ (GRS)、geo ゾーン冗長ストレージ (GZRS) は、よりいっそうの保護を提供します。 この記事では、これらのオプションについて詳しく説明します。
一時的な障害
一時的な障害は、コンポーネントにおける短い断続的な障害です。 これらはクラウドのような分散環境で頻繁に発生し、運用の通常の範囲であり、 一時的な障害は、短時間の経過後に自分自身を修正します。 アプリケーションで一時的な障害を処理できることは重要です。通常は、影響を受ける要求を再試行します。
クラウドでホストされるすべてのアプリケーションは、クラウドでホストされている API、データベース、およびその他のコンポーネントと通信する際に、Azure の一時的な障害処理のガイダンスに従う必要があります。 詳細については、「一時的な障害を処理するための推奨事項」を参照してください。
Table Storage クライアント ライブラリと SDK には、ネットワーク タイムアウト、一時的なサービス利用不可 (HTTP 503)、調整応答 (HTTP 429)、パーティション サーバーのオーバーロード条件など、一般的な一時的なエラーを自動的に処理する組み込みの再試行ポリシーが含まれています。 アプリケーションでこのような一時的な条件が発生した場合、クライアント ライブラリは指数バックオフ戦略を使用して自動的に操作を再試行します。
Table Storage を使用するときに一時的な障害を効果的に管理するには、次のアクションを実行します。
Table Storage クライアントで適切なタイムアウトを構成して、応答性と一時的な速度低下に対する回復性のバランスを取ります。 通常、Azure Storage クライアント ライブラリの既定のタイムアウトは、ほとんどのシナリオに適しています。
再試行ポリシーの指数バックオフを実装します。特に、アプリケーションで HTTP 503 サーバービジーまたは HTTP 500 操作タイムアウト エラーが発生した場合。 Table Storage では、個々のパーティションに負荷がかかったり、ストレージ アカウントの制限に達しそうになると、要求制限がかかる可能性があります。
大規模なアプリケーションでパーティションを考慮したリトライ ロジックを設計します。 パーティション対応の再試行ロジックは、Table Storage のパーティション分割アーキテクチャを考慮し、複数のパーティションに操作を分散して、個々のパーティション サーバーで調整が発生する可能性を減らす、より高度なアプローチです。
Table Storage アーキテクチャの詳細と、回復性と高スケールのアプリケーションを設計する方法については、 Table Storage のパフォーマンスとスケーラビリティのチェックリストを参照してください。
可用性ゾーンのサポート
可用性ゾーン は、各 Azure リージョン内のデータセンターの物理的に分離されたグループです。 1 つのゾーンで障害が発生した際には、サービスを残りのゾーンのいずれかにフェールオーバーできます。
TABLE Storage は、ZRS 構成でデプロイするときにゾーン冗長です。 ローカル冗長ストレージ (LRS) とは異なり、ZRS は、Azure が複数の可用性ゾーン間でテーブル データを同期的にレプリケートすることを保証します。 この構成により、可用性ゾーン全体が使用できなくなった場合でも、テーブルにアクセスできます。 サービスが書き込みを完了する前に、すべての書き込み操作を複数のゾーンにわたって確認する必要があります。これにより、強力な整合性が保証されます。
ゾーン冗長はストレージ アカウント レベルで有効になり、そのアカウント内のすべての Table Storage リソースに適用されます。 この設定はストレージ アカウント全体に適用されるため、個々のエンティティを異なる冗長レベルに構成することはできません。 可用性ゾーンで障害が発生した場合、Azure Storage は、ユーザーやアプリケーションによる介入を必要とせずに、要求を正常なゾーンに自動的にルーティングします。

リージョンのサポート
ゾーン冗長の Azure Storage アカウントは、可用性ゾーンをサポートする任意のリージョンにデプロイできます。
Requirements
Table Storage の ZRS を有効にするには、Standard 汎用 v2 ストレージ アカウントを使用する必要があります。 Premium ストレージ アカウントでは、Table Storage はサポートされていません。
費用
ゾーン冗長ストレージ (ZRS) を有効にすると、レプリケーションとストレージのオーバーヘッドが増えるため、ローカル冗長ストレージ (LRS) とは異なるレートで課金されます。
価格の詳細については、「 Table Storage の価格」を参照してください。
可用性ゾーンのサポートを設定する
ゾーン冗長ストレージ アカウントとテーブルを作成します。
ストレージ アカウントの作成。 冗長性オプションとして、ZRS、GZRS、または読み取りアクセス地理的冗長ストレージ (RA-GZRS) を選択してください。
レプリケーションの種類を変更します。 既存のストレージ アカウントをゾーン冗長ストレージ (ZRS) に変更する方法および構成のオプションと要件については、「ストレージ アカウントがレプリケートされる方法を変更する」をご覧ください。
ゾーン冗長を無効にします。 同じ冗長性構成変更プロセスを使って、ZRS アカウントをローカル冗長ストレージ (LRS) などの非ゾーン構成に変換します。
通常の運用
このセクションでは、Table Storage アカウントがゾーン冗長用に構成されていて、すべての可用性ゾーンが動作している場合に想定される内容について説明します。
ゾーン間のトラフィック ルーティング: ゾーン冗長ストレージ (ZRS) を使う Azure Storage では、複数の可用性ゾーン内のストレージ クラスター間に要求が自動的に分散されます。 トラフィックの分散はアプリケーションに対して透過的であり、クライアント側の構成は必要ありません。
ゾーン間のデータ レプリケーション: ZRS へのすべての書き込み操作は、そのリージョン内のすべての可用性ゾーンに同期的にレプリケートされます。 データをアップロードまたは変更する場合、すべての可用性ゾーンでデータが正常にレプリケートされるまで、操作は完了とは見なされません。 この同期レプリケーションにより、ゾーン障害時の強力な一貫性とデータ損失がゼロになります。
ゾーンダウン エクスペリエンス
可用性ゾーンが使用できなくなった場合、Table Storage は次の動作で応答することで、フェールオーバー プロセスを自動的に処理します。
検出と応答: Microsoft は自動的にゾーンの障害を検出して復旧プロセスを開始します。 ゾーン冗長ストレージ (ZRS) アカウントに関してお客様が行う必要のある操作はありません。
ゾーンが使用できなくなった場合、Azure により、ドメイン ネーム システム (DNS) の再指定などのネットワークの更新が行われます。
通知: ゾーンがダウンしても、Azure Storage から通知されません。 ただし、 Azure Resource Health を使用して、ストレージ アカウントの正常性を監視できます。 また、Azure Service Health を使用して、ゾーンの障害を含む Azure Storage サービスの全体的な正常性を把握することもできます。
ゾーン レベルの問題の通知を受け取るために、これらのサービスにアラートを設定します。 詳細については、「 Azure portal での Service Health アラートの作成 」および 「Resource Health アラートの作成と構成」を参照してください。
アクティブな要求: 処理中の要求が復旧プロセスの間に破棄される可能性があり、再試行する必要があります。 アプリケーションでは、これらの一時的な中断を処理するための 再試行ロジックを実装 する必要があります。
予想されるデータ損失: 書き込み操作が完了する前に複数のゾーン間でデータが同期的にレプリケートされるため、ゾーンの障害時にデータ損失は発生しません。
予想されるダウンタイム: 自動復旧の間に、トラフィックが正常なゾーンにリダイレクトされるため、若干のダウンタイム (通常は数秒) が発生する可能性があります。 ZRS 用のアプリケーションを設計するときは、エクスポネンシャル バックオフを使用する再試行ポリシーの実装など、一時的な障害処理の手法に従ってください。
- トラフィックの再ルーティング: ゾーンが使用できなくなった場合、Azure はドメイン ネーム システム (DNS) の再ポイントなどのネットワーク更新を実行して、要求が残りの正常な可用性ゾーンに送信されるようにします。 このサービスは、正常なゾーンを使用して完全な機能を維持し、顧客の介入を必要としません。
ゾーンの回復
障害が発生した可用性ゾーンが復旧すると、Azure Storage は、すべての可用性ゾーンで通常の操作を自動的に復元します。 サービスは、停止期間中に発生したすべての操作を同期して、データの整合性を自動的に確保します。
ゾーン障害を検出するためのテスト
ゾーン冗長ストレージ (ZRS) を使うと、Azure Storage によってレプリケーション、トラフィック ルーティング、ゾーンダウンの応答が自動的に管理されます。 この機能は完全に管理されているため、可用性ゾーンの障害プロセスを開始または検証する必要はありません。
マルチリージョン サポート
Azure Blob Storage、Azure Files、Azure Table Storage、Azure Queue Storage などの Azure Storage には、さまざまな要件に合わせて geo 冗長性とフェールオーバーの広範な機能が用意されています。
Important
geo 冗長ストレージ (GRS) は、Azure ペア リージョン内でのみ機能します。 ストレージ アカウントのリージョンがペアになっていない場合は、 代替のマルチリージョン アプローチの使用を検討してください。
ペアになっているリージョン間のレプリケーション
ペア リージョンでは、Azure Storage によって複数の種類の GRS が提供されます。 どの種類の GRS を使っても、セカンダリ リージョン内のデータは常にローカル冗長ストレージ (LRS) を使ってレプリケートされます。 この方法により、セカンダリ リージョン内のハードウェア障害に対する保護が提供されます。
GRS では、プライマリ リージョンで障害が発生した場合に、Azure のペア リージョンへの計画的と計画外のフェールオーバーがサポートされます。 GRS は、プライマリ リージョンからペアのリージョンにデータを非同期的にレプリケートします。
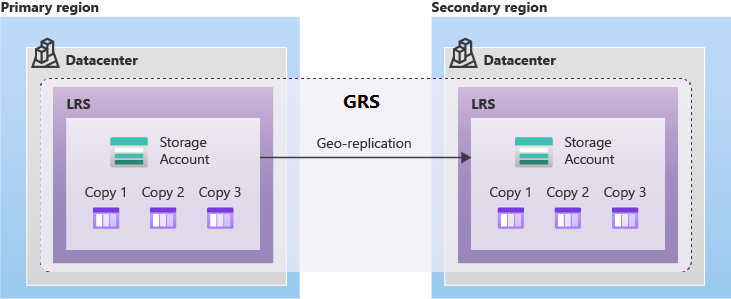
geo ゾーン冗長ストレージ (GZRS) は、プライマリ リージョンの複数の可用性ゾーン内のデータを、ペア リージョンにレプリケートします。



- 読み取りアクセス geo 冗長ストレージ (RA-GRS) と読み取りアクセス geo ゾーン冗長ストレージ (RA-GZRS) は、geo 冗長ストレージ (GRS) と geo ゾーン冗長ストレージ (GZRS) を拡張し、セカンダリ エンドポイントへの読み取りアクセスの利点も追加します。 これらのオプションは、高可用性のビジネス クリティカルなアプリケーション向けに設計されたアプリケーションに最適です。 万一プライマリ エンドポイントで障害が発生した場合、セカンダリ リージョンへの読み取りアクセス用に構成されたアプリケーションは引き続き動作できます。
フェールオーバーの種類
Azure Storage では、さまざまなシナリオに対して 3 種類のフェールオーバーがサポートされています。
カスタマーマネージド計画外フェールオーバー: プライマリ リージョンでリージョン全体のストレージ障害が発生した場合、お客様が復旧を開始する責任があります。
カスタマー マネージドの計画されたフェールオーバー: ソリューションの別の部分でプライマリ リージョンに障害が発生し、ソリューション全体をセカンダリ リージョンに切り替える必要がある場合は、復旧を開始する必要があります。 プライマリ リージョンでストレージが引き続き動作するが、コンプライアンスと監査の要件を確保するために設計されたディザスター リカバリー訓練など、ソリューション全体をセカンダリ リージョンにフェールオーバーする必要がある場合は、計画されたフェールオーバーを使用します。
Microsoft マネージド フェールオーバー: 例外的な状況では、Microsoft がリージョン内のすべての geo 冗長ストレージ (GRS) アカウントのフェールオーバーを開始する場合があります。 ただし、Microsoft が管理するフェールオーバーは最後の手段であり、長期間の停止後にのみ実行される予定です。 Microsoft が管理するフェールオーバーに依存しないでください。
GRS アカウントでは、これらのフェールオーバーの任意の種類を使用できます。 フェールオーバーの種類を事前に使用するために、ストレージ アカウントを事前に構成する必要はありません。
リージョンのサポート
Azure Storage の geo 冗長構成では、セカンダリ リージョンのレプリケーションに Azure ペア リージョンが使われます。 セカンダリ リージョンは、プライマリ リージョンの選択に基づいて自動的に決定され、カスタマイズすることはできません。 Azure のペアになっているリージョンの完全な一覧については、 Azure リージョンの一覧を参照してください。
ストレージ アカウントのリージョンがペアになっていない場合は、 代替のマルチリージョン アプローチの使用を検討してください。
Requirements
geo 冗長ストレージ (GRS) と顧客が自分で開始するフェールオーバーとフェールバックは、汎用 v2 Azure Storage アカウントをサポートするすべての Azure ペア リージョンで使用できます。
考慮事項
複数リージョンの Table Storage を実装する場合は、次の重要な要素を考慮してください。
非同期レプリケーションの待ち時間: セカンダリ リージョンへのデータ レプリケーションは非同期です。つまり、データがプライマリ リージョンに書き込まれるときと、セカンダリ リージョンで使用できるようになるまでの間に時間差があります。 この時間差のため、最近のデータがレプリケートされる前にプライマリ リージョンで障害が発生した場合、データが失われる可能性があります。 データ損失は、回復ポイントの目標 (RPO) によって測定されます。 レプリケーションの時間差は 15 分未満と予想されますが、この時間は推定であり、保証されません。
最終同期時刻プロパティを調べて、ストレージ アカウントで計画外のフェールオーバーが発生した場合に失われる可能性があるデータの量を把握できます。
セカンダリ リージョンのアクセス: geo 冗長ストレージ (GRS) と geo ゾーン冗長ストレージ (GZRS) の構成では、フェールオーバーが発生するまで、セカンダリ リージョンに読み取りアクセスすることはできません。
読み取りアクセス geo 冗長ストレージ (RA-GRS) と読み取りアクセス geo ゾーン冗長ストレージ (RA-GZRS) の構成では、通常の操作中にセカンダリ リージョンに読み取りアクセスできますが、非同期レプリケーションの待ち時間のため、少し古いデータが返される可能性があります。
- 機能の制限: geo 冗長ストレージ (GRS) またはカスタマーマネージド フェールオーバーを使うと、Azure Storage の一部の機能がサポートされないか、制限されます。 geo 冗長を実装する前に、機能の互換性を確認してください。
費用
複数リージョンの Azure Storage アカウント構成では、リージョン間のレプリケーションとセカンダリ リージョンでのストレージに対して追加のコストが発生します。 Azure リージョン間のデータ転送は、標準のリージョン間帯域幅レートに基づいて課金されます。
価格の詳細については、「 Table Storage の価格」を参照してください。
複数リージョンのサポートを構成する
- 新しい geo 冗長ストレージ (GRS) アカウントを作成します。 GRS アカウントの作成については、「ストレージ アカウントの作成」を参照し、アカウントの作成時に、GRS、読み取りアクセス geo 冗長ストレージ (RA-GRS)、geo ゾーン冗長ストレージ (GZRS)、読み取りアクセス geo ゾーン冗長ストレージ (RA-GZRS) のいずれかを選びます。
既存のストレージ アカウントで geo 冗長を有効にします。 既存のストレージ アカウントを geo 冗長ストレージ (GRS) に変換するには、「 ストレージ アカウントのレプリケート方法を変更する」を参照してください。
Warnung
アカウントが geo 冗長として再構成された後、新しいプライマリ リージョンの既存データが新しいセカンダリ リージョンに完全にコピーされるまで、かなりの時間がかかる場合があります。
大きなデータ損失を防ぐには、計画外フェールオーバーを始める前に、最終同期時刻プロパティの値を確認します。 データ損失の可能性を評価するには、最終同期時刻と、そのデータが新しいプライマリ リージョンに最後に書き込まれた時刻を比べます。
geo 冗長性を無効にします。 同じ冗長構成変更プロセスを使って、GRS アカウントをローカル冗長ストレージ (LRS) やゾーン冗長ストレージ (ZRS) などの単一リージョン構成に戻します。
通常の運用
このセクションでは、ストレージ アカウントが geo 冗長用に構成されていて、すべてのリージョンが運用されている場合に想定される内容について説明します。
リージョン間のトラフィック ルーティング: Azure Storage では、すべての書き込み操作とほとんどの読み取り操作がプライマリ リージョンに転送されるアクティブ/パッシブ アプローチが使われます。
読み取りアクセス geo 冗長ストレージ (RA-GRS) と読み取りアクセス geo ゾーン冗長ストレージ (RA-GZRS) 構成の場合、アプリケーションは必要に応じてセカンダリ エンドポイントにアクセスしてセカンダリ リージョンから読み取ることができます。 この方法ではアプリケーションを明示的に構成する必要があり、自動的には行われません。 また、非同期レプリケーションのラグにより、セカンダリ リージョンのデータが少し古くなっている可能性があります。
リージョン間のデータ レプリケーション: 書き込み操作は、次の構成済みの冗長性の種類を使って、最初にプライマリ リージョンにコミットされます。
- geo 冗長ストレージ (GRS) と RA-GRS の場合はローカル冗長ストレージ (LRS)
- geo ゾーン冗長ストレージ (GZRS) と RA-GZRS の場合はゾーン冗長ストレージ (ZRS)
プライマリ リージョンで正常に完了した後、データは LRS を使って格納されるセカンダリ リージョンに非同期的にレプリケートされます。
リージョン間レプリケーションの非同期的な性質は、通常、データがプライマリ リージョンに書き込まれてからセカンダリ リージョンで使用できるようになるまでに遅延時間があることを意味します。 レプリケーション時間は、最終同期時刻プロパティを使って監視できます。
リージョン ダウン エクスペリエンス
このセクションでは、ストレージ アカウントが geo 冗長用に構成されていて、プライマリ リージョンで障害が発生した場合に想定される内容について説明します。
カスタマーマネージド フェールオーバー (計画外): プライマリ リージョンのストレージが使用できない場合は、計画外フェールオーバーを使います。
検出と応答: 万が一、プライマリ リージョンでストレージ アカウントが使用できない場合は、カスタマー マネージドの計画外フェールオーバーの開始を検討できます。 この決定を行うには、次の要因を考慮してください。
プライマリ リージョンのストレージ アカウントへのアクセスに関する問題が Azure Resource Health で示されるかどうか
別のリージョンへのフェールオーバーを実行するよう Microsoft が推奨するかどうか
Warnung
計画外のフェールオーバーでは、 データが失われる可能性があります。 カスタマーマネージド フェールオーバーを始める前に、サービスの復元によってデータ損失のリスクが正当化されるかどうかを判断します。
通知: リージョンがダウンしても、Azure Storage から通知されません。 ただし、 Azure Resource Health を使用して、ストレージ アカウントの正常性を監視できます。 また、Azure Service Health を使用して、リージョンの障害を含む Azure Storage サービスの全体的な正常性を把握することもできます。
リージョン レベルの問題の通知を受け取るために、これらのサービスにアラートを設定します。 詳細については、「 Azure portal での Service Health アラートの作成 」および 「Resource Health アラートの作成と構成」を参照してください。
アクティブな要求: フェールオーバー プロセス中に、プライマリとセカンダリの両方のストレージ アカウント エンドポイントが読み取りと書き込みの両方で一時的に使用できなくなります。 アクティブな要求はすべて削除される可能性があり、クライアント アプリケーションはフェールオーバーの完了後に再試行する必要があります。
予想されるデータ損失: 非同期レプリケーションの遅延により、最近の書き込みがレプリケートされない可能性があるため、計画外フェールオーバーでは一般にデータ損失が発生します。 最終同期時刻プロパティを調べて、計画外フェールオーバーの間に失われる可能性があるデータの量を把握できます。 予想されるデータ損失は、多くの場合、目標復旧ポイント (RPO) と呼ばれます。 通常、RPO は 15 分未満であると予想できますが、その時間は保証されません。
予想されるダウンタイム: 予想されるダウンタイムの量は、多くの場合、目標復旧時間 (RTO) と呼ばれます。 顧客が管理するフェールオーバーは、通常、アカウントのサイズと複雑さに応じて 60 分以内に完了します。
トラフィックの再ルーティング: フェールオーバーが完了すると、アプリケーションを再構成する必要がないように、Azure によってストレージ アカウント エンドポイントが自動的に更新されます。 アプリケーションがドメイン ネーム システム (DNS) のエントリをキャッシュに保持している場合、アプリケーションで新しいプライマリ リージョンにトラフィックを確実に送信するため、キャッシュのクリアが必要になる場合があります。
フェールオーバー後の構成: 計画外フェールオーバーが完了した後、フェールオーバー先のリージョンのストレージ アカウントではローカル冗長ストレージ (LRS) 層が使われます。 それを再び geo レプリケートする必要がある場合は、geo 冗長ストレージ (GRS) をもう一度有効にして、データが新しいセカンダリ リージョンにレプリケートされるのを待つ必要があります。
カスタマーマネージド フェールオーバーを始める方法について詳しくは、「カスタマーマネージド (計画外) フェールオーバーのしくみ」と「ストレージ アカウントのフェールオーバーを開始する」をご覧ください。
カスタマーマネージド フェールオーバー (計画的): プライマリ リージョンのストレージは動作しているものの、別の理由でソリューション全体をセカンダリ リージョンにフェールオーバーする必要がある場合は、計画フェールオーバーを使います。 たとえば、別の Azure サービスで問題が発生している可能性があり、ソリューション全体にセカンダリ リージョンを使用するように切り替える必要があります。 または、計画されたフェールオーバーを使用して、コンプライアンスと監査の目的でディザスター リカバリー (DR) 訓練を実施することもできます。
検出と応答: フェールオーバーを決定する責任があります。 通常、ストレージ アカウントが正常であっても、リージョン間でフェールオーバーする必要がある場合は、この決定を行います。 たとえば、プライマリ リージョンで復旧できない別のアプリケーション コンポーネントが大幅に停止した場合にフェールオーバーをトリガーできます。
通知: リージョンがダウンしても、Azure Storage から通知されません。 ただし、 Azure Resource Health を使用して、ストレージ アカウントの正常性を監視できます。 また、Azure Service Health を使用して、リージョンの障害を含む Azure Storage サービスの全体的な正常性を把握することもできます。
リージョン レベルの問題の通知を受け取るために、これらのサービスにアラートを設定します。 詳細については、「 Azure portal での Service Health アラートの作成 」および 「Resource Health アラートの作成と構成」を参照してください。
アクティブな要求: フェールオーバー プロセス中に、プライマリとセカンダリの両方のストレージ アカウント エンドポイントが読み取りと書き込みの両方で一時的に使用できなくなります。 アクティブな要求はすべて削除される可能性があり、クライアント アプリケーションはフェールオーバーの完了後に再試行する必要があります。
予想されるデータ損失: フェールオーバー プロセスは、すべてのデータが同期された後にのみ完了し、RPO が 0 になるため、データ損失は発生しません。
予想されるダウンタイム: 通常、フェールオーバーは 60 分以内に完了します。つまり、アカウントのサイズと複雑さに応じて、予想される RTO は 60 分です。 フェールオーバー プロセス中に、プライマリとセカンダリの両方のストレージ アカウント エンドポイントが読み取りと書き込みの両方で一時的に使用できなくなります。
トラフィックの再ルーティング: フェールオーバーが完了すると、アプリケーションを再構成する必要がないように、Azure によってストレージ アカウント エンドポイントが自動的に更新されます。 アプリケーションが DNS のエントリをキャッシュに保持している場合、アプリケーションで新しいプライマリ リージョンにトラフィックを確実に送信するため、キャッシュのクリアが必要になる場合があります。
フェールオーバー後の構成: 計画されたフェールオーバーが完了した後も、移行先リージョンのストレージ アカウントは引き続き geo レプリケートされ、GRS レベルに残ります。
カスタマーマネージド フェールオーバーを始める方法について詳しくは、カスタマーマネージド (計画的) フェールオーバーのしくみに関する記事と「ストレージ アカウントのフェールオーバーを開始する」をご覧ください。
Microsoft マネージド フェールオーバー: プライマリ リージョンが永続的に回復不能であると Microsoft が判断する重大な災害が発生したまれな場合は、セカンダリ リージョンへの自動フェールオーバーが開始される可能性があります。 Microsoft はプロセス全体を処理し、顧客のアクションは必要ありません。 フェールオーバーが発生するまでの経過時間は、障害の重大度と状況の評価に必要な時間によって異なります。
通知: リージョンがダウンしても、Azure Storage から通知されません。 ただし、 Azure Resource Health を使用して、ストレージ アカウントの正常性を監視できます。 また、Azure Service Health を使用して、リージョンの障害を含む Azure Storage サービスの全体的な正常性を把握することもできます。
リージョン レベルの問題の通知を受け取るために、これらのサービスにアラートを設定します。 詳細については、「 Azure portal での Service Health アラートの作成 」および 「Resource Health アラートの作成と構成」を参照してください。
Important
カスタマー マネージド フェールオーバー オプションを使用して、DR プランを開発、テスト、実装します。 Microsoft マネージド フェールオーバーに頼らないでください。これが使われる可能性があるのは、極端な状況のみです。 Microsoft マネージド フェールオーバーは、リージョン全体に対して開始される可能性があります。 個々のストレージ アカウント、サブスクリプション、または顧客に対して開始することはできません。 フェールオーバーは、Azure サービスごとに異なる時間に発生する可能性があります。 カスタマーマネージド フェールオーバーを使うことをお勧めします。
リージョンの回復
フェールバック プロセスは、Microsoft マネージド フェールオーバーとカスタマーマネージド フェールオーバーのシナリオで大きく異なります。
カスタマーマネージド フェールオーバー (計画外): 計画外フェールオーバーの後では、ストレージ アカウントはローカル冗長ストレージ (LRS) で構成されます。 フェールバックするには、geo 冗長ストレージ (GRS) の関係を確立し直して、データがレプリケートされるのを待つ必要があります。
カスタマーマネージド フェールオーバー (計画的): 計画フェールオーバーの後では、ストレージ アカウントは引き続き geo レプリケートされます。 別のカスタマーマネージド フェールオーバーを始めて、元のプライマリ リージョンにフェールバックできます。 同じフェールオーバーに関する考慮事項が適用されます。
Microsoft マネージド フェールオーバー: Microsoft がフェールオーバーを開始するのは、おそらくプライマリ リージョンで重大な災害が発生した場合であり、プライマリ リージョンを復旧できない可能性があります。 タイムラインや復旧計画は、リージョンの災害と復旧作業の程度によって異なります。 詳細については、Azure Service Health 通信を監視する必要があります。
リージョンの障害のテスト
リージョンの障害をシミュレートして、ディザスター リカバリー手順をテストできます。
計画フェールオーバーのテスト: geo 冗長ストレージ (GRS) アカウントの場合は、メンテナンス期間中に計画フェールオーバー操作を実行して、フェールオーバーとフェールバックの完全なプロセスをテストできます。 計画フェールオーバーではデータの損失は発生しませんが、フェールオーバーとフェールバックの両方でダウンタイムが発生します。
セカンダリ エンドポイントのテスト: 読み取りアクセス geo 冗長ストレージ (RA-GRS) と読み取りアクセス geo ゾーン冗長ストレージ (RA-GZRS) 構成の場合は、セカンダリ エンドポイントに対する読み取り操作を定期的にテストして、アプリケーションがセカンダリ リージョンからデータを正常に読み取れることを確認します。
代替のマルチリージョン アプローチ
次の理由により、Azure Storage のリージョン間フェールオーバー機能が不適切な場合があります。
ストレージ アカウントがペアになっていないリージョンにあります。
ビジネスアップタイムの目標は、組み込みのフェールオーバー オプションによって提供される復旧時間やデータ損失によって満たされません。
プライマリ リージョンのペアではないリージョンにフェールオーバーする必要があります。
Azure リージョン間でアクティブ/アクティブ構成が必要です。
このセクションでは、考慮すべきいくつかのアプローチの概要について説明します。 Azure Storage のマルチリージョン デプロイ トポロジの包括的な概要については、この記事の範囲外です。
注
Table Storage を使用するように構築されたアプリケーションの場合は、 Azure Cosmos DB for Table の使用を検討してください。 Azure Cosmos DB for Table では、ペアになっていないリージョンのサポートなど、高度なマルチリージョン要件がサポートされています。 また、Table Storage 用に構築されたアプリケーションとの互換性を確保するように設計されています。
リージョンごとに個別のストレージ アカウントを使って、複数のリージョンに Azure Storage をデプロイできます。 この方法では、リージョンを柔軟に選択し、ペアリングされていないリージョンを使い、レプリケーションのタイミングとデータの整合性をより細かく制御することができます。 リージョンをまたいで複数のストレージ アカウントを実装する場合は、リージョン間のデータ レプリケーションを構成し、負荷分散とフェールオーバーのポリシーを実装して、リージョン間のデータの整合性を確保する必要があります。
Table Storage の場合、複数アカウントのアプローチでは、データ分散を管理し、競合解決を含むリージョン間のテーブル間の同期を処理し、カスタム フェールオーバー ロジックを実装する必要があります。
Backups
Table Storage には、ポイントインタイム リストア (PITR) などの従来のバックアップ機能は用意されていません。 ただし、テーブル データのカスタム バックアップ戦略を実装できます。 ほとんどのソリューションでは、バックアップのみに依存しないでください。 代わりに、このガイドで説明されている他の機能を使用して、回復性の要件をサポートします。 ただし、バックアップでは、他の方法では行わないリスクから保護されます。 詳細については、「冗長、レプリケーション、バックアップ」をご覧ください。
組み込みのバックアップ機能が必要な場合は、定期的バックアップと継続的バックアップの両方をサポートする Azure Cosmos DB for Table への移行を検討してください。 詳細については、「Azure Cosmos DB でのオンライン バックアップとオンデマンドのデータ復元」をご覧ください。
Table Storage からのデータバックアップが必要なシナリオでは、次の方法を検討してください。
Azure Data Factory を使用してエクスポートします。 Table Storage 用の Azure Data Factory コネクタを使用して、エンティティを別の場所にエクスポートします。 たとえば、各エンティティを、Azure Blob Storage に格納されている JSON ファイルにバックアップできます。
アプリケーション レベルのバックアップを実行します。 アプリケーション内にカスタム バックアップ ロジックを実装して、重要なテーブル エンティティを Azure SQL Database や Azure Cosmos DB などの他のストレージ サービスにエクスポートして、より堅牢なバックアップと復元の機能を実現します。
Table Storage のバックアップ戦略を設計するときは、データのパーティション分割された性質を考慮し、複数のパーティションを並列で処理することで、バックアップ プロセスで大きなテーブルを効率的に処理できることを確認します。
サービス水準合意書
Azure Storage のサービス レベル アグリーメント (SLA) では、サービスの予想される可用性と、その可用性の期待を達成するために満たす必要がある条件が記述されています。 適用される可用性 SLA は、使用するストレージ層とレプリケーションの種類によって異なります。 詳しくは、「オンライン サービスのサービス レベル アグリーメント (SLA)」をご覧ください。