ジョブは、データ レイク層のデータに対して KQL (Kusto クエリ言語) クエリを実行して結果を分析層に昇格させる、1 回限りまたは繰り返しスケジュールされたタスクです。 分析レベルに入ったら、高度なハンティング KQL エディターを使用してデータのクエリを実行します。 分析レベルへのデータの昇格には、次の利点があります。
分析層の現在のデータと履歴データを組み合わせて、データに対して高度な分析モデルと機械学習モデルを実行します。
分析レベルでクエリを実行することで、クエリ コストを削減します。
分析レベルで、複数のワークスペースのデータを 1 つのワークスペースに結合します。
分析レベルで Microsoft Entra ID、Microsoft 365、および Microsoft Resource Graph のデータを組み合わせて、データ ソース間で高度な分析を実行します。
注
分析レベルのストレージでは、Data Lake レベルよりも高い課金レートが発生します。 コストを削減するには、さらに分析する必要があるデータのみを昇格させます。 クエリで KQL を使用して、必要な列のみを射影し、データをフィルター処理して分析レベルに昇格するデータの量を減らします。
分析レベルにデータを昇格させる場合は、高度なハンティング クエリ エディターでターゲット ワークスペースが表示されていることを確認します。 高度なハンティング クエリ エディターでは、接続されているワークスペースに対してのみクエリを実行できます。 高度な追求では、接続されていないワークスペースまたは既定のワークスペースにレベル上げされたデータは表示されません。 接続されているワークスペースの詳細については、「ワークスペースの 接続」を参照してください。 データを新しいテーブルに昇格させたり、分析レベルの既存のテーブルに結果を追加したりできます。 新しいテーブルを作成すると、テーブル名の末尾に _KQL_CL が付き、テーブルが KQL ジョブによって作成されたことを示します。
[前提条件]
Microsoft Sentinel データ レイクで KQL ジョブを作成および管理するには、次の前提条件が必要です。
データ レイクにオンボードする
Microsoft Sentinel データ レイクで KQL ジョブを作成および管理するには、まずデータ レイクにオンボードする必要があります。 Data Lake へのオンボードの詳細については、「 Microsoft Sentinel データ レイクへのオンボード (プレビュー)」を参照してください。
権限
Microsoft Entra ID ロールは、データ レイク内のすべてのワークスペースに広範なアクセスを提供します。 すべてのワークスペースでテーブルを読み取り、分析層に書き込み、KQL クエリを使用してジョブをスケジュールするには、サポートされている Microsoft Entra ID ロールのいずれかが必要です。 ロールとアクセス許可の詳細については、「 Microsoft Sentinel Data Lake のロールとアクセス許可」を参照してください。
分析レベルで新しいカスタム テーブルを作成するには、Data Lake マネージド ID に Log Analytics ワークスペースの Log Analytics 共同作成者 ロールを割り当てる必要があります。
ロールを割り当てるには、次の手順に従います。
- Azure portal で、ロールを割り当てる Log Analytics ワークスペースに移動します。
- 左側のナビゲーション ペインで [アクセス制御 (IAM)] を選択します。
- [ロールの割り当ての追加] を選択します。
- [ロール] テーブルで 、[*Log Analytics 共同作成者] を選択し、[次へ] を選択します。
- [ マネージド ID] を選択し、[ メンバーの選択] を選択します。
- データレイクのマネージドアイデンティティは、システムが割り当てた `
msg-resources-<guid>` という名前のマネージドアイデンティティです。マネージドアイデンティティを選択し、次に `選択` を選択してください。 - 「Review and assign」を選択します。
マネージド ID へのロールの割り当ての詳細については、 Azure portal を使用した Azure ロールの割り当てに関するページを参照してください。
ジョブの作成
データ レイク層のデータに対して KQL クエリを実行し、結果を分析層に昇格させるジョブを作成できます。 スケジュールに従って実行するジョブまたは 1 回限り実行するジョブを作成できます。 ジョブを作成するときに、結果の宛先ワークスペースとテーブルを指定します。 結果は、新しいテーブルに書き込んだり、分析レベルの既存のテーブルに追加したりできます。
ジョブの作成と管理は、ナビゲーション パネルの [データ レイク探索] の [ジョブ管理] ページから行うことができます。 このページを使用して、新しいジョブの作成、状態と詳細の表示、ジョブの実行、編集、削除、または無効化を行います。 詳細については、「 KQL ジョブの管理」を参照してください。
ジョブ作成プロセスは、KQL クエリ エディターまたはジョブ管理ページから開始できます。
- KQL クエリ エディターからジョブを作成するには、クエリ エディターの右上隅にある [ ジョブの作成 ] ボタンを選択します。
![KQL クエリ エディターの [ジョブの作成] ボタンを示すスクリーンショット。](media/kql-jobs/kql-queries-create-job.png)
- ジョブ管理ページからジョブを作成するには、 Microsoft Sentinel>Data lake exploration>Jobs を選択し、[ 新しいジョブの作成 ] ボタンを選択します。
![ジョブ管理ページの [ジョブの作成] ボタンを示すスクリーンショット。](media/kql-jobs/jobs-page-create-job.png)
- KQL クエリ エディターからジョブを作成するには、クエリ エディターの右上隅にある [ ジョブの作成 ] ボタンを選択します。
ジョブ名を入力します。 ジョブ名は、テナントに対して一意である必要があります。 ジョブ名には、最大 256 文字を含めることができます。 ジョブ名に
#を使用することはできません。ジョブのコンテキストと目的を指定するジョブの 説明 を入力します。
[ ワークスペースの選択 ] ドロップダウンから、結果を書き込む分析レベルのターゲット ワークスペースを選択します。
宛先テーブルを選択します。
新しいテーブルを作成するには、[ 新しいテーブルの作成 ] を選択し、テーブル名を入力します。 KQL ジョブによって作成されたテーブルには、テーブル名 _KQL_CL サフィックスが追加されます。
既存のテーブルに追加するには、[ 既存のテーブルに追加] を選択し、ドロップダウン リストからテーブル名を選択します。 既存のテーブルに追加する場合、クエリ結果は既存のテーブルのスキーマと一致する必要があります。
[次へ] を選択します。
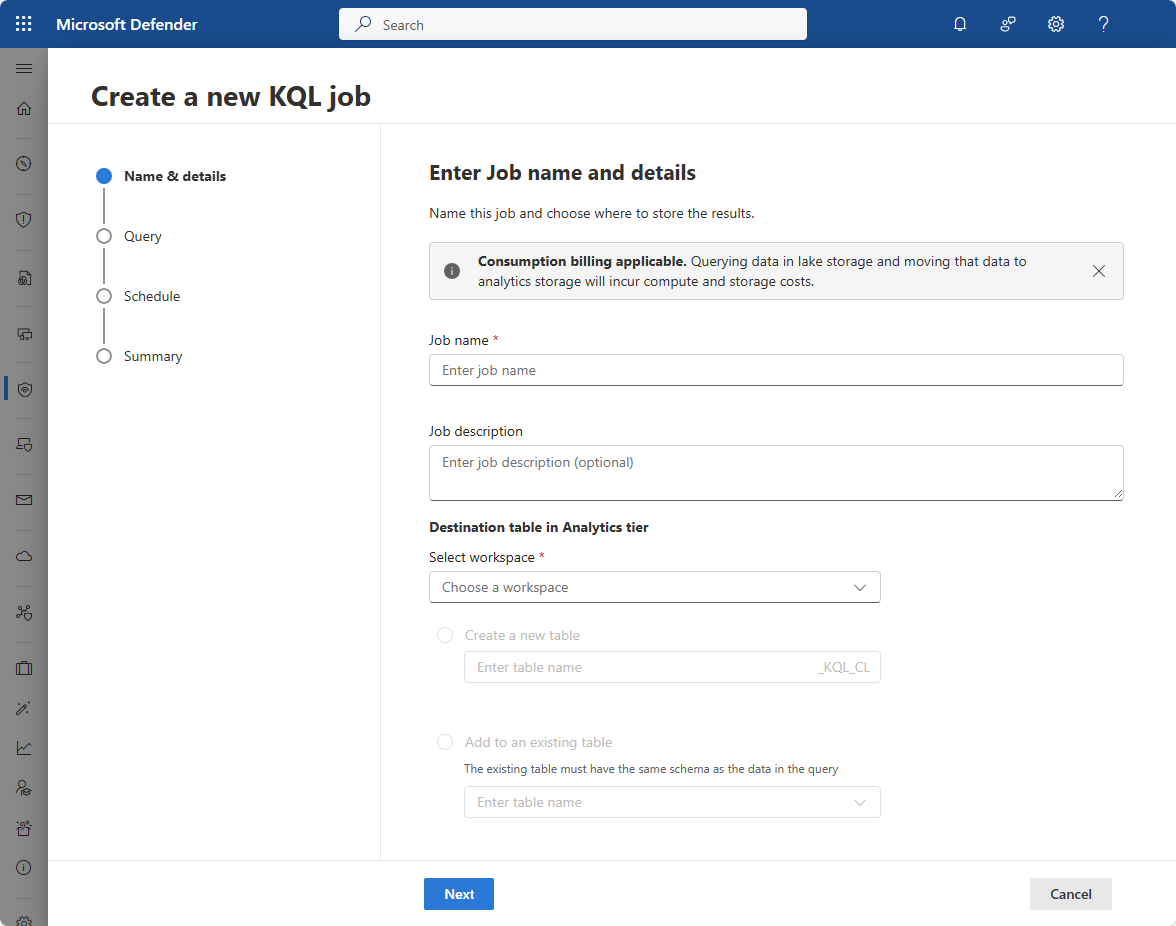
[クエリの確認] パネルでクエリを確認または記述します。 日付範囲がクエリで指定されていない場合は、時刻ピッカーがジョブに必要な時間範囲に設定されていることを確認します。
[ 選択した ワークスペース] ドロップダウンから、クエリを実行するワークスペースを選択します。
注
クエリは、対象のテーブル スキーマと一致するスキーマを持つテーブルを返す必要があります。 クエリが正しいスキーマを持つテーブルを返さない場合、ジョブの実行時に失敗します。
[次へ] を選択します。
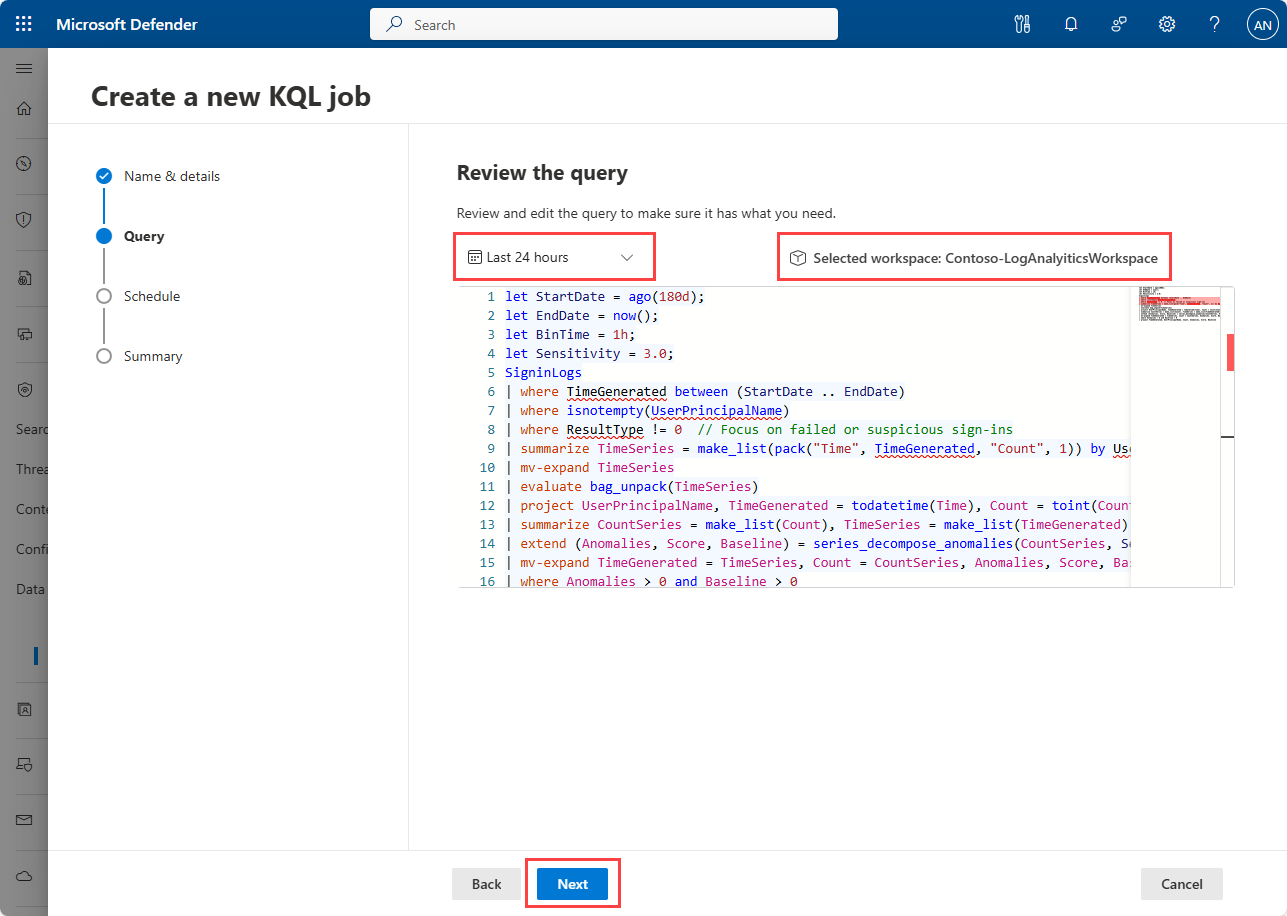
[ クエリ ジョブのスケジュール ] パネルで、ジョブを 1 回実行するかスケジュールに従って実行するかを選択します。 [1 回限り] を選択すると、ジョブ定義が完了するとすぐにジョブが実行されます。 [スケジュール] を選択した場合は、ジョブの実行日時を指定するか、定期的なスケジュールでジョブを実行できます。
1 回限りまたはスケジュールされたジョブを選択します。
注
1 回限りのジョブを編集すると、すぐに実行がトリガーされます。
[スケジュール] を選択した場合は、次の詳細を入力します。
- [ 実行間隔 ] ドロップダウンから実行頻度を選択します。 [ 日単位]、[ 週単位]、または [月単位] を選択します。
- [ Start running]\(実行の開始\) で、[ Start running date]\(実行の開始\) と [Start running time]\(実行の開始\) を入力します。 ジョブの開始時刻は、ジョブの作成後少なくとも 30 分後である必要があります。 ジョブは、[すべての実行] ドロップダウンで選択した頻度に従って、この日付と時刻から 実行 されます。
- ジョブ スケジュールの 終了日時 を指定するには、[終了日の設定] チェック ボックスをオンにします。 終了日のチェック ボックスをオンにしない場合、ジョブは無効または削除するまで実行頻度に従って実行されます。
[ 次へ ] を選択してジョブの詳細を確認します。

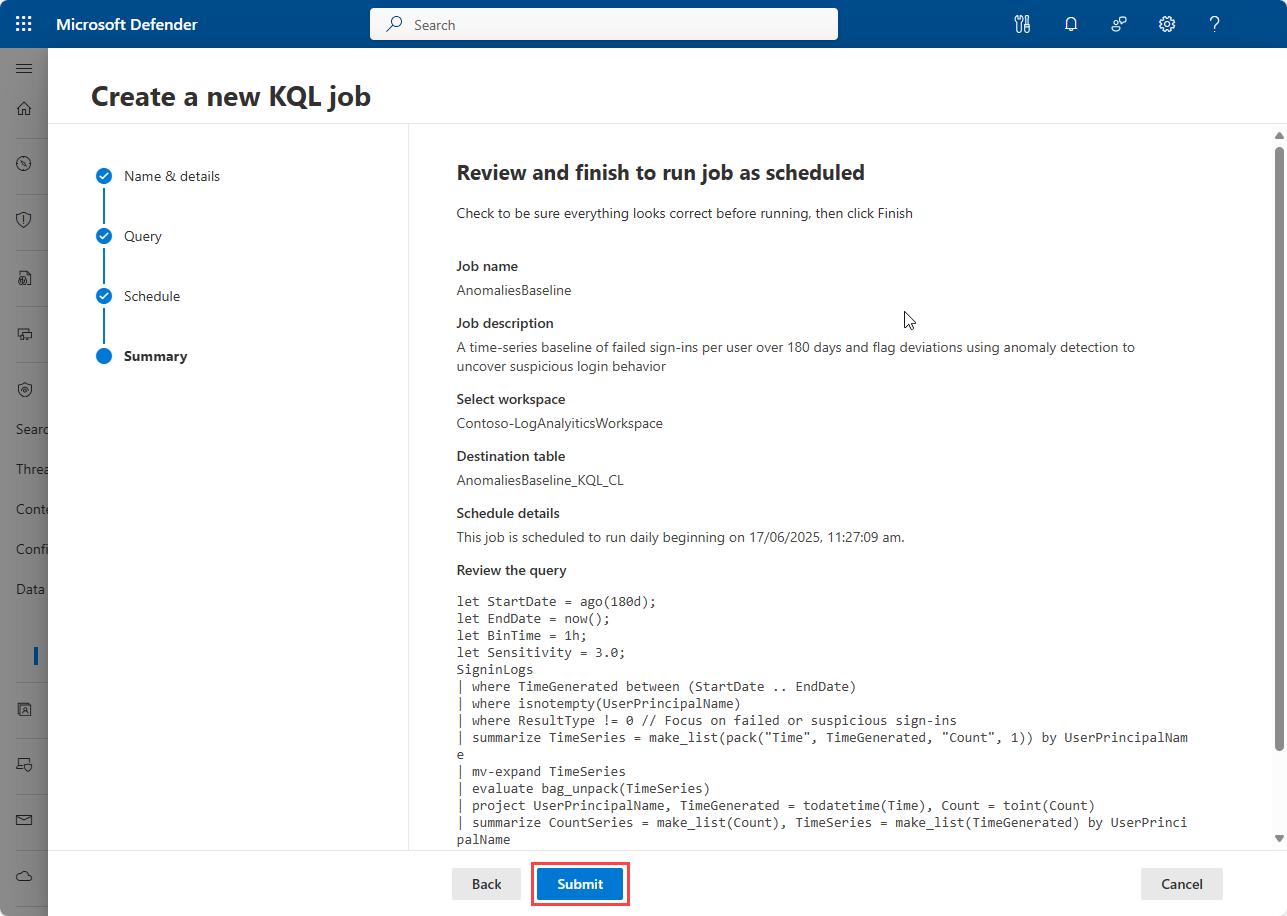
ジョブの詳細を確認し、[ 送信] を選択してジョブを作成します。 ジョブが 1 回限りのジョブの場合は、[ 送信] を選択した後に実行されます。 ジョブがスケジュールされている場合は、[ジョブ ] ページの ジョブの一覧に追加され、開始データと時刻に従って実行されます。
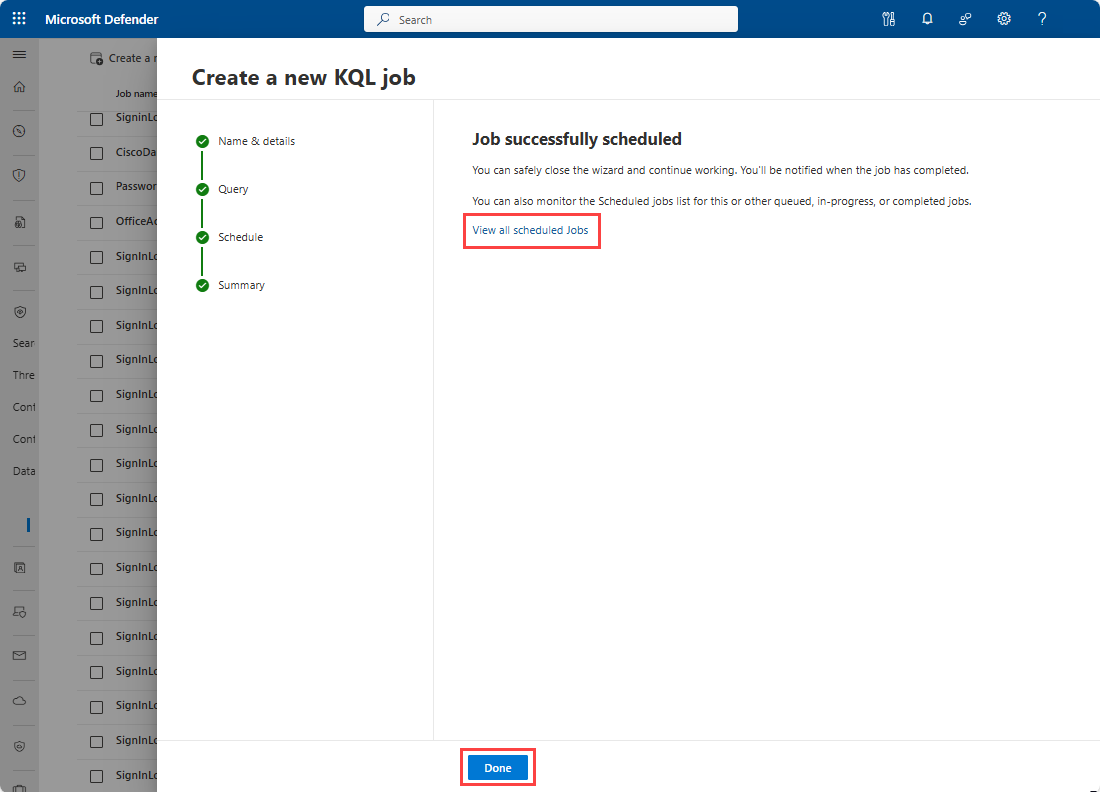
ジョブがスケジュールされ、次のページが表示されます。 リンクを選択すると、ジョブを表示できます。
![KQL クエリ エディターの [ジョブの作成] ボタンを示すスクリーンショット。](media/kql-jobs/kql-queries-create-job.png#lightbox)
![ジョブ管理ページの [ジョブの作成] ボタンを示すスクリーンショット。](media/kql-jobs/jobs-page-create-job.png#lightbox)





考慮事項と制限事項
Microsoft Sentinel データ レイクでジョブを作成する場合は、次の制限事項とベスト プラクティスを考慮してください。
仕事
- ジョブ名は、テナントに対して一意である必要があります。
- ジョブ名は最大 256 文字です。
- ジョブ名に
#を含めることはできません。 - ジョブの開始時刻は、ジョブの作成または編集後、少なくとも 30 分後である必要があります。
- パブリック プレビュー中、KQL ジョブのスコープは 1 つのワークスペースに制限されます。
列名
次の標準列はエクスポートではサポートされていません。 これらの列は、インジェスト中にターゲット層で上書きされます。
テナント識別子
_TimeReceived
タイプ
ソースシステム
_ResourceId(リソース識別子)
_SubscriptionId(サブスクリプションID)
_ItemId
_請求額サイズ
_IsBillable // 請求可能かどうかを示す
_WorkspaceId
TimeGeneratedは、その 2 日より古い場合は上書きされます。 元のイベント時間を保持するには、ソースタイムスタンプを別の列に書き込むことをお勧めします。
サービスの制限については、 Microsoft Sentinel Data Lake (プレビュー) サービスの制限に関する説明を参照してください。
注
ジョブのクエリが1時間の制限を超えると、部分的な結果が優先扱いされる可能性があります。
KQL ジョブのサービスパラメーターおよび制限
次の表に、Microsoft Sentinel データ レイク (プレビュー) の KQL ジョブのサービス パラメーターと制限を示します。
| カテゴリ | パラメーター/制限 |
|---|---|
| テナントごとの同時ジョブ実行 | 3 |
| ジョブ クエリの実行タイムアウト | 1 時間 |
| テナントあたりのジョブ数 (有効なジョブ) | 100 |
| ジョブあたりの出力テーブルの数 | 1 |
| 検索範囲 | 単一ワークスペース |
| クエリの時間範囲 | 最大 12 年 |
トラブルシューティングのヒントとエラー メッセージについては、 Microsoft Sentinel データ レイク (プレビュー) の KQL クエリのトラブルシューティングを参照してください。