Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Bewertungsprofile werden verwendet, um die Rangfolge von übereinstimmenden Dokumenten basierend auf Kriterien zu erhöhen. In diesem Artikel erfahren Sie, wie Sie ein Bewertungsprofil angeben und zuweisen, das eine Suchbewertung basierend auf von Ihnen angegebenen Parametern erhöht. Sie können Bewertungsprofile erstellen basierend auf:
Gewichtete Textfelder, wobei das Boosting auf einer Übereinstimmung basiert, die in einem vordefinierten Feld gefunden wurde. Beispielsweise werden Übereinstimmungen, die in einem Feld "Betreff" gefunden wurden, als relevanter betrachtet als dieselbe Übereinstimmung, die in einem Feld "Beschreibung" gefunden wurde.
Funktionen für numerische Felder, einschließlich Datumsangaben und geografischen Koordinaten. Funktionen für numerische Inhalte unterstützen die Erhöhung der Entfernung (gilt für geografische Koordinaten), Aktualität (gilt für Datums-/Uhrzeitfelder), Bereich und Größe.
Funktionen für Zeichenfolgensammlungen (Tags). Eine Tags-Funktion erhöht die Suchbewertung eines Dokuments, wenn ein Element in der Auflistung von der Abfrage abgeglichen wird.
Sie können einem Index ein Bewertungsprofil hinzufügen, indem Sie die JSON-Definition im Azure-Portal bearbeiten oder programmgesteuert über APIs wie Create or Update Index REST oder gleichwertige Indexupdate-APIs in einem beliebigen Azure SDK bearbeiten. Es gibt keine Indexneuerstellungsanforderungen, sodass Sie ein Bewertungsprofil ohne Auswirkungen auf indizierte Dokumente hinzufügen, ändern oder löschen können.
Prerequisites
- Ein Suchindex mit Text- oder numerischen Feldern (nicht vektorisiert).
Regeln für Bewertungsprofile
Sie können Bewertungsprofile in der Schlüsselwortsuche, der Vektorsuche, der Hybridsuche und der semantischen Umrankung verwenden.) Bewertungsprofile gelten jedoch nur für Nichtvektorfelder. Stellen Sie daher sicher, dass Ihr Index Text- oder numerische Felder enthält, die höher oder gewichtet werden können.
Sie können in einem Index bis zu 100 Bewertungsprofile verwenden (siehe Diensteinschränkungen), aber Sie können in einer Abfrage jeweils nur ein Profil angeben.
Sie können semantische Rangfolger mit Bewertungsprofilen verwenden und nach der semantischen Rangfolge ein Bewertungsprofil anwenden. Andernfalls ist die semantische Rangfolge der letzte Schritt, wenn mehrere Bewertungs- oder Relevanzfeatures ausgeführt werden. Dies wird unter Funktionsweise der Suchbewertung in der Azure KI-Suche veranschaulicht.
Zusätzliche Regeln gelten speziell für Funktionen.
Note
Sind Sie noch nicht mit Relevanzkonzepten vertraut? Besuchen Sie Relevanz und Bewertung in Azure KI-Suche für den Hintergrund. Sie können sich dieses Video-Segment auf YouTube ansehen, um Profile mit Ergebnissen über BM25-Rankings zu bewerten.
Bewertungsprofildefinition
Ein Bewertungsprofil wird in einem Indexschema definiert. Sie besteht aus gewichteten Feldern, Funktionen und Parametern.
Die folgende Definition zeigt ein einfaches Profil namens „geo“. Dieses Beispiel gewichtet Ergebnisse höher, die den Suchbegriff im Feld „hotelName“ enthalten. Darüber hinaus verwendet es die distance-Funktion, um Ergebnisse zu bevorzugen, die sich im Umkreis von zehn Kilometern um den aktuellen Standort befinden. Wenn jemand nach dem Begriff "inn" sucht und "inn" Teil des Hotelnamens ist, werden Dokumente, die Hotels mit "inn" innerhalb eines Radius von 10 Kilometern des aktuellen Standorts enthalten, in den Suchergebnissen höher angezeigt.
"scoringProfiles": [
{
"name":"geo",
"text": {
"weights": {
"hotelName": 5
}
},
"functions": [
{
"type": "distance",
"boost": 5,
"fieldName": "___location",
"interpolation": "logarithmic",
"distance": {
"referencePointParameter": "currentLocation",
"boostingDistance": 10
}
}
]
}
]
Um dieses Bewertungsprofil zu verwenden, wird Ihre Abfrage so formuliert, dass sie den Parameter in der Anforderung angibt scoringProfile . Wenn Sie die REST-API verwenden, werden Abfragen über GET- und POST-Anforderungen angegeben. Im folgenden Beispiel hat „currentLocation“ als Trennzeichen einen einzelnen Gedankenstrich (-). Gefolgt von Längen- und Breitengradkoordinaten, wobei Längengrad ein negativer Wert ist.
POST /indexes/hotels/docs&api-version=2025-09-01
{
"search": "inn",
"scoringProfile": "geo",
"scoringParameters": ["currentLocation--122.123,44.77233"]
}
Abfrageparameter, einschließlich scoringParameters, werden in der REST-API (Search Documents) beschrieben.
Weitere Szenarien finden Sie in den Beispielen für die Themen Aktualität und Entfernung sowie gewichteten Text und Funktionen in diesem Artikel.
Hinzufügen eines Bewertungsprofils zu einem Suchindex
Beginnen Sie mit einer Indexdefinition. Sie können Bewertungsprofile für einen bestehenden Index hinzufügen und aktualisieren, ohne diesen neu erstellen zu müssen. Verwenden Sie eine Anforderung zum Erstellen oder Aktualisieren von Index , um eine Überarbeitung zu veröffentlichen.
Fügen Sie die in diesem Artikel bereitgestellte Vorlage ein.
Geben Sie einen Namen an, der den Benennungskonventionen entspricht.
Geben Sie die Relevanzkriterien an. Ein einzelnes Profil kann textgewichtete Felder, Funktionen oder beides enthalten.
Sie sollten iterativ arbeiten, indem Sie einen Datensatz verwenden, der Ihnen hilft, die Wirksamkeit eines bestimmten Profils zu beweisen oder zu widerlegen.
Bewertungsprofile können im Azure-Portal wie im folgenden Screenshot dargestellt oder programmgesteuert über REST-APIs oder in Azure SDKs definiert werden, z. B. die ScoringProfile-Klasse in .NET- oder Python-Clientbibliotheken.

Template
In diesem Abschnitt wird die Syntax und die Vorlage für die Bewertungsprofile veranschaulicht. Eine Beschreibung der Eigenschaften finden Sie in der REST-API-Referenz.
"scoringProfiles": [
{
"name": "name of scoring profile",
"text": (optional, only applies to searchable fields) {
"weights": {
"searchable_field_name": relative_weight_value (positive #'s),
...
}
},
"functions": (optional) [
{
"type": "magnitude | freshness | distance | tag",
"boost": # (positive or negative number used as multiplier for raw score != 1),
"fieldName": "(...)",
"interpolation": "constant | linear (default) | quadratic | logarithmic",
"magnitude": {
"boostingRangeStart": #,
"boostingRangeEnd": #,
"constantBoostBeyondRange": true | false (default)
}
// ( - or -)
"freshness": {
"boostingDuration": "..." (value representing timespan over which boosting occurs)
}
// ( - or -)
"distance": {
"referencePointParameter": "...", (parameter to be passed in queries to use as reference ___location)
"boostingDistance": # (the distance in kilometers from the reference ___location where the boosting range ends)
}
// ( - or -)
"tag": {
"tagsParameter": "..."(parameter to be passed in queries to specify a list of tags to compare against target field)
}
}
],
"functionAggregation": (optional, applies only when functions are specified) "sum (default) | average | minimum | maximum | firstMatching"
}
],
"defaultScoringProfile": (optional) "...",
Verwenden von textgewichteten Feldern
Verwenden Sie textgewichtete Felder, wenn der Feldkontext wichtig ist und Abfragen searchable-Zeichenfolgenfelder enthalten. Wenn z. B. eine Abfrage den Begriff "Airport" enthält, möchten Sie "Airport" im Feld "HotelName" anstelle des Felds "Beschreibung" verwenden.
Gewichtete Felder sind Name-Wert-Paare und bestehen aus einem searchable Feld und einer positiven Zahl, die als Multiplikator verwendet wird. Wenn der ursprüngliche Feldscore von HotelName 3 lautet, entspricht der höher gewichtete Score dieses Felds 6, was zu einem höheren Gesamtscore des übergeordneten Dokuments beiträgt.
"scoringProfiles": [
{
"name": "boostSearchTerms",
"text": {
"weights": {
"HotelName": 2,
"Description": 5
}
}
}
]
Verwenden von Funktionen
Verwenden Sie Funktionen, wenn einfache relative Gewichtungen nicht ausreichen oder sich nicht anwenden lassen. Dies ist z. B. bei „distance“ und „freshness“ der Fall, da es sich hier um Berechnungen für numerische Daten handelt. Sie können pro Bewertungsprofil mehrere Funktionen angeben. Weitere Informationen zu den in Azure AI Search verwendeten EDM-Datentypen finden Sie unter Unterstützte Datentypen.
| Function | Description | Anwendungsfälle |
|---|---|---|
| distance | Höhere Gewichtung auf Basis der Nähe oder des geografischen Standorts. Diese Funktion kann nur mit Edm.GeographyPoint -Feldern verwendet werden. |
Verwenden Sie diese Option für Szenarien für „In meiner Nähe suchen“. |
| freshness | Erhöht um Werte in einem datetime-Feld (Edm.DateTimeOffset).
Legen Sie boostDuration fest, um einen Wert anzugeben, der einen Zeitbereich darstellt, über den die Verstärkung erfolgt. |
Verwenden Sie diesen Vorgang, wenn Sie eine Verstärkung nach neueren oder älteren Datumsangaben ausführen möchten. Elemente wie z. B. Kalenderereignisse können mit in der Zukunft liegenden Daten so eingestuft werden, dass Ereignisse mit geringerem Abstand zur Gegenwart höher als Ereignisse eingestuft werden, die weiter in der Zukunft liegen. Ein Ende des Bereichs ist auf die aktuelle Uhrzeit festgelegt. Um eine Reihe von Zeiten in der Vergangenheit zu erhöhen, verwenden Sie eine positive BoostDuration. Wenn Sie einen Bereich von zukünftigen Zeitpunkten höher gewichten möchten, verwenden Sie einen negativen Wert für boostingDuration. |
| magnitude | Ändern Sie Rangfolgen basierend auf dem Wertebereich für ein numerisches Feld. Der Wert muss vom Typ „Integer“ oder „Gleitkomma“ sein. Für Sternbewertungen von 1 bis 4 wäre dies die 1. Für Gewinnspannen von über 50 % wäre dies die 50. Diese Funktion kann nur mit Edm.Double- und Edm.Int-Feldern verwendet werden. Für die magnitude-Funktion können Sie den Bereich umkehren, wenn Sie das umgekehrte Muster anwenden möchten (z. B. um preiswerteren Artikeln eine höhere Relevanz als teureren zuzuweisen). Legen Sie bei einer Preisspanne zwischen 100 € und 1 € boostingRangeStart auf 100 und boostingRangeEnd auf 1 fest, um preiswertere Artikeln zu fördern. |
Verwenden Sie diese Option, wenn Sie durch Gewinnspanne, Bewertungen, Clickthrough-Anzahl, Anzahl der Downloads, höchsten Preis, niedrigsten Preis oder eine Anzahl von Downloads steigern möchten. Wenn zwei Elemente relevant sind, wird das Element mit der höheren Bewertung zuerst angezeigt. |
| tag | Höhere Gewichtung auf Basis von Tags, die sowohl für Suchdokumente als auch für Abfragezeichenfolgen gebräuchlich sind. Tags werden als tagsParameter bereitgestellt. Diese Funktion kann nur mit Suchfeldern vom Typ Edm.String und Collection(Edm.String) verwendet werden. |
Verwenden Sie diese Funktion, wenn Sie Tagfelder haben. Wenn ein Tag in der Liste selbst eine durch Trennzeichen getrennte Liste ist, können Sie eine Textnormalisierungsfunktion in diesem Feld verwenden, um die Trennzeichen zur Abfragezeit zu entfernen (das Trennzeichen wird einem Leerzeichen zugeordnet). Damit wird die Liste vereinfacht und enthält alle Begriffe in einer einzigen, langen Zeichenfolge mit Trennzeichen. |
Die Größe ist der berechnete Abstand zwischen dem Wert eines Felds (z. B. einem Datum oder einer Position) und einem Bezugspunkt (z. B. "Jetzt" oder zielort). Dies ist die Eingabe für die Bewertungsfunktion und bestimmt, wie viel Boost angewendet wird.
Aktualitäts- und Entfernungsbewertungen sind spezielle Fälle einer größenbasierten Bewertung, bei der die Größe automatisch aus einem Datums- oder geografischen Feld berechnet wird. Verwenden Sie für eine intuitive Verstärkung, die neuere oder engere Werte über ältere oder weiter entfernte Werte fördert, einen negativen Boostwert (weitere Details finden Sie im Beispiel ).
Regeln für die Verwendung von Funktionen
- Funktionen können nur auf Felder angewendet werden, die als
filterableattribuiert sind. - Der Funktionstyp ("freshness", "magnitude", "distance", "tag") muss in Kleinbuchstaben angegeben werden.
- Funktionen dürfen keine NULL-Werte oder leeren Werte enthalten.
- Funktionen können nur ein einzelnes Feld pro Funktionsdefinition aufweisen. Um „magnitude“ zweimal im selben Profil zu verwenden, stellen Sie zwei Definitionen für jedes Feld bereit.
Festlegen von Interpolationen
Interpolationen legen die Form des Gradienten fest, der zur Steigerung der Frische und der Distanz verwendet wird.
Wenn der Boostwert positiv ist, ist die Bewertung von hoch nach niedrig, und die Steigung ist stets abnehmend. Mit negativen Boosts nimmt die Steigung zu (neuere Dokumente erhalten höhere Punktzahlen). Die Interpolationswerte bestimmen die Kurve des Anstiegs oder des Gefälles und wie stark sich die Verstärkungsbewertung als Reaktion auf Änderungen des Datums oder der Entfernung ändert. Die folgenden Interpolationen können verwendet werden:
| Interpolation | Description |
|---|---|
linear |
Bei Elementen, die sich innerhalb des maximalen und minimalen Bereichs befinden, wird die Verstärkung in einer ständig abnehmenden Menge angewendet. Eine negative Verstärkung bestraft ältere Dokumente proportional. Gut für eine schrittweise Abnahme der Relevanz. "Linear" ist die Standardinterpolation für ein Bewertungsprofil. |
constant |
Für Elemente, die sich innerhalb des Anfangs- und Endbereichs befinden, wird eine konstante Verstärkung auf die Rangfolgeergebnisse angewendet. Bei Aktualität und Distanz wird dieselbe negative Verstärkung auf alle Dokumente innerhalb des Bereichs angewendet. Verwenden Sie dies, wenn Sie unabhängig vom Alter eine Pauschalstrafe wünschen. |
quadratic |
„quadratisch“ nimmt zunächst langsamer und dann beim Annähern an den Endbereich in viel größeren Intervallen ab. Bei der negativen Verstärkung werden ältere Dokumente mit zunehmendem Alter immer stärker bestraft. Verwenden Sie diese Vorgehensweise, wenn Sie die aktuellsten Dokumente stark bevorzugen und ältere dokumente deutlich tieferstufen möchten. Diese Interpolationsoption ist in der Kategoriebewertungsfunktion nicht zulässig. |
logarithmic |
„logarithmisch“ nimmt zunächst schneller und dann beim Annähern an den Endbereich in viel kleineren Intervallen ab. Bei negativer Verstärkung werden ältere Dokumente zunächst stärker und dann immer weniger bestraft. Ideal, wenn Sie eine starke Vorliebe für sehr aktuelle Inhalte wünschen, aber weniger Empfindlichkeit bei der Alterung von Dokumenten. Diese Interpolationsoption ist in der Kategoriebewertungsfunktion nicht zulässig. |
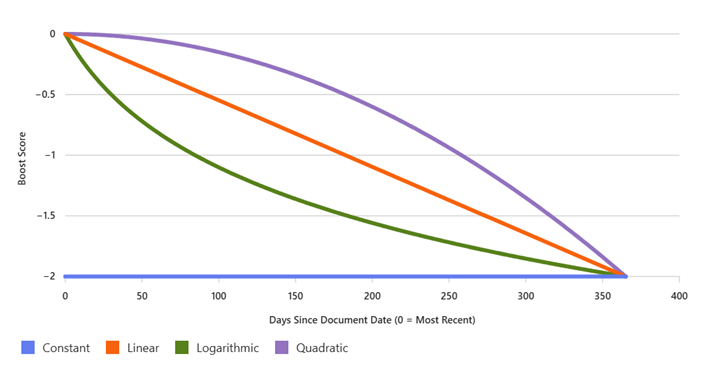
Festlegen von „boostDuration“ für die Aktualitätsfunktion
boostingDuration ist ein Attribut der Funktion freshness. Sie verwenden es, um einen Ablaufzeitraum festzulegen, danach wird die Promotion für ein bestimmtes Dokument beendet. Um beispielsweise eine Produktlinie oder Marke für einen zehntägigen Werbezeitraum zu verstärken, können Sie den zehntägigen Zeitraum für diese Dokumente z. B. als "P10D" angeben.
boostingDuration muss als XSD-Wert "dayTimeDuration" formatiert sein (eine eingeschränkte Teilmenge eines ISO 8601-Zeitdauerwerts). Das Muster hierfür lautet: „P[nD][T[nH][nM][nS]]“.
Die folgende Tabelle enthält einige Beispiele.
| Duration | boostingDuration |
|---|---|
| 1 Tag | "P1D" |
| 2 Tage und 12 Stunden | "P2DT12H" |
| 15 Minuten | "PT15M" |
| 30 Tage, 5 Stunden, 10 Minuten und 6,334 Sekunden | "P30DT5H10M6.334S" |
| 1 Jahr | "365D" |
Weitere Beispiele finden Sie unter XML-Schema: Datentypen (W3.org-Website).
Beispiel: Verstärkung durch Frische oder Entfernung
In Azure AI Search konvertiert die Aktualitätsbewertung Datum und Werte in eine numerische Größe – eine einzelne Zahl, die angibt, wie weit das Datum eines Dokuments von der aktuellen Uhrzeit stammt. Je älter das Datum ist, desto größer ist die Größe. Dies führt zu einem kontraintuitiven Verhalten: Neuere Dokumente haben kleinere Größenordnungen, was bedeutet, dass positive Verstärkungsfaktoren ältere Dokumente bevorzugen, es sei denn, die Richtung der Verstärkung wird explizit umgekehrt.
Diese Logik gilt auch für die Entfernungserhöhung, bei der weiter entfernte Standorte größere Größen erzielen.
Um die Aktualität oder Distanz zu erhöhen, verwenden Sie negative Verstärkungswerte, um neuere Datumsangaben oder näher gelegene Orte zu priorisieren. Durch die Umkehrung der Verstärkungsrichtung durch einen negativen Verstärkungsfaktor werden größere Magnituden (ältere Datumsangaben) bestraft, wodurch aktuellere effektiv verstärkt werden. Gehen Sie beispielsweise von einer Booster-Funktion wie b * (1 - x) aus (wobei x der normalisierte Betrag von 0 bis 1 ist), die kleineren Beträgen (das heißt neueren Datumsangaben) höhere Bewertungen zuweist.
Die Form der Verstärkungskurve (konstant, linear, logarithmisch, quadratisch) beeinflusst, wie stark sich die Werte im gesamten Bereich ändern. Mit einem negativen Faktor kippt das Verhalten der Kurve – z. B. eine quadratische Kurve tippt bei älteren Datumsangaben langsamer ab, während sich eine logarithmische Kurve am weit entfernten Ende stärker verschiebt.
Im Folgenden finden Sie ein Beispiel für ein Bewertungsprofil, das veranschaulicht, wie die nicht intuitive Aktualitätsbewertung mithilfe negativer Verstärkung behandelt wird. Außerdem wird erläutert, wie die Magnitude in diesem Kontext funktioniert.
"scoringProfiles": [
{
"name": "freshnessBoost",
"text": {
"weights": {
"content": 1.0
}
},
"functions": [
{
"type": "freshness",
"fieldName": "lastUpdated",
"boost": -2.0,
"interpolation": "quadratic",
"parameters": {
"boostingDuration": "365D"
}
}
]
}
]
-
"fieldName": "lastUpdated"ist das Datetime-Feld, das zum Berechnen der Aktualität verwendet wird. -
"boost": -2.0ist ein negativer Verstärkungsfaktor, der das Standardverhalten umkehrt. Da ältere Daten größere Magnituden haben, werden sie bestraft und neuere Dokumente gefördert. -
"interpolation": "quadratic"bedeutet, dass der Verstärkungseffekt für Dokumente, die näher am aktuellen Datum sind, stärker ist und für ältere Dokumente stärker nachlässt. -
"boostingDuration": "365D"definiert das Zeitfenster, über das die Aktualität ausgewertet wird.
Beispiel: Verstärken durch gewichteten Text und Funktionen
Tip
In diesem Blogbeitrag und in diesem Notizbuch finden Sie eine Demonstration der Verwendung von Bewertungsprofilen und Dokumentsteigerungen in Vektor- und generativen KI-Szenarien.
Im folgenden Beispiel wird das Schema eines Indexes mit zwei Bewertungsprofilen (boostGenre, newAndHighlyRated) gezeigt. Jede Abfrage für diesen Index, die eines der beiden Profile als Abfrageparameter enthält, verwendet das Profil, um das Ergebnis-Set zu bewerten.
Das Profil boostGenre verwendet gewichtete Textfelder und fördert Übereinstimmungen, die in den Feldern „albumTitle“, „genre“ und „interpretName“ gefunden werden. Die Felder werden jeweils um den Faktor 1,5, 5 und 2 höher gewichtet. Warum wird "genre" so viel stärker als die anderen Felder erhöht? Wenn die Suche über Daten durchgeführt wird, die etwas homogen sind (wie bei "genre" im musicstoreindex), benötigen Sie möglicherweise eine größere Varianz in den relativen Gewichtungen. In musicstoreindex ist „rock“ z. B. sowohl als „genre“ als auch in identisch formulierten Genrebeschreibungen aufgeführt. Wenn das Genre die Genrebeschreibung überwiegen soll, muss das Genrefeld ein viel höheres relatives Gewicht haben.
{
"name": "musicstoreindex",
"fields": [
{ "name": "key", "type": "Edm.String", "key": true },
{ "name": "albumTitle", "type": "Edm.String" },
{ "name": "albumUrl", "type": "Edm.String", "filterable": false },
{ "name": "genre", "type": "Edm.String" },
{ "name": "genreDescription", "type": "Edm.String", "filterable": false },
{ "name": "artistName", "type": "Edm.String" },
{ "name": "orderableOnline", "type": "Edm.Boolean" },
{ "name": "rating", "type": "Edm.Int32" },
{ "name": "tags", "type": "Collection(Edm.String)" },
{ "name": "price", "type": "Edm.Double", "filterable": false },
{ "name": "margin", "type": "Edm.Int32", "retrievable": false },
{ "name": "inventory", "type": "Edm.Int32" },
{ "name": "lastUpdated", "type": "Edm.DateTimeOffset" }
],
"scoringProfiles": [
{
"name": "boostGenre",
"text": {
"weights": {
"albumTitle": 1.5,
"genre": 5,
"artistName": 2
}
}
},
{
"name": "newAndHighlyRated",
"functions": [
{
"type": "freshness",
"fieldName": "lastUpdated",
"boost": -10,
"interpolation": "quadratic",
"freshness": {
"boostingDuration": "P365D"
}
},
{
"type": "magnitude",
"fieldName": "rating",
"boost": 10,
"interpolation": "linear",
"magnitude": {
"boostingRangeStart": 1,
"boostingRangeEnd": 5,
"constantBoostBeyondRange": false
}
}
]
}
]
}