機械学習モデルのトレーニングは、反復的なプロセスであり、多くの実験が必要です。 Azure Machine Learning の対話型ジョブ エクスペリエンスを使用すると、データ サイエンティストは Azure Machine Learning Python SDK、Azure Machine Learning CLI、または Azure Studio を使用して、ジョブが実行されているコンテナーにアクセスできます。 ジョブ コンテナーにアクセスしたら、ユーザーは、ローカル コンピューターで通常実行するのと同様に、トレーニング スクリプトを反復処理したり、トレーニングの進行状況を監視したり、リモートでジョブをデバッグしたりすることができます。 ジョブとは、JupyterLab、TensorBoard、VS Code などのさまざまなトレーニング アプリケーションを介して、または SSH 経由でジョブ コンテナーに直接接続することで対話できます。
対話型トレーニングは、Azure Machine Learning コンピューティング クラスター と Azure Arc 対応 Kubernetes クラスターでサポートされています。
前提条件
- Azure Machine Learning でのトレーニングの開始に関するページを確認します。
- 詳細については、Azure Machine Learning 拡張機能を設定するための VS Code のこのリンクを参照してください。
- ジョブ環境に
openssh-server および ipykernel ~=6.0 パッケージがインストールされていることを確認します (すべての Azure Machine Learning のキュレーション済みトレーニング環境には、これらのパッケージが既定でインストールされています)。
- 分散の種類が PyTorch、TensorFlow、MPI 以外である分散トレーニングの実行では、対話型アプリケーションを有効にすることはできません。 カスタム分散トレーニングのセットアップ (上記の分散フレームワークを使用しないマルチノード トレーニングの構成) は現在サポートされていません。
- SSH を使用するには、SSH キーの組が必要です。
ssh-keygen -f "<filepath>" コマンドを使用して、公開キーと秘密キーの組を生成できます。
ジョブ コンテナーと対話する
ジョブの作成時に対話型アプリケーションを指定すると、ジョブが実行されているコンピューティング ノード上のコンテナーに直接接続できます。 ジョブ コンテナーにアクセスしたら、実行するのとまったく同じ環境でジョブをテストまたはデバッグできます。 ローカルの場合と同様、VS Code を使用して、実行中のプロセスにアタッチし、デバッグすることもできます。
ジョブの送信中に有効にする
スタジオ ポータルの左側のウィンドウから新しいジョブを作成します。
コンピューティングの種類としてコンピューティング クラスターまたはアタッチ型コンピューティング (Kubernetes) を選択し、コンピューティング ターゲットを選択し、Instance count で必要なノード数を指定します。
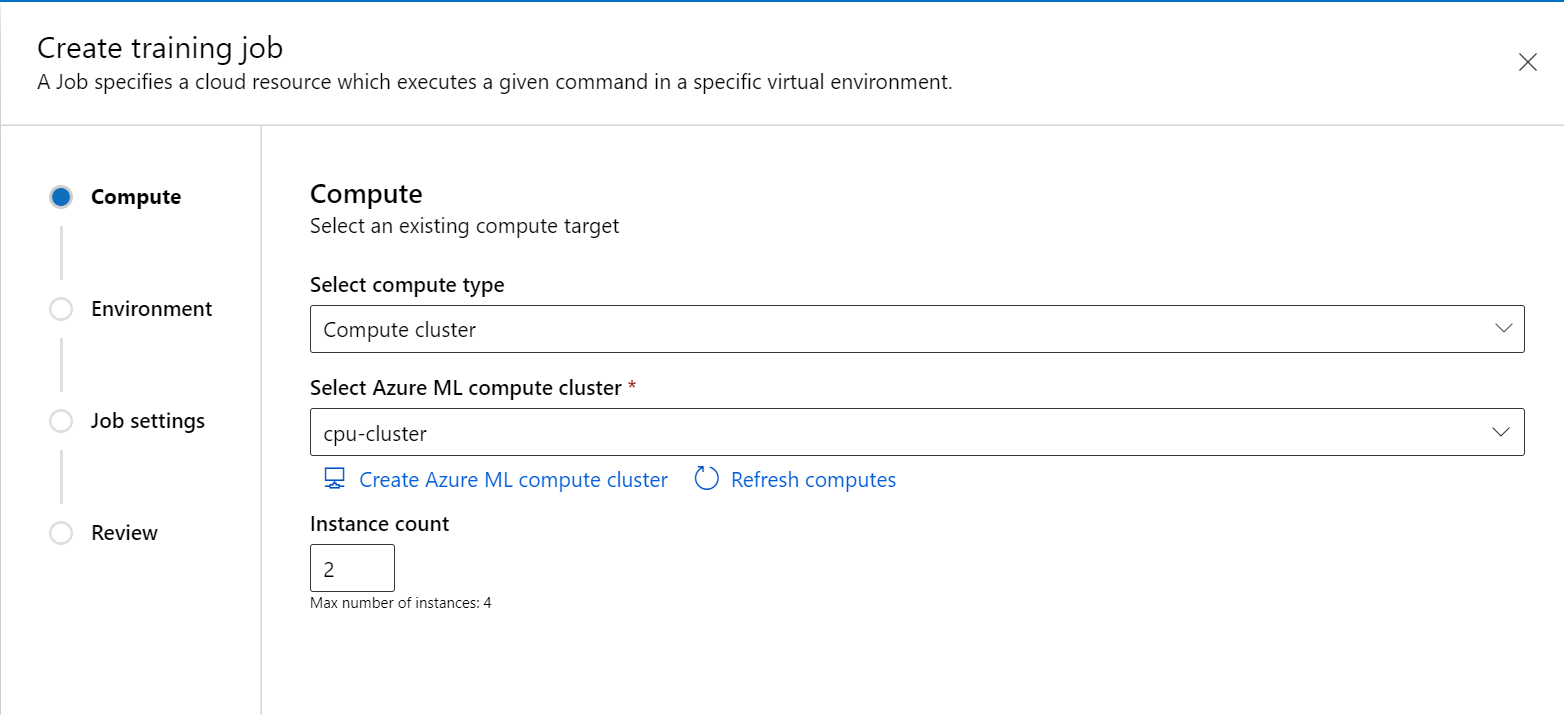
ウィザードに従って、ジョブを開始する環境を選択します。
トレーニング スクリプト手順で、トレーニング コード (および入出力データ) を追加し、それをコマンド内で参照して、それがジョブにマウントされていることを確認します。
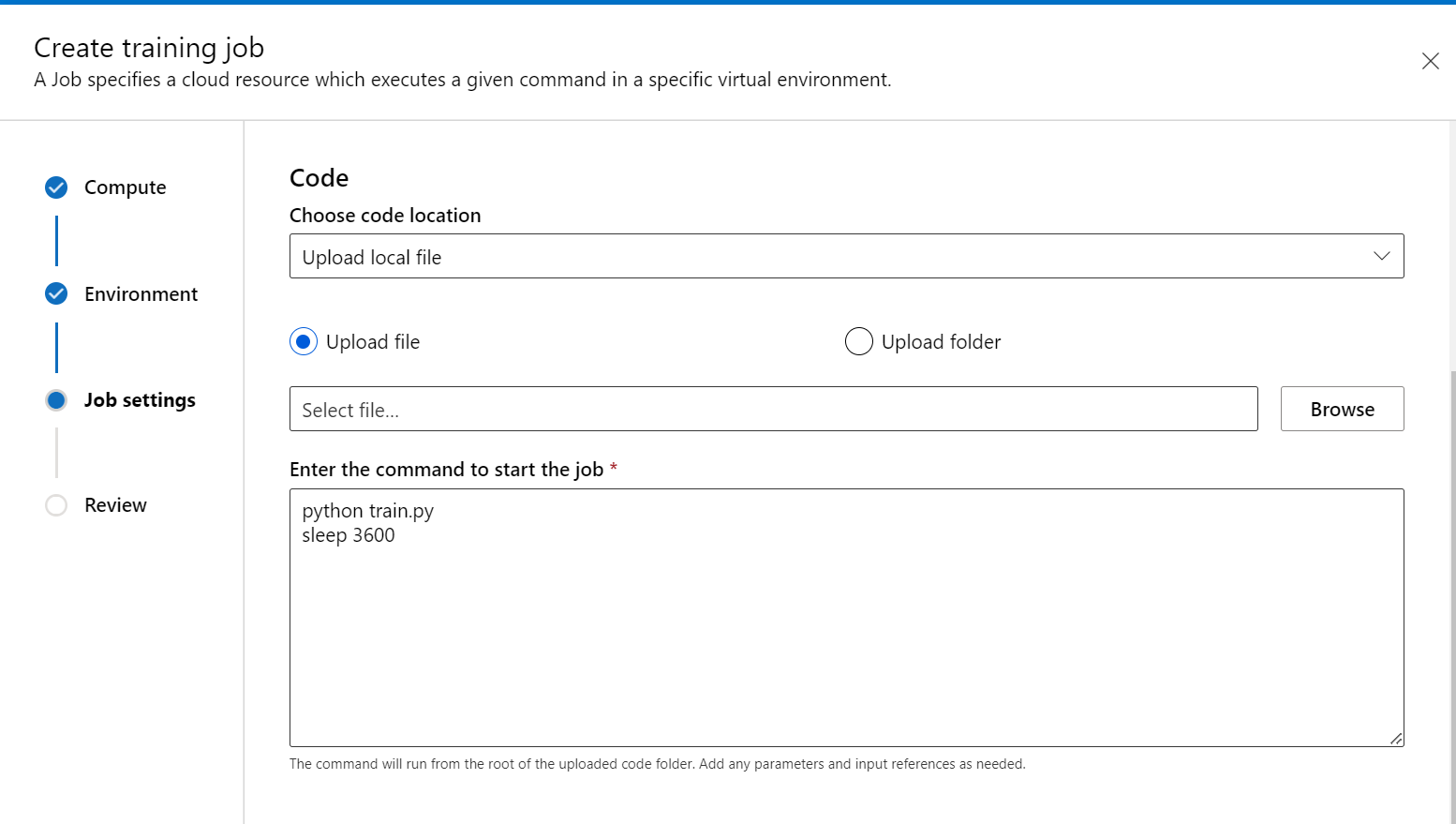
コマンドの最後に sleep <specific time> を配置して、コンピューティング リソースを予約する時間を指定できます。 形式は次のとおりです。
- sleep 1s
- sleep 1m
- sleep 1h
- sleep 1d
また、ジョブを無期限に維持する sleep infinity コマンドを使用することもできます。
注意
sleep infinity を使用する場合、コンピューティング リソースを解放 (および課金を停止) するには、手動でジョブをキャンセルする必要があります。
- [コンピューティング] 設定で、[アプリケーションのトレーニング] のオプションを展開します。 ジョブとの対話に使用するトレーニング アプリケーションを少なくても 1 つ選択します。 アプリケーションを選択しないと、デバッグ機能は使用できません。

- ジョブを確認して作成します。
ジョブに使用する対話型サービスを定義します。 必ず your compute name を独自の値に置き換えてください。 独自のカスタム環境を使用する場合は、このチュートリアルの例に従ってカスタム環境を作成します。
SDK を介して対話型サービスを構成するには、JobService クラスを azure.ai.ml.entities パッケージからインポートする必要があります。
command_job = command(...
code="./src", # local path where the code is stored
command="python main.py", # you can add a command like "sleep 1h" to reserve the compute resource is reserved after the script finishes running
environment="AzureML-tensorflow-2.7-ubuntu20.04-py38-cuda11-gpu@latest",
compute="<name-of-compute>",
services={
"My_jupyterlab": JupyterLabJobService(
nodes="all" # For distributed jobs, use the `nodes` property to pick which node you want to enable interactive services on. If `nodes` are not selected, by default, interactive applications are only enabled on the head node. Values are "all", or compute node index (for ex. "0", "1" etc.)
),
"My_vscode": VsCodeJobService(
nodes="all"
),
"My_tensorboard": TensorBoardJobService(
nodes="all",
log_dir="output/tblogs" # relative path of Tensorboard logs (same as in your training script)
),
"My_ssh": SshJobService(
ssh_public_keys="<add-public-key>",
nodes="all"
),
}
)
# submit the command
returned_job = ml_client.jobs.create_or_update(command_job)
services セクションでは、対話するトレーニング アプリケーションを指定します。
コマンドの最後に sleep <specific time> を配置して、コンピューティング リソースを予約する時間を指定できます。 形式は次のとおりです。
- sleep 1s
- sleep 1m
- 1時間眠る
- sleep 1d
また、ジョブを無期限に維持する sleep infinity コマンドを使用することもできます。
注意
sleep infinity を使用する場合、コンピューティング リソースを解放 (および課金を停止) するには、手動でジョブをキャンセルする必要があります。
トレーニング ジョブを送信します。 Python SDK を使用してトレーニングを行う方法の詳細については、こちらの記事を確認してください。
サンプル コンテンツを使用してジョブ YAML job.yaml を作成します。 必ず your compute name を独自の値に置き換えてください。 カスタム環境を使用する場合は、このチュートリアルの例に従ってカスタム環境を作成します。
code: src
command:
python train.py
# you can add a command like "sleep 1h" to reserve the compute resource is reserved after the script finishes running.
environment: azureml:AzureML-tensorflow-2.4-ubuntu18.04-py37-cuda11-gpu:41
compute: azureml:<your compute name>
services:
my_vs_code:
type: vs_code
nodes: all # For distributed jobs, use the `nodes` property to pick which node you want to enable interactive services on. If `nodes` are not selected, by default, interactive applications are only enabled on the head node. Values are "all", or compute node index (for ex. "0", "1" etc.)
my_tensor_board:
type: tensor_board
log_dir: "output/tblogs" # relative path of Tensorboard logs (same as in your training script)
nodes: all
my_jupyter_lab:
type: jupyter_lab
nodes: all
my_ssh:
type: ssh
ssh_public_keys: <paste the entire pub key content>
nodes: all
services セクションでは、対話するトレーニング アプリケーションを指定します。
コマンドの最後に sleep <specific time> を配置して、コンピューティング リソースを予約する時間を指定できます。 形式は次のとおりです。
- sleep 1s
- sleep 1m
- スリープ 1時間
- sleep 1d
また、ジョブを無期限に維持する sleep infinity コマンドを使用することもできます。
注意
sleep infinity を使用する場合、コンピューティング リソースを解放 (および課金を停止) するには、手動でジョブをキャンセルする必要があります。
コマンド az ml job create --file <path to your job yaml file> --workspace-name <your workspace name> --resource-group <your resource group name> --subscription <sub-id> を実行してトレーニング ジョブを送信します。 CLI を介したジョブの実行の詳細については、こちらの記事を確認してください。
エンドポイントに接続する
実行中のジョブと対話するには、ジョブの詳細ページで [デバッグと監視] ボタンを選択します。
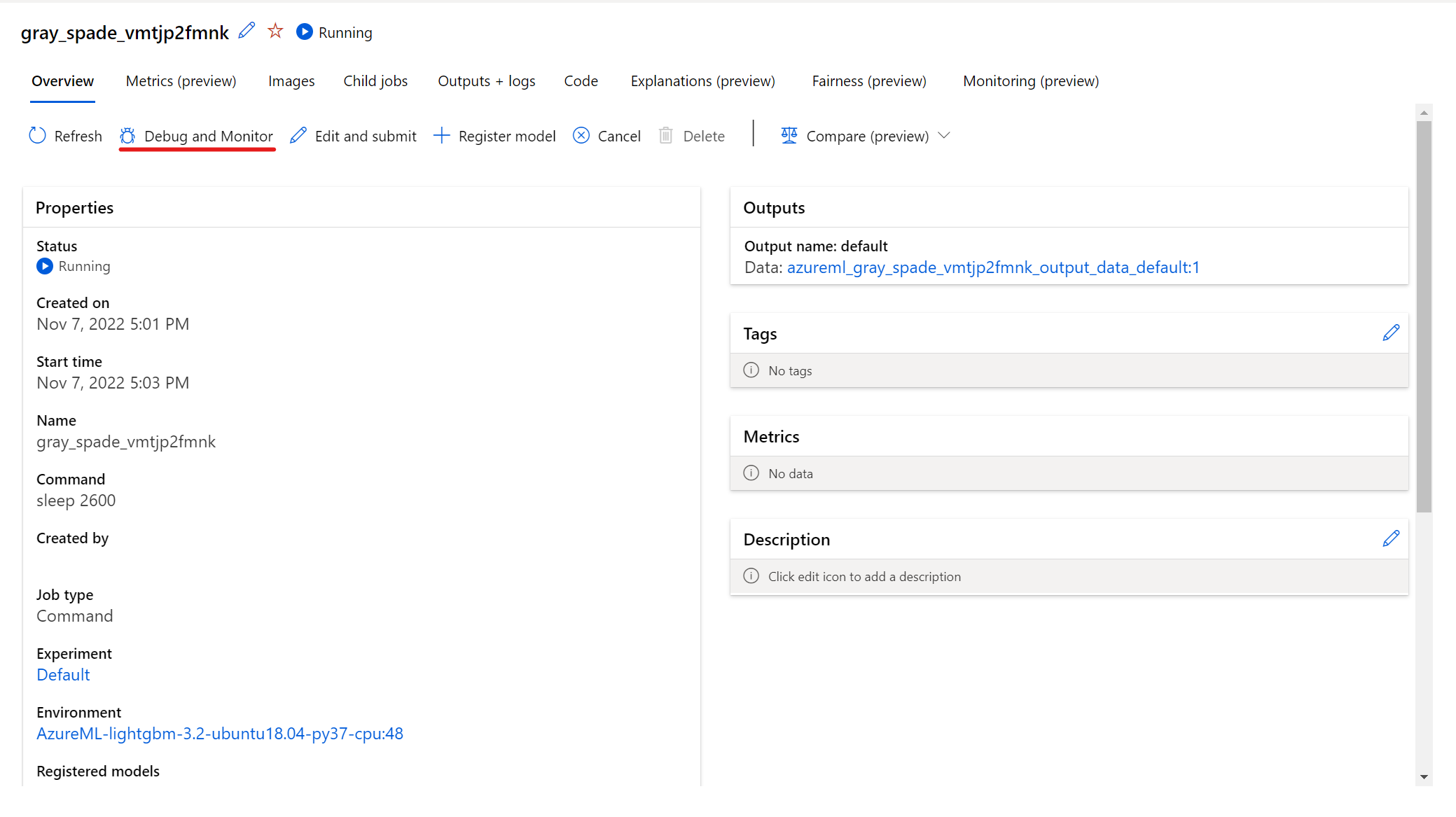
パネルでアプリケーションをクリックすると、アプリケーションの新しいタブが開きます。 アプリケーションにアクセスできるのは、アプリケーションが実行中の状態で、ジョブ所有者のみがアプリケーションへのアクセスを認可されている場合のみです。 複数のノードでトレーニングしている場合は、対話する特定のノードを選択できます。

ジョブおよびジョブの作成時に指定したトレーニング アプリケーションを開始するのに数分かかる場合があります。
ジョブが送信されたら、ml_client.jobs.show_services("<job name>", <compute node index>) を使用して対話型サービス エンドポイントを表示できます。
ジョブが実行されているコンテナーに SSH 経由で接続するには、コマンド az ml job connect-ssh --name <job-name> --node-index <compute node index> --private-key-file-path <path to private key> を実行します。 Azure Machine Learning CLI を設定するには、このガイドに従います。
SDK のリファレンス ドキュメントは、こちらで確認できます。
アプリケーションにアクセスできるのは、アプリケーションが実行中の状態で、ジョブ所有者のみがアプリケーションへのアクセスを認可されている場合のみです。 複数のノードでトレーニングしている場合は、ノード インデックスを渡して、対話する特定のノードを選択できます。
ジョブが実行中の場合は、az ml job show-services --name <job name> --node-index <compute node index> コマンドを実行して、アプリケーションの URL を取得します。 エンドポイント URL は、出力の services で表示されます。 VS Code では、ブラウザーで指定された URL をコピーして貼り付ける必要があります。
ジョブが実行されているコンテナーに SSH 経由で接続するには、コマンド az ml job connect-ssh --name <job-name> --node-index <compute node index> --private-key-file-path <path to private key> を実行します。
これらのコマンドのリファレンス ドキュメントについては、こちらを参照してください。
アプリケーションにアクセスできるのは、アプリケーションが実行中の状態で、ジョブ所有者のみがアプリケーションへのアクセスを認可されている場合のみです。 複数のノードでトレーニングしている場合は、ノード インデックスを渡して、対話する特定のノードを選択できます。
アプリケーションと対話する
ジョブと対話するためのエンドポイントを選択すると、作業ディレクトリの下のユーザー コンテナーに移動します。ここでは、コード、入力、出力、ログにアクセスできます。 アプリケーションへの接続中に問題が発生した場合、対話型の機能とアプリケーションのログは、> タブの system_logs-interactive_capability にあります。
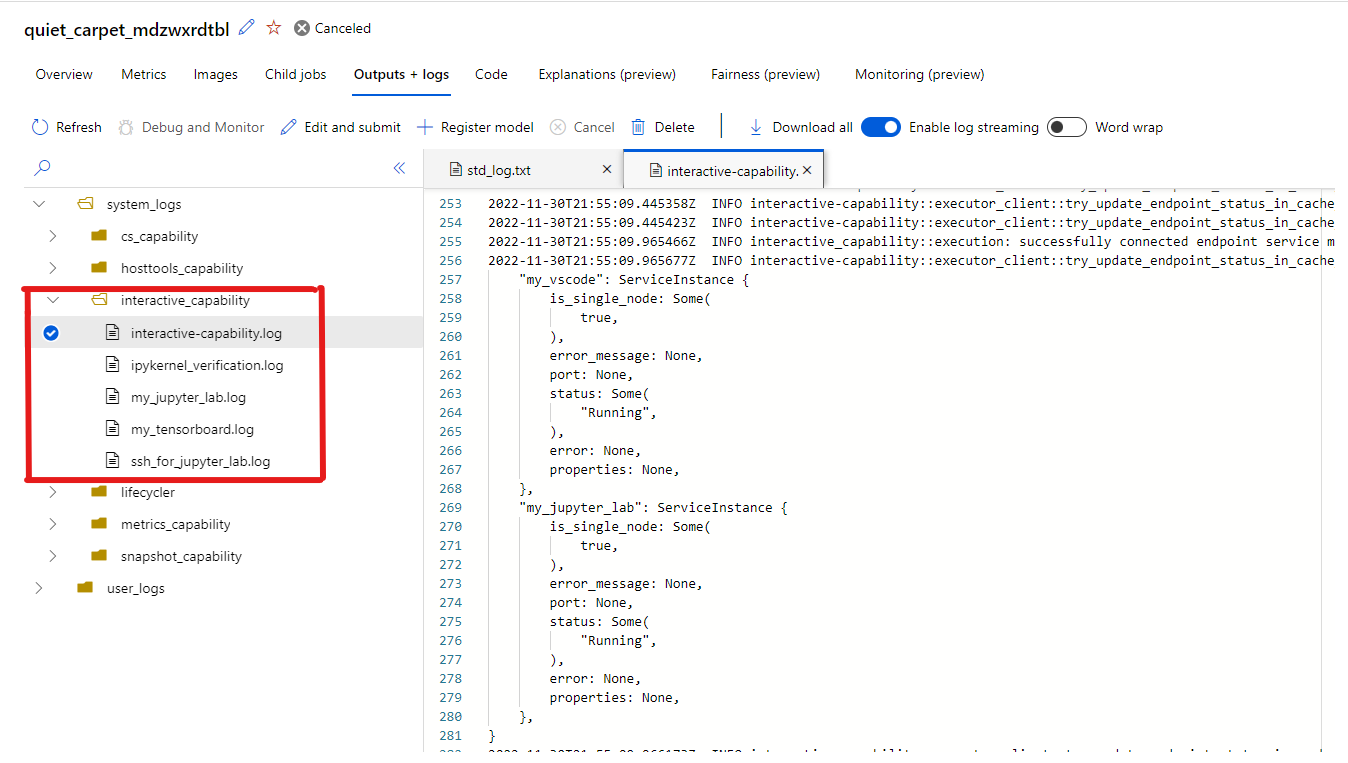
Jupyter Lab からターミナルを開き、ジョブ コンテナー内での対話を開始できます。 Jupyter Lab を使用してトレーニング スクリプトを直接反復処理することもできます。

VS Code 内でジョブ コンテナーと対話することもできます。 ジョブの送信中にデバッガーをジョブにアタッチし、実行を一時停止するには、こちらに移動します。
注意
VS Code を使用してジョブ コンテナーを操作する場合、プライベート リンクが有効なワークスペースは現在サポートされません。

ジョブの tensorflow イベントをログに記録した場合は、TensorBoard を使用して、ジョブの実行中にメトリックを監視できます。

ジョブを終了する
対話型トレーニングが完了したら、ジョブの詳細ページにアクセスしてジョブをキャンセルすることもできます。これによってコンピューティング リソースが解放されます。 または、CLI で az ml job cancel -n <your job name>、SDK で ml_client.job.cancel("<job name>") を使用します。

デバッガーをジョブにアタッチする
デバッガーがアタッチされ、実行が一時停止された状態のジョブを送信するには、debugpy と VS Code を使用できます (debugpy がジョブ環境にインストールされている必要があります)。
注意
VS Code でジョブにデバッガーをアタッチする場合、プライベート リンクが有効なワークスペースは現在サポートされません。
- (UI、CLI、SDK のいずれかを介した) ジョブの送信中に、debugpy コマンドを使用して Python スクリプトを実行します。 たとえば、次のスクリーンショットは、debugpy を使用して tensorflow スクリプトのデバッガーをアタッチするサンプル コマンドを示しています (
tfevents.py はトレーニング スクリプトの名前に置き換えることができます)。

ジョブの送信が完了したら、VS Code に接続し、組み込みのデバッガーを選択します。
"リモートアタッチ" デバッグ構成を使用して、送信されたジョブにアタッチし、ジョブ送信コマンドで構成したパスとポートを渡します。 この情報は、ジョブの詳細ページでも確認できます。

![対話型ジョブの [リモートアタッチの追加] ボタンのスクリーンショット](media/interactive-jobs/remote-attach.png?view=azureml-api-2)
ブレークポイントを設定し、ローカル デバッグ ワークフローの場合と同様にジョブの実行をウォーク スルーします。

注意
debugpy を使用してジョブを開始する場合、VS Code でデバッガーをアタッチしてスクリプトを実行しない限り、ジョブは実行されません。 これを行わない場合、ジョブがキャンセルされるまで、コンピューティングは予約されます。
次のステップ